MCPとエージェント連携クックブック|始め方と選び方
MCPとエージェント連携クックブック|始め方と選び方
『MCP』を触り始めると、まず迷うのが「どこまでがツール連携で、どこからがエージェント連携なのか」という境界です。本記事は、『MCP』のホスト・クライアント・サーバーという基本構造とA2Aとの役割分担を先に整理し、
『MCP』を触り始めると、まず迷うのが「どこまでがツール連携で、どこからがエージェント連携なのか」という境界です。
本記事は、『MCP』のホスト・クライアント・サーバーという基本構造とA2Aとの役割分担を先に整理し、『Claude Code』『Cursor』VS Codeのような実装先で構成を迷わず選びたい人に向けて書いています。
開発環境で stdio と Streamable HTTP を切り替えて試した際の筆者の経験では、ローカル開発だと stdio の起動が速く手軽に感じられることが多かった一方、共有環境や本番環境では認証や接続管理、ネットワーク条件の影響で Streamable HTTP の方が安定する場合がありました。
なお、AWS Pricing を用いた会話中の即時概算取得が可能だったのは、筆者が事前に AWS の認証情報を正しく設定し、サーバー側でリクエスト集約やキャッシュなどの前処理を用意していた環境での事例です。
これらは環境依存の観察であり、同様の結果を得るためには認証設定やサーバー側の整備、ネットワーク要件の確認が必要になります。
MCPのアーキテクチャ概要やロードマップで見えてくるのは、MCPが2024年11月の導入から、2025-11-25版仕様へと至る流れです。
さらに2026年の enterprise readiness や governance まで一気通貫で整備されてきたという流れも確認できます。
この記事では、その全体像を押さえたうえで、今日から動かせる3つのクックブックと、PoCで止めない最小権限・認証・監査ログの運用設計まで一つの地図にまとめます。
MCPとエージェント連携の全体像

MCPの定義と導入年
『MCP』はModel Context Protocolの略で、LLMやAIアプリと、外部ツール・データソース・ファイル・APIをつなぐためのオープン標準です。
2024年11月にAnthropicが導入した枠組みとして広まり、その後は仕様とSDKが整備され、いまでは単なる個社機能ではなく、ツール連携の共通インターフェースとして理解するのが適切です。
アプリ側とツール側が同じ作法で会話できるようにすることにあります。
『MCP』が「AI用のUSB-C」と呼ばれるのは、この共通化の範囲が広いからです。
単にAPIを叩けるという話ではなく、どんな機能があるかを列挙し、必要な認証を通し、呼び出し方をそろえ、結果の返し方まで標準化します。
USB-Cケーブルを挿せば充電器やモニターの種類ごとに別の形を覚えなくてよいのと同じで、『MCP』では『Claude Code』『Cursor』VS Codeのようなホストが、サーバーごとの独自接続手順を減らしながらツールを増やせます。
実際に公開MCPサーバーを既存クライアントへ1つ足すと、なく体験として腑に落ちます。
設定を通した直後から、プロンプトで自然言語のまま選べる操作が増え、「この会話の中で何ができるのか」が目に見える形で立ち上がるからです。
会話が回答中心から操作中心へ広がる感覚は、API連携を個別実装していた時期とは別物でした。
GitHub - modelcontextprotocol/python-sdk: The official Python SDK for Model Context Protocol servers and clients
The official Python SDK for Model Context Protocol servers and clients - modelcontextprotocol/python-sdk
github.comホスト・クライアント・サーバーの役割
『MCP』の全体像を理解するうえで、まず押さえたいのがホスト・クライアント・サーバーの三役です。
ここを曖昧にすると、どこに設定を書き、どこで権限を持ち、どこが実際に処理を行っているのかが見えなくなります。
ホストは、エージェントが動作する実行環境やアプリ本体です。
『Claude Code』『Cursor』VS Codeのエージェント機能は、このホストに当たります。
ユーザーが会話し、モデルが判断し、どのツールを使うかを決める舞台がホストです。
クライアントは、ホストの内部にあるMCPクライアント実装です。
サーバーへ接続し、利用可能なツールやリソースを問い合わせ、実際の呼び出しをJSON-RPCでやり取りする役目です。
ユーザーが直接触るUIではなく、ホストの中で標準プロトコルをしゃべる部品だと捉えると整理しやすくなります。
サーバーは、ツール・リソース・プロンプトを提供する側です。
たとえば社内ドキュメント検索、ファイル操作、チケット起票、価格照会、データベース参照のような機能を外部に公開し、MCP経由で呼べるようにします。
AIが直接サーバーを書くのではなく、サーバーが「何を提供できるか」を明示し、クライアントがそれを見つけて使う構図です。
この分担を実務の感覚で言い換えると、ホストが作業机、クライアントが共通コネクタ、サーバーが道具箱です。
公開MCPサーバーを1つ追加しただけでツール一覧が増えるのは、ホスト自体が賢くなったというより、クライアントが新しい道具箱を接続して中身を列挙できるようになるからです。
UI上の追加手順は『Claude Code』『Cursor』VS Codeで少しずつ異なりますが、接続後に使えるアクションが会話の中へ流れ込んでくる感覚は共通しています。
RAG/Function Callingとの違い

『MCP』を理解するときに混同されやすいのが、RAGとFunction Callingです。
3つとも「モデルの外にあるものを使う」仕組みですが、守備範囲が違います。
RAGは、外部知識を検索して回答品質を上げる発想が中心です。
検索基盤やベクトルDBから関連文書を取り出し、その内容を踏まえてモデルが答えます。
強いのは知識の補強であり、主戦場は「何を知っているか」です。
Google CloudのMCP解説でも、この点は明確で、『MCP』はRAGより広く、情報取得だけでなくツール実行まで含むと整理されています。
一方の『MCP』は、情報参照に加えて外部でアクションを実行するところまで扱います。
文書を読むだけでなく、ファイルを作る、チケットを切る、価格を引く、システム状態を確認するといった行為が含まれます。
1分で説明するなら、「RAGは答えるための知識補給、『MCP』は答えるだけでなく外の道具を使って仕事を進めるための接続標準」です。
Function Callingは、モデルに呼び出し可能な関数定義を渡し、どの関数をどの引数で使うかを選ばせる仕組みです。
単体アプリに少数の関数を埋め込む用途では相性がよく、実装も比較的まっすぐです。
ただ、ツール数が増えたり、複数クライアントで再利用したくなったりすると、関数定義や認証まわりをアプリごとに抱える構成が重くなります。
『MCP』はそこを標準化し、サーバー側にツールやリソースを寄せて再利用しやすくしたものと見ると違いがつかみやすくなります。
要するに、RAGは検索中心、Function Callingはアプリ内関数呼び出し中心、『MCP』はツール・データ・操作をまたいで接続を標準化する層です。
エージェント連携の文脈で『MCP』が主役になるのは、回答の精度だけでなく、実行可能な操作をどう増やすかまで視野に入るからです。
JSON-RPC 2.0と呼び出しシーケンスの要点
『MCP』のデータ層はJSON-RPC 2.0ベースです。
つまり、クライアントとサーバーは「このメソッドを、この引数で呼ぶ」という形のメッセージをJSONでやり取りします。
HTTP APIのように見える場面があっても、やり取りの核にあるのはJSON-RPCのリクエストとレスポンスです。
流れを最小限まで縮めると、まずクライアントがサーバーへ接続し、どんなツールやリソースが公開されているかを取得します。
次にホスト上のモデルが、その一覧と会話文脈を踏まえて使うツールを選びます。
クライアントは選ばれたツールをサーバーへ実行要求し、サーバーは結果を返します。
その結果が再びモデルへ渡り、応答生成や次のアクション判断に使われます。
簡易シーケンスにすると、次の4段階です。
- クライアントがサーバーに接続して、利用可能なツールを列挙する
- ホスト上のモデルが、ユーザーの依頼に合うツールを選ぶ
- クライアントがJSON-RPC 2.0でツール実行を要求する
- サーバーが結果を返し、その内容をもとにモデルが応答を続ける
ℹ️ Note
『MCP』の挙動が腹落ちしないときは、「モデルが直接ツールを知っている」のではなく、「クライアントがサーバーから道具一覧を受け取り、その中からモデルが選んでいる」と捉えると、デバッグの視点も揃います。
用語の1行定義集
『MCP』:LLMやAIアプリと外部ツール・データソースをつなぐためのオープン標準です。
ホスト:エージェントが動作するアプリや実行環境そのものです。
クライアント:ホスト内部でMCPサーバーと通信する実装部分です。
サーバー:ツール、リソース、プロンプトを提供する外部機能の公開元です。
ツール:実行可能な操作です。
たとえば検索、作成、更新、照会が該当します。
リソース:モデルやユーザーが参照するデータです。
文書、ファイル、設定値などを含みます。
プロンプト:再利用可能な指示テンプレートです。
JSON-RPC 2.0:メソッド名と引数をJSONで送受信するRPC形式です。
RAG:外部知識を検索して回答生成に取り込む手法です。
Function Calling:モデルが関数定義から呼び出し先と引数を選ぶ仕組みです。
A2A:エージェント同士が連携するための別レイヤーの標準化領域です。
stdio:ローカル実行でよく使われる標準入出力ベースのトランスポートです。
Streamable HTTP:HTTP越しの共有や本番運用で使われる公式トランスポートです。
MCPとA2Aは何が違うのか
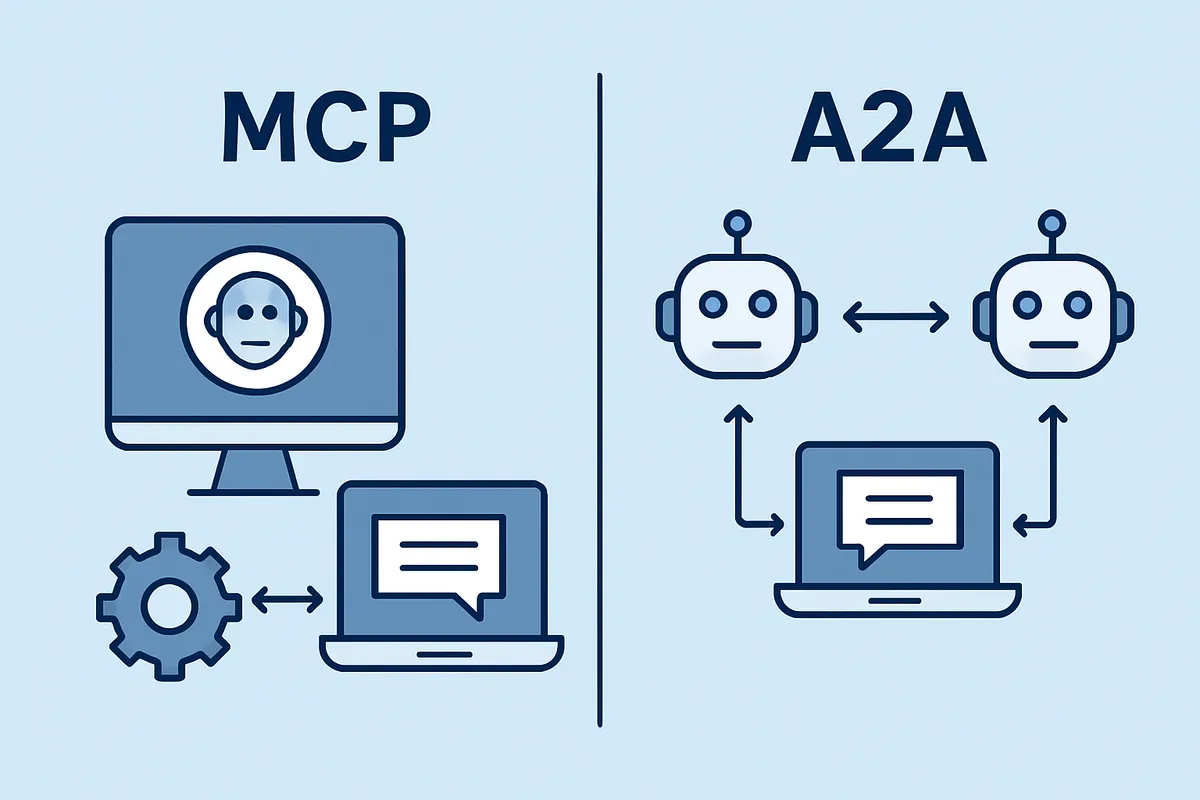
Agent-to-ToolとAgent-to-Agentの境界
MCPとA2Aが混同されやすいのは、どちらも「エージェントが何かと連携する」話に見えるからです。
ただ、設計の焦点ははっきり分かれます。
MCPはAgent-to-Tool、つまり1つのエージェントが外部ツールやデータソースを使うための標準です。
対してA2AはAgent-to-Agent、つまり役割の異なる複数エージェントがやり取りし、分業や合意形成を行うための連携領域です。
この違いは、実装に入るとすぐ効いてきます。
たとえば『Claude Code』や『Cursor』にMCPサーバーを追加すると、1つのエージェントがGitHub、社内API、ファイル、検索ツールをまとめて扱えるようになります。
ここで起きているのは「同じ行為者が手足を増やしている」状態です。
一方でA2Aの発想では、計画担当、実装担当、レビュー担当のようにエージェント自体を分けます。
こちらは「行為者を増やしている」状態と言えます。
Model Context Protocolの公式アーキテクチャ説明では、ホスト・クライアント・サーバーの構造で、エージェントが外部能力へアクセスする形が整理されています。
これはあくまでツール接続の標準であって、複数エージェントの役割交渉そのものを主題にしているわけではありません。
A2Aはその上位、あるいは隣接レイヤーで考えると座りが良いです。
実務で構成を組むときも、この境界で整理すると迷いません。
筆者はまずMCPで「1エージェントが何をできるか」を固め、その後でA2A的な分業を足す順番が無理なく進むと感じています。
最初から複数エージェントを立てると、失敗したときに「ツール接続が悪いのか、役割分担が悪いのか」が切り分けにくくなります。
先にMCPで道具箱を整えれば、あとから計画役と実行役を分けても責務が崩れません。
ℹ️ Note
境界設計の基本は、MCPでツール接続を標準化し、その上にA2Aの会話ルールや役割分担を重ねることです。ツール層と協調層を分離すると、保守時にどこを直すべきかが見えやすくなります。

MCP を使用して Claude Code をツールに接続する - Claude Code Docs
Model Context Protocol を使用して Claude Code をツールに接続する方法を学びます。
code.claude.com両方が必要になるシナリオ
単体エージェントの延長で済む仕事なら、MCPだけでも十分戦えます。
たとえば「リポジトリを読んで、Issueを検索し、必要ならPRの下書きを作る」といった流れは、1つのエージェントに複数ツールを持たせれば成立します。
ここでは、MCPがあることでツール追加のたびに個別実装を増やさずに済みます。
ただ、作業が大きくなると、1人の有能な担当者だけでは詰まり始めます。
要件の解釈、実装方針の比較、リスクレビュー、承認フローのように、観点の異なる判断が必要になるからです。
この段階でA2Aの価値が出てきます。
計画用エージェントがタスクを分解し、実装用エージェントがコードを書き、検証用エージェントが差分を確認する、といった形です。
各エージェントが必要なツールへアクセスする足回りはMCPが担い、エージェント同士の協調はA2Aが担う、という分業になります。
たとえば社内開発フローを考えると、設計レビュー担当エージェントは設計書やナレッジベースを参照し、実装担当エージェントはリポジトリやCI情報に触れ、運用担当エージェントは監視データやチケットシステムを見るかもしれません。
全員が同じツールを使うとは限りませんし、同じツールでも権限は分けたいはずです。
ここでMCPがツール接続と権限境界の整理に効き、A2Aが役割分担と引き継ぎの整理に効きます。
マルチエージェント時代に両方が必要になる理由は、まさにこの二層構造にあります。
MCPだけでは「誰が何を決めるか」が定まりません。
A2Aだけでは「各エージェントが何を使って行動するか」が曖昧なままです。
単体エージェントの能力拡張と、複数エージェントの分業・審議・合意形成は、別の問題を解いています。
だからこそ、片方を入れればもう片方が不要になる、という関係ではありません。
現場感としても、最初に導入しやすいのは「単体エージェント+MCP」です。
ここでツール接続、認証、ログ、権限設計を整え、その後に「計画役」「実行役」「レビュー役」を増やすほうが、障害点が少なく進みます。
マルチエージェントを先に組むと派手に見えますが、基盤のツール接続が曖昧だと、結局は各エージェントが個別にAPI連携を抱えてしまい、標準化のうまみが消えます。
RAG/Function Calling/個別API連携との比較表

MCPとA2Aの違いは、RAGやFunction Calling、個別API連携も並べるとさらに見通しが良くなります。
Google。
つまりRAGの置き換えというより、守備範囲が違う技術として見たほうが正確です。
実際に設計の選択肢として並べると、次のように整理できます。
| 項目 | MCP | A2A | RAG | Function Calling | 個別API連携 |
|---|---|---|---|---|---|
| 主目的 | エージェントと外部ツール・データの接続標準化 | 複数エージェントの協調・役割分担 | 外部知識を取得して回答品質を上げる | モデルに関数を選ばせて実行する | アプリごとにAPIを直接つなぐ |
| 主な接続先 | ツール、API、DB、ファイル、プロンプト | 他のエージェント | 検索基盤、ベクトルDB、文書 | アプリ内で定義した関数 | 個別SaaSや社内API |
| 実行アクション | 可能 | 可能 | 原則は回答生成中心 | 可能 | 可能 |
| 標準化の焦点 | Agent-to-Tool | Agent-to-Agent | 情報取得パターン | 関数呼び出しのインターフェース | 標準化なし、都度実装 |
| 再利用性 | 複数クライアントで再利用しやすい | 役割設計を横展開しやすい | 検索基盤を共有しやすい | アプリ単位に閉じやすい | 実装ごとに分断されやすい |
| 保守性 | ツール公開をサーバー側に寄せやすい | 協調ルールの保守が必要 | インデックス更新運用が中心 | 関数定義の増加で煩雑化しやすい | 連携先が増えるほど管理が散らばる |
| 向く場面 | 1エージェントに複数ツールを持たせたいとき | 計画・実行・レビューを分業したいとき | 文書検索やナレッジQA | 少数の関数を素早く組み込みたいとき | 小規模で短期の専用統合 |
この表を見ると、MCPはFunction Callingの上位互換というより、ツール公開と接続管理まで含めて整理するための標準だとわかります。
Function Callingは軽量で、少数の関数を扱う場面では今でも有効です。
ただ、ツールの数が増えたり、複数クライアントで共有したくなったりすると、毎回関数定義と実装を抱える構成が重くなります。
そのときMCPの価値が出ます。
個別API連携はもっと単純で、最初の1本をつなぐだけなら最短です。
ですが、GitHub連携、チケット連携、検索連携、ファイル操作が増えたあたりから、認証方式も例外処理もバラバラになりがちです。
実際に小さく始めたプロジェクトでも、2本目、3本目のAPIを足すころには「どの認証情報をどこで管理するか」「失敗時のログをどこで追うか」が急に問題になります。
MCPはこの散らかり方を抑えるための整理術として効きます。
A2Aはこの表の中で少し位置づけが違います。
RAGやFunction Callingや個別API連携が「どう能力に触るか」の話だとすると、A2Aは「誰にその能力を持たせ、どう協調させるか」の話だからです。
だから、MCPとA2Aは競合ではなく、むしろ積み重ねる関係です。
1つのエージェントがMCP経由で十分な道具を持ち、そのうえで複数エージェントに役割を分ける。
この順で見ると、ツール連携とエージェント連携の境目がすっきり見えてきます。
最初に試すべき3つのクックブック
導入の最初は、1本で価値が伝わるレシピから入るのが失敗しません。
MCPは仕組みの説明だけだと抽象的に見えますが、会話から外部ツールを呼び出して、その返り値を次の判断に使う流れを一度体験すると、何が標準化されているのかが一気に腹落ちします。
ここでは『Claude Code』『Cursor』VS Codeのどれかに既存のMCPクライアントがある前提で、再現しやすい3本を並べます。
ローカル実行の例は Python 3.10 を前提にし、公開MCPサーバーを追加するだけで成立するものも混ぜています。
MCPの構造そのものはModel Context Protocolの 『Architecture overview - Model Context Protocol』 がよく整理されています。
レシピ1:天気APIを会話から取得
最初の1本として最も扱いやすいのが天気情報です。
入力が短く、正解イメージも共有しやすく、返ってきた値をそのまま会話に使えるからです。
チーム内でMCPを紹介するときも、私はこの天気APIのレシピを最初に配ることが多いです。
数分で動くので、説明会より先に「まず触ってもらう」入口として機能します。
前提環境は、Python 3.10、既存のMCPクライアント、そして公開されている天気系MCPサーバーを追加できることです。
ローカルで試すなら『MCP Python SDK』のクイックスタート系サンプルを土台にできます。
『Build an MCP server』 に沿った最小構成でも十分です。
外部の天気APIを呼ぶ実装ではAPIキーが必要な場合がありますが、公開サーバーを使う形ならクライアント側の準備を減らせます。
流れはシンプルです。
入力は「今日の東京の天気を教えて。
午後に外出するので服装の目安も付けて」です。
ツール選択の段階で、エージェントは天気取得用ツールを選び、地名や日付の解決に必要な引数を組み立てます。
実行ではMCPサーバーが外部天気APIを呼び、気温や降水確率のような結果を返します。
結果利用では、その値を会話に戻し、「雨の可能性があるので折りたたみ傘を持つ」「朝晩で気温差があるので薄い上着を足す」といった文脈化まで行います。
単なるAPIレスポンス表示ではなく、返り値を次の判断材料に変換できるところが体験の肝です。
コピペ手順としては、まずクライアント側で天気用MCPサーバーを1つ追加し、接続状態を開きます。
『Claude Code』なら .mcp.json や claude mcp add 系の設定が使え、 /mcp で状態確認ができます。
『Cursor』なら Settings の MCP からサーバーを追加し、MCP Logs で接続確認をします。
追加後に「利用可能なツールを列挙して」と打ち、天気系ツール名が見えていれば接続完了です。
そのまま「大阪の明日の天気を取得して」と投げて結果が返れば完了確認になります。
このレシピで出やすいエラーも絞られています。
stdio で起動しているサーバーが stdout に通常ログを混ぜると、JSON-RPC の応答が壊れてツール一覧取得に失敗します。
開発初期に最も多いのはこれです。
ログは stderr に分けるだけで収まります。
HTTP系サーバーを使う場合は、Streamable HTTP のURL設定違いで接続失敗になることがあります。
ブラウザ経由のクライアントではCORS設定漏れも起こりやすく、見た目は「サーバーが落ちている」ようでも原因はヘッダー不足だった、ということが珍しくありません。
認証付きAPIを背後で使う構成では、APIキー未設定や期限切れでも同じく「ツール実行失敗」に見えるので、クライアント側のエラー表示とサーバーログを並べて見ると切り分けが早く進みます。
レシピ2:ドキュメント参照

2本目は、社内外のドキュメントを会話から引ける状態を作るレシピです。
これはRAGに近い用途に見えますが、MCPでは「読む」だけでなく、その文書群をツールやリソースとしてどう公開するかまで含めて整理できます。
最初の検証では、製品マニュアル、設計メモ、運用手順書のように、答えの典拠を人間が目で追いやすい文書群が向いています。
前提環境は、既存のMCPクライアントと、参照対象を公開するMCPサーバーです。
ローカルのMarkdownやテキストを読むサーバーでもよく、HTTPで共有されたドキュメントサーバーでも構いません。
ここはAPIキーなしで始められる構成を取りやすく、公開MCPサーバーの追加だけで成立させやすいカテゴリでもあります。
入力は「オンボーディング手順書から、開発初日に必要なセットアップ項目だけ抜き出して」です。
ツール選択では、文書検索ツールか、ドキュメントリソース参照ツールを選びます。
実行では、対象ドキュメントのタイトルや本文断片、場合によっては該当セクションを返します。
結果利用では、返ってきた記述をそのまま引用するだけで終えず、「初日に必要な作業順」に並べ替えたり、「管理者権限が要る工程」だけを再整理したりできます。
ここで会話に沿って再構成できるので、単なる全文検索より実務に馴染みます。
コピペ手順は、まずドキュメント用MCPサーバーをクライアントに登録し、リソース一覧または検索ツール一覧が見えることを確認します。
次に「参照できるドキュメント名を表示して」と入力し、対象文書が列挙されれば接続は通っています。
そのうえで「利用規約の更新履歴を探して」「運用手順書のバックアップ手順を要約して」のように、対象が限定された問いを投げます。
完了確認は、回答の中に文書名や該当セクションが含まれ、会話が憶測ではなく参照結果ベースになっていることです。
このレシピでは、認可まわりの設計が露出しやすいのが利点です。
読めるはずの文書が空になる場合、認証エラーというより、MCPサーバー側で公開対象から外れていることがあります。
OAuth 2.0 や OpenID Connect を組み合わせる実装では、トークン取得そのものよりも、付与スコープが狭すぎて必要な文書に届いていないケースがよくあります。
HTTPトランスポートではURL自体は正しいのに、認証付きエンドポイントへ到達できずツール一覧だけ見える、という半接続状態も起こります。
こういうときは「検索は見えるが本文取得だけ失敗する」という形で表面化しやすく、ツール列挙成功だけでは安心できません。
3本目として導入効果が伝わりやすいのが、価格やコストの照会です。
特にクラウド利用があるチームでは、見積もり議論の途中で「そのインスタンスタイプはいくらか」「この条件なら別リージョンでどう違うか」を会話中に引けるだけで、会議の速度が変わります。
私はAWS Pricing MCP Serverをつないでから、その場で数字を確認しながら話を進める場面が増えました。
Pricing API の呼び出し自体が無料なので、まず会話経由の照会を試すハードルも低く感じます。
前提環境は、既存のMCPクライアントとAWS Pricing MCP Server、加えてAWS側の認証情報です。
サーバーの配置場所によっては、クライアントから直接ではなくプロキシ経由でつなぐ構成もあります。
ローカルで始めるなら stdio、チーム共有なら HTTP を選ぶと運用イメージを掴みやすくなります。
入力は「東京リージョン相当で、特定のコンピュート条件の参考価格を調べて。
月額ではなく単価ベースで教えて」のような形です。
ツール選択では、エージェントが価格検索用ツールを選び、サービス名、リージョン、利用属性を引数に埋めます。
実行ではMCPサーバーが Pricing API を呼び、条件に合う価格情報を返します。
結果利用では、その数字をそのまま読み上げるだけでなく、「候補Aと候補Bを比較」「見積もり前提を会話に残す」「会議メモへ貼るために表形式へ整える」といった二次利用につなげます。
MCPの価値はこの先にあり、取得した結果を次の判断へつなぐ導線が短くなります。
コピペ手順としては、クライアントに価格照会用MCPサーバーを追加し、まず「使えるツール名を見せて」と投げます。
価格取得系ツールが列挙されたら、「AWSの価格照会で利用可能なサービス名を教えて」と続けます。
ここで候補が返れば認証と接続は概ね通っています。
次に具体的な問い合わせを1つ実行し、回答に価格項目と前提条件が含まれていれば完了です。
実務では、このあと「その価格を前提に月次概算の文章を作って」と続けると、取得結果が会話の中でどう使われるかまで体験できます。
つまずきやすいのは認証エラーとトランスポート設定です。
AWS認証情報の不足やロール設定の不整合があると、ツール呼び出し自体はできても価格取得だけ失敗します。
HTTPで公開した場合は、クライアントからの到達性はあるのに、認証ヘッダーの受け渡しが欠けていることがあります。
ブラウザ寄りのクライアントではCORSの設定漏れで preflight が落ち、見た目にはサーバー不調に見えることもあります。
stdio 運用では、ここでも stdout へのログ混入が障害の原因になります。
価格系はレスポンスがそれなりに長くなるので、JSON-RPCの壊れ方が天気APIより目立ちます。
ℹ️ Note
最初の価格照会は、複数条件の比較より単一条件の問い合わせから始めると、認証不備なのか引数不備なのかを切り分けやすくなります。
発展:Microsoft Sentinelツール群の監視クエリ呼び出し

3本の入口に慣れたあと、運用チームで手応えが出やすいのがMicrosoft Sentinelの監視クエリ呼び出しです。
ここまで来ると「便利な検索」ではなく、会話から監視・調査フローへ踏み込めます。
一部のMicrosoft Sentinel向けMCPツールは追加料金なしで使えるため、既存運用に載せるときの説明もしやすくなります。
前提環境は、VS Codeや他のMCPクライアントに加え、Microsoft Sentinelへ接続する認証済みのMCPサーバーです。
入力は「直近の高重大度アラートを一覧化して、送信元IPごとにまとめて」や「特定ホストに関する関連インシデントを調べて」といった調査指示になります。
ツール選択では、アラート一覧取得、インシデント参照、KQL実行系のツールが候補になります。
実行ではサーバーがクエリを投げ、結果セットを返します。
結果利用では、会話上で優先度順に再整理したり、簡易な一次トリアージ文を組み立てたりできます。
完了確認は明確で、アラート一覧やクエリ結果が会話に戻り、その内容をもとに「次に確認すべきイベント」までつながることです。
ここで止めずに、「該当IPの関連アラートも追って」と続けられれば、単発の検索ではなく運用フローに入っています。
この段階では、認証と権限の境界が結果に直結します。
接続済みに見えても、テナントやワークスペースの権限不足でクエリだけ失敗することがあります。
HTTP公開なら認証連携の設定ミス、ローカル stdio なら監査用ログを stdout に出してしまう事故が障害を増やします。
監視系ツールは返り値の粒度が大きく、エラー時の切り分けにログが欠かせません。
単体エージェント+MCPから始める利点は、こうした運用面の観測ポイントを先に揃えられるところにもあります。
MCPサーバーの作り方の最小構成
最小サーバーの骨格
自作の『MCP』サーバーは、最初から大きく作る必要はありません。
公式のBuild an MCP serverに沿って見ると、最小構成は意外と素直で、サーバーを起動し、公開する機能を宣言し、その中身のメソッドを実装する、という順番です。
骨格として押さえるべきなのは、どのトランスポートで待ち受けるか、どのToolsResourcesPromptsを外に見せるか、それぞれの入力スキーマと返り値をどう定義するか、そして失敗時にどんなエラーを返すかの4点です。
実装の感覚としては、HTTP API を1本作るより「AI に見せる操作面」を先に設計する作業に近いです。
たとえば最小のツールなら add(a, b) のような単純な関数でも成立しますが、その段階でも引数の型、必須項目、失敗したときの応答を曖昧にしないほうが、その後の拡張で崩れません。
『MCP』は JSON-RPCベースでやり取りするので、処理本体だけ動けば終わりではなく、インターフェースを機械的に解釈できる形で出すことに意味があります。
掴みやすく、ホスト・クライアント・サーバーの役割分担もここで整理できます。
最初の一歩では、ツールを1つ、必要なら読み取り専用のリソースを1つ、それぞれ名前と説明付きで公開し、正常系と異常系の両方を返せるところまで作れば十分です。
私はまず stdio で立ち上げて、ローカルで「作って動いた」感触を確かめることが多いです。
この速さは魅力で、手元のクライアントにぶら下げるところまで一気に進みます。
ただ、そこからチームで共有し始めると、HTTP に切り替えた瞬間に接続管理や実行確認が安定し、運用の見通しも立てやすくなります。
Tools / Resources / Prompts の違い
この3種類の違いを見やすく整理するため、まず簡潔な早見表を示します。
Tools / Resources / Prompts の早見表
| 種別 | 役割 | 向く用途 | 返すもののイメージ |
|---|---|---|---|
| Tools | アクション実行 | API呼び出し、検索、作成、更新、計算 | 実行結果、処理結果、外部操作の応答 |
| Resources | データ提供 | ファイル参照、設定値、静的情報、読み取り用データ | テキスト、JSON、ドキュメント内容 |
| Prompts | プロンプト提供 | 定型作業の下敷き、調査テンプレート、入力補助 | 再利用可能な指示文や会話テンプレート |
たとえば「今日の東京の天気を取得する」はToolです。
外部APIを叩いて結果を返すので、行為の主体があります。
一方で「社内用語集を参照する」「README を読む」はResourceが合っています。
そこでは何かを実行するのではなく、既にある内容を取り出して見せるだけだからです。
さらに「障害報告を要約するプロンプトを配る」「価格比較の問い合わせ文を整える」はPromptの出番です。
モデルに毎回長い指示を人が書かなくても、定型の作法をサーバー側から供給できます。
この切り分けを最初に雑にすると、あとでツールが肥大化します。
実務では、単なる参照まで全部Toolに押し込む例をよく見ますが、そうすると引数設計が複雑になり、一覧性も落ちます。
逆に、操作を伴うものをResource扱いにすると、クライアント側の期待と噛み合いません。
最小構成では、まず「実行」「参照」「定型文」の3つに置き直して考えると、宣言の粒度が安定します。
stdioとStreamable HTTPの実装メモ
トランスポートは、開発初期なら stdio、本番や共有を見据えるならStreamable HTTPという切り分けが素直です。
stdio はプロセスを起動して標準入出力で話すだけなので、手元の『Claude Code』や『Cursor』に最短距離でつなげられます。
セットアップの軽さは魅力で、Python の雛形なら依存関係が整っていれば短時間で起動確認まで進みます。
一方で、stdio には典型的な落とし穴があります。
通常ログを stdout に出すと、JSON-RPC のメッセージにログ文字列が混ざり、クライアントから見ると「応答が壊れた」状態になります。
最小サーバーの段階でも、ログは stderr に分けるか、ロガー設定で出力先を明示的に分離したほうが安全です。
ローカルでは動いたのに、少しログを足した瞬間に通信が崩れるのはこのパターンが多く、最初に癖を直しておくと後で詰まりません。
Streamable HTTPへ移すと、チーム共有や複数クライアント接続の扱いがぐっと整理されます。
ネットワーク越しに配置できるので、ローカル環境に依存せず、接続先も一本化できます。
HTTP トランスポートが推奨寄りで案内されており、共有前提の構成と相性がいいことがうかがえます。
開発の初速だけ見れば stdio が勝ちますが、複数人で触る段階では HTTP のほうが「誰のPCで動いているか」に引っ張られません。
手元で素早く作って、共有の直前で HTTP 化する流れは、実装コストと運用の安定を両立しやすい進め方です。
ℹ️ Note
stdio で最初の動作確認を終えたら、次に見るべきポイントは機能追加よりログの分離です。ここが曖昧なままだと、ツール本体ではなく入出力のノイズで切り分け時間を失います。
Python/C# SDKと雛形コード
SDK を使うと、サーバーの骨組みを自前で組み上げる負担が減ります。
主要どころでは『MCP Python SDK』と『MCP C# SDK』があり、どちらも公式リポジトリが公開されています。
Python なら pip install "mcp[cli]" で始められ、C# なら NuGet で ModelContextProtocol を追加する流れです。
Model Context Protocol GitHubを起点にすると、SDK とサンプルをまとめて追えます。
Python の最小イメージは、ツールを1つ定義してサーバーを起動する形です。
細部のAPI名はSDK更新で変わることがあるので、ここでは骨格だけを見るのが適しています。
from mcp.server.fastmcp import FastMCP
### mcp = FastMCP("minimal-server")
### @mcp.tool()
def add(a: int, b: int) -> int:
return a + b
if __name__ == "__main__":
mcp.run()このくらいのサイズなら、ローカルのクイックスタートは短時間で終わります。
実際、Python 3.10 環境が整っていれば、依存の導入からサンプル起動まで一気に進めやすく、最初の確認対象として向いています。
ここに入力バリデーション、説明文、例外処理を足していくと、そのまま実用側の雛形になります。
C# でも考え方は同じで、サーバー定義、ツール登録、起動の3段構成です。
『MCP C# SDK』は Microsoft と連携しながら整備されており、VS Codeや .NET 系の既存資産とつなぎやすいのが利点です。
概念的な雛形は次のようになります。
using ModelContextProtocol.Server;
var builder = McpServer.CreateBuilder();
var server = builder.Build();
server.RegisterTool(
name: "add",
description: "2つの整数を加算します",
handler: (int a, int b) => a + b
);
await server.RunAsync();『Python』を選ぶと試作の立ち上がりが速く、『C#』を選ぶと既存の業務システムや .NET ベースの運用に溶け込みやすい、という差が見えます。
どちらでも最初に作るべきものは同じで、1つのToolをきちんと宣言し、入力スキーマと失敗時の返し方を決め、クライアントから呼べることを確認するところから始まります。
そこまで到達すると、『MCP』サーバー開発は抽象論ではなく、手元の実装として輪郭が出てきます。
GitHub - modelcontextprotocol/csharp-sdk: The official C# SDK for Model Context Protocol servers and clients. Maintained in collaboration with Microsoft.
The official C# SDK for Model Context Protocol servers and clients. Maintained in collaboration with Microsoft. - modelc
github.com本番運用で外せないセキュリティ設計

最小権限・権限分離の設計
『MCP』を本番に載せるとき、最初に決めるべきなのはツールを何本つなぐかではなく、どの主体にどこまで権限を渡すかです。
PoC の段階では、ひとまず管理者権限の API キーを1本入れて動かしてしまいがちですが、このやり方は運用に入った瞬間に詰まります。
実際、本番では“誰が何をいつ実行したか”が後から追えることが最優先で、最小権限と監査ログを初期設計に入れておくと、後から権限を削る苦労が減ります。
設計の原則はシンプルで、Allow は最小化し、Deny をデフォルトに置くことです。
たとえば社内のSlack参照、チケット更新、クラウド設定変更を1つのエージェントにまとめて持たせる場合でも、同じ資格情報を共有させない構成に分けたほうが境界が明確になります。
読み取り専用ツールと更新系ツールを分離し、さらに本番変更を伴うツールは別の承認経路に乗せるだけでも、誤操作と横展開の範囲が変わります。
ツール単位のスコープ設計も欠かせません。
たとえば「検索」は全文検索だけ、「更新」は特定プロジェクトだけ、「削除」はそもそも公開しない、という分け方です。
ここで API 側の権限モデルと『MCP』側のツール公開設定を二重に合わせると、片方の設定ミスだけでは事故が広がりません。
加えて、ツールごとのレート制限を設けておくと、ループ実行や想定外の大量呼び出しが起きたときに被害範囲を絞れます。
特に外部課金を伴う API や更新系ツールでは、この制御がそのまま安全弁になります。
権限分離は人間の役割にも適用したほうが運用が安定します。
開発者が使う検証用ツール、運用者が使う本番参照ツール、限られた担当者だけが使う管理ツールを同列に置かないことです。
『Claude Code』や『Cursor』のようなクライアントから接続できる環境では、接続先が増えるほど「同じように見えるが権限が違うツール」が混ざりやすくなります。
名前の付け方、説明文、公開対象を分けておくと、運用時の判断ミスを減らせます。
OAuth/OIDCとサービス間認可
認証と認可は、ローカルで動く段階では後回しにされがちですが、本番ではここが境界線になります。
ユーザーを伴う操作ならOAuth 2.0の Authorization Code Flow を中心に置き、OIDCで利用者の識別を行う構成が扱いやすく、サービス間通信なら Client Credentials のようなサーバー間認可を使い分けるのが基本です。
『OpenID Connect』の Discovery で .well-known/openid-configuration を参照できる構成にしておくと、認可サーバーのエンドポイントや JWKS の取得先を固定値で埋め込まずに済みます。
運用で差が出るのは、トークンの寿命と保管方法です。
アクセストークンは短命にし、必要なら更新用の仕組みを分け、長期間そのまま使う静的トークンを減らしたほうが事故の尾を引きません。
ローテーションも「期限が来たら差し替える」ではなく、古い資格情報を段階的に外せる状態にしておくと、切り戻しの余地を残せます。
本番運用では短命トークン、PKCE、state、厳格な redirect_uri 検証の組み合わせが現実的な基準になります。
資格情報の置き場所も、PoC と本番の差が最も出る部分です。
環境変数で渡す方法は入り口として分かりやすい一方、本番ではシークレットマネージャに寄せたほうが更新と監査を一元化できます。
少なくとも、トークンや API キーをソースコードに埋め込まない、標準出力に出さない、例外メッセージに含めない、という線引きは外せません。
前のセクションで触れた stdout 混入の問題は、通信破損だけでなく、うっかり秘密情報をログへ流す事故にもつながります。
『MCP』のサービス間認可では、「エージェントが代理で何をできるのか」を人間の権限と一致させる発想が有効です。
ユーザー起点の操作ならユーザーのスコープを超えないこと、バックグラウンド処理なら専用のサービスアカウントを分けること、この2つを混ぜないだけでも設計は整理されます。
代理実行の境界が曖昧だと、いわゆる Confused Deputy に近い状態が起き、ツールが想定以上の権限で動き始めます。
Final: OpenID Connect Core 1.0 incorporating errata set 2
openid.net監査ログの必須フィールドと可観測性
本番でトラブル対応に時間がかかる構成は、たいてい「実行はできるが、追跡できない」状態です。
エージェントが便利になるほど、後から見返すべき情報は増えます。
監査ログに最低限入れておきたいのは、実行者、実行時刻、対象ツール、入力パラメータ、結果サマリ、許可または拒否の判定、トレース ID です。
これだけ揃っていれば、「誰が」「何を」「いつ」「どこまで実行したか」を一本の流れとして追えます。
ここでいう実行者は、人間ユーザーだけでなく、サービスアカウントやバッチ主体も含みます。
ツール名だけ残っていても、どのクライアントから、どのセッション文脈で呼ばれたかが抜けると、調査の粒度が一段荒くなります。
入力パラメータも全部を生で残すのではなく、機密情報はマスキングやレダクションをかけたうえで、意思決定に必要なキーだけ見える形にしておくのが現実的です。
たとえば検索クエリや対象 ID は残し、アクセストークンや個人情報は伏せる、という分け方です。
可観測性の面では、アプリ本体、認可基盤、外部 API、MCP サーバーを分散トレーシングでつなげると効果が出ます。
トレース ID をクライアントからサーバー、さらに下流 API に受け渡せば、「応答が遅い」「拒否が増えた」「失敗は外部 API 側か認可側か」といった切り分けが一気に進みます。
『Architecture overview - Model Context Protocol』で示されているように、『MCP』はホスト、クライアント、サーバーにまたがる構成です。
単一プロセスのログだけ見ても全体像は掴めません。
監査ログは保存するだけでは足りず、拒否イベントの可視化まで含めて設計したいところです。
許可された実行だけでなく、「拒否された理由」が残っていると、権限不足の誤検知と不正試行を分けて見られます。
ここが無いと、運用者は失敗件数だけを見て原因を推測するしかなくなります。
⚠️ Warning
監査ログの設計を後付けにすると、実行者 ID やトレース ID が取れない箇所が残りがちです。最初のツール公開時点でフィールドを決めておくと、後の横展開で穴が増えません。

Architecture overview - Model Context Protocol
modelcontextprotocol.ioMCP Proxyとツール汚染対策
MCP Proxyは、本番では便利な反面、境界を曖昧にしやすい部品でもあります。
複数の『MCP』サーバーを束ねたり、トランスポートを変換したり、NAT 越しの接続を扱ったりできるため、共有基盤としては筋がいいのですが、プロキシを1枚置いた瞬間に「どこで認可し、どこで監査し、どこで資格情報を終端するか」を再定義する必要が出ます。
ここが曖昧なままだと、表面上は整理されたように見えて、実際には権限境界がぼやけます。
特に注意したいのが、ツール汚染と権限過大化です。
ツール汚染は、信頼しているサーバー群の中に、説明文やスキーマは似ているが挙動の違うツールが紛れ込み、エージェント側が誤って使う状態を指します。
たとえば「list_users」という読み取り用に見えるツールが、裏で更新権限を持っていたら、名前だけでは見抜けません。
プロキシ配下で複数のツールソースを束ねるほど、このリスクは上がります。
公開時には、名前、説明、必要スコープ、更新系か読み取り系かを明示し、同名・類似名の整理を徹底したほうが事故を防げます。
権限過大化は、プロキシが便利だからといって上流の広い資格情報をまとめて持ち、下流ツールに横流ししてしまうと起こります。
NAT 越えや。
プロキシは接続制御と認証中継に留め、実際のリソース権限は下流側で再判定する二段構えのほうが、1か所の設定ミスで全体が開く状態を避けられます。
資格情報の扱いもプロキシで緩みやすい部分です。
上流から受け取ったトークンをそのままログへ出さない、エラーレスポンスに埋め込まない、デバッグ出力で流さない、という基本がここでも効きます。
複数トランスポートをまたぐ構成では、どの層でレダクションするかを決めておかないと、片側だけマスクされ、別の層で生の値が残ることがあります。
料金と予算監視の実務ポイント

PoC から本番へ進むと、セキュリティと同じくらい効いてくるのが予算監視です。
『MCP』自体の導入コストより、背後で叩く API、ログ保存、SIEM、生成モデルのトークン消費のほうが支配的になるケースが多く、費用の見え方も分散します。
そのため、ツールごとのレート制限や実行回数の可視化は、セキュリティ対策であると同時に予算管理でもあります。
無制限に呼べる構成は、不正利用だけでなく単純な誤実装でも請求を膨らませます。
コスト面では、無料で使える部分と追加課金が乗る部分を分けて考えると整理できます。
たとえばAWS Pricing APIの呼び出しは無料なので、見積もり補助や価格参照系のツールを作る入口として扱いやすい部類です。
一方で、結果を蓄積するログ基盤や通知、下流の分析サービス側で費用が発生する設計は珍しくありません。
Microsoft Sentinelでも一部の『MCP』ツールは追加料金なしで使えるケースがありますが、保管、分析、周辺ワークフローまで含めると全体コストは別に立ち上がります。
2026年3月時点では、こうした「ツール呼び出し自体は無料でも、周辺運用で費用が乗る」構造を前提に見たほうが、予算の読み違いが減ります。
実務では、モデル利用料だけを見ると判断を誤ります。
どのツールが何回呼ばれ、失敗リトライがどれだけ出て、どのログが長期保存に回るかまで追って初めて、月次の傾向が見えます。
監査ログの必須フィールドにコスト関連のタグや呼び出し元を添えておくと、「便利だから呼ばれている」のか「ループしている」のかが区別できます。
セキュリティ設計と予算監視を別物にしないほうが、本番運用では現場の判断が揃います。
2026年に向けた最新動向
2026 Roadmapの4本柱
『MCP』の次の焦点は、2026年3月9日に公開されたThe 2026 MCP Roadmapが最も整理されています。
そこでは、単なるツール接続の標準から一段進み、transport scalability、agent communication、governance maturation、enterprise readinessの4本柱が前面に出ています。
2024年11月に導入期の空気をまとっていた規格が、2026年には運用設計と組織導入の話まで含めて語られる段階に入った、という見方が近いです。
transport scalability は、接続先が増えたときにどうさばくかという話に留まりません。
共有サーバーの接続管理、状態の持ち方、認証のつなぎ方、観測性の担保まで含めて「ネットワーク越しで回る前提」に寄ってきています。
前述の通りローカル開発では stdio の軽さが効きますが、実プロジェクトで HTTP 化したときは、ネットワーク越しの共有、権限統制、監査連携が一気に前へ進みました。
このとき enterprise readiness という言葉が抽象論ではなく、組織の ID 基盤やログ基盤と結びつくための条件だと腹落ちしました。
agent communication は、A2Aのような agent-to-agent 標準と競合するというより、『MCP』が得意な agent-to-tool の先で、エージェント同士の受け渡しとどう接続していくかを意識した流れです。
単体エージェント+『MCP』が依然として導入の起点である一方、計画役と実行役を分ける構成が増えるほど、ツールの呼び出し結果や権限文脈をどう受け継ぐかが効いてきます。
governance maturation は、2026年に向けて見逃せない変化です。
仕様そのものだけでなく、運営体制がLinux Foundation配下のマルチカンパニー標準として成熟していくことで、特定ベンダーの実装都合ではなく、複数社が関わる標準化プロセスとして扱いやすくなっています。
PoC 向けの便利な仕組みから、社内規程や監査部門に説明できる標準へ寄っているわけです。
2025-11-25仕様アップデートの要点

1周年アップデートにあたる2025-11-25版は、派手な見出しよりも「本番へ寄せる整備」が目立つリリースでした。
One Year of MCP: November 2025 Spec Releaseで示された流れを見ると、相互運用性、認可まわり、運用に必要な土台の明確化が主題です。
このアップデートを境に、クライアント実装や SDK 側での追従も進みました。
『Claude Code』が HTTP トランスポートを推奨する文脈や、VS Codeのエージェント統合、『Cursor』の MCP 設定導線も、単独の製品機能というより、仕様の運用前提が整ってきた結果として見ると筋が通ります。
仕様策定とクライアント実装が別々に走る初期フェーズを抜け、少しずつ足並みが揃ってきた印象です。
MCP Apps(SEP-1865)の現在地
今の拡張議論で存在感があるのがMCP Appsです。
特に SEP-1865 で話題になっているのは、テキストや JSON を返すだけでなく、インタラクティブ UI を返せるようにする拡張としての位置づけです。
これは既存の Tools、Resources、Prompts を置き換える話ではなく、エージェントとアプリ体験の間にある段差を埋める方向だと捉えると理解しやすくなります。
たとえば承認フロー、絞り込み検索、選択式の操作、結果の再編集といった場面では、テキスト応答だけでは往復回数が増えがちです。
そこで UI を伴う返却が標準化されると、エージェントは「何を実行するか」を決め、人間は「どの候補を採るか」を画面で確定する分担が取りやすくなります。
現時点では有力な拡張情報として追うべきトピックであって、既に広く固定化された中心仕様として語る段階ではありませんが、MCP がアプリケーション面へ伸びていく方向性はここに表れています。
gRPCトランスポートの議論と立ち位置
gRPC を『MCP』のトランスポートに使いたい、という議論は確かにあります。
既存の社内基盤が gRPC 中心で動いている組織では自然な発想ですし、双方向通信や型付きインターフェースとの親和性を評価する声が出るのも不思議ではありません。
ただし、2026年時点での立ち位置は「標準採用済み」ではありません。
公式の重心は、stdIO と Streamable HTTP を軸に既存トランスポートをどう進化させるかにあります。
ここを取り違えると、話題として盛り上がっていることと、標準の中心にあることを混同しやすくなります。
gRPC はあくまで拡張候補や統合先としての検討対象であって、現時点の公式ロードマップでは transport scalability を既存路線の延長で詰める色が濃いです。
ブラウザ相性や標準化の筋の良さまで含めると、HTTP ベースを優先する判断には一貫性があります。
ℹ️ Note
gRPC の議論が注目されるのは、MCP が閉じたローカル接続の枠を越え、既存の企業システムとどう接続するかが現実のテーマになったからです。話題化そのものが、enterprise readiness へ関心が移った証拠でもあります。
MCP-Benchと品質評価の潮流
普及フェーズを越えてくると、「つながる」だけでは足りず、「どの実装がどれだけ安定して動くか」を比べる必要が出てきます。
そこで存在感を増しているのがMCP-Benchです。
公開されている評価では28サーバー、250ツールの規模が扱われており、単発デモでは見えない相互運用性やツール品質の差を観測する土台になっています。
セットアップ例に Python 3.10 が置かれている点も、実験用途だけでなく現場で回しやすい環境を意識したものです。
この種のベンチマークが意味を持つのは、SDK やクライアントが増えた結果、同じ『MCP』準拠でも使い勝手や堅牢性に差が出てきたからです。
たとえばツール説明の精度、スキーマの整い方、失敗時の返し方、長いセッションでの安定性は、仕様書を読むだけでは見えません。
品質評価の潮流が出てきたことで、今後は「MCP 対応」を名乗るだけでなく、どの程度の再現性と運用性を持つかまで見られるようになります。
運営面でも、この流れは governance maturation と噛み合っています。
Linux Foundation配下で複数企業が関与する標準になっていくほど、仕様、実装、評価の3点が分離され、相互に検証される構造が必要になります。
MCP-Benchのような動きは、その成熟度を測る周辺インフラとしても意味を持っています。
よくあるつまずきと選び方

設計で迷ったときは、MCP を「まずつなぐ」話と、「どう運ぶか」「どこで動かすか」「何人で分担するか」を分けて考えると整理できます。
初心者が詰まりやすいのは、技術選択そのものよりも、複数の判断軸を一度に抱えてしまう場面です。
ここでは、最初の分岐を4つに絞って見ていきます。
クライアントごとの設定画面や設定ファイルの場所は、『Claude Code』でも『Cursor』でもVS Codeでも更新頻度が高く、UI とバージョン差の影響を受けますが、たとえば『Claude Code』は .mcp.json や claude mcp コマンド、/mcp による状態確認がドキュメント化されています。
操作の入口は今後も変わり得ます。
接続先を増やす段階では、製品ブログよりも各クライアントの公式ドキュメントを起点に見るほうが筋がよく、MCP 自体の構造はModel Context Protocolの 『Architecture overview - Model Context Protocol』 を軸に押さえておくと混線しません。
stdio vs Streamable HTTPの早見表
最初の選択は、ほぼこの一問です。
開発初期とローカル検証なら stdio、本番運用や複数クライアントからの共有を見据えるなら Streamable HTTP という切り分けで、大半のケースは十分です。
stdio はプロセス間を標準入出力でつなぐので構成が短く、最小構成の検証に向きます。
『MCP Python SDK』のクイックスタートを触ると、ローカルで立ち上げてツール列挙を確認するところまでは短時間で進められます。
クライアントをまたいで共用したい、認証や監視を入れたい、ネットワーク越しに公開したいとなると HTTP ベースの方が扱いやすくなります。
以下の表は、最初の設計判断で見落としやすい点を含めた比較です。
| 項目 | stdio | Streamable HTTP |
|---|---|---|
| 実装容易性 | 高い。ローカルの子プロセス起動で始められる | 中程度。HTTP サーバーとして公開する前提が入る |
| 可観測性 | 低め。プロセス内部の状態を追う工夫が要る | 高め。HTTP ログ、メトリクス、プロキシ層で追いやすい |
| 権限分離 | 同一マシン・同一実行文脈に寄りやすい | 認証・認可の境界を設けやすい |
| スケール | 単一ユーザーや局所的な利用に向く | 複数クライアント共有や本番展開に向く |
| ログ混入リスク | stdout にログを出すと通信が壊れる | 通信とアプリログの経路を分けやすい |
stdio で最も多い事故は、実装ミスというよりログの出し先です。
私も一度 stdout へのログ混入で長く詰まり、それ以降は stdio の不調に当たると、コードより先に stderr 分離とロガー設定を見ます。
ツールが1つも見えない、JSON-RPC が壊れる、クライアント側で意味不明な失敗になる、といった現象が出るときは、アプリ本体のロジックより先にここを疑うと当たりやすいのが利点です。
本番側の文脈では、 HTTP トランスポート推奨の流れが見えています。
ローカルで stdio を使って設計を固め、その後に Streamable HTTP へ寄せる流れは、開発と運用の重心が自然に分かれます。
ローカル/リモート実行の設計判断
トランスポートを決めた後に来るのが、サーバーを手元で動かすか、リモートに置くかという判断です。ここは「どちらが上か」ではなく、どこに責任を置くかの違いです。
ローカル実行は、開発者の手元で完結するぶん、試行回数を稼げます。
ファイル参照、ローカル DB、開発中の API モックなど、近くにある資産へ触る用途では素直です。
ネットワーク越しの認証やファイアウォールを気にせず、ツール定義やスキーマ調整に集中できます。
反面、実行権限がユーザー端末に寄るので、権限境界を強く分けたい用途には向きません。
リモート実行では、ネットワーク、認証、名前解決、ファイアウォール、レイテンシが設計要素として前面に出ます。
その代わり、障害分離と権限分離を取りやすくなります。
たとえば社内 API や監査対象のデータソースへ接続するツールを、クライアントごとのローカル実装で散らすより、認証付きの HTTP サーバーとしてまとめた方が運用の筋が通ります。
OAuth 2.0 や OIDC を使う設計では、認可サーバーとの連携、トークンの扱い、境界でのログ監査まで含めてサーバー側に寄せるほうが自然です。
迷ったときは、次の見方が役立ちます。
手元の作業効率を優先するならローカル、共有・監査・権限制御を優先するならリモートです。
たとえば個人の調査補助や試作ならローカル、チーム利用の社内検索や業務更新系ツールならリモートの方が噛み合います。
リモート化した途端に不調が出たときは、アプリのコードだけを見ても進みません。
認証失敗なのか、ネットワーク到達性なのか、リバースプロキシやファイアウォールで落ちているのかを切り分ける必要があります。
単体エージェント/マルチエージェントの見極め

もうひとつ迷いがちな分岐が、1つのエージェントに複数ツールを持たせるだけで足りるのか、それとも複数エージェントに役割分担させるべきかです。
ここで背伸びをすると、設計もデバッグも一気に難しくなります。
実務では、最初の一歩としては単体エージェント+MCPで足りる場面が多いです。
たとえば「社内ドキュメント検索」「チケット参照」「簡単な更新 API」「コード検索」のように、1人の担当者が複数ツールを使い分けるイメージなら、1エージェントに MCP ツールを束ねる構成で十分回ります。
難易度が低く、失敗点も少なく、どのツールが答えに効いたかも追いやすいからです。
マルチエージェントへ進む分岐は、ツール数の多さではなく、役割の衝突が出たときです。
典型は3つあります。
ひとつは、計画と実行を分けたいときです。
調査計画を立てる役と、実際に API や DB を叩く役を分けると、プロンプトの責務が整理されます。
次に、合議制を入れたいときです。
生成した内容を別エージェントがレビューする、セキュリティ観点の再確認を別役にさせる、といった構成です。
もうひとつは、リスク分離です。
高権限ツールに触る実行役と、ユーザー対話を担う役を分けると、誤実行の経路を短くできます。
A2A まで必要になるのは、さらに一段先です。
組織横断で別系統のエージェント同士がやり取りする、ベンダーの違うエージェントを連携させる、責任境界をまたいで協調させる、といった場面で出番になります。
ℹ️ Note
役割分担の理由が「何となく賢く見えるから」しかない場合、単体エージェントで始めた方が失敗が少なくなります。分けるべきなのは、能力ではなく責任です。
デバッグの基本ルート
接続できない、ツールが見えない、呼び出しが失敗する。
この3つは別問題に見えて、追う順番はほぼ共通です。
手当たり次第にログを見るより、ルートを固定した方が早く抜けられます。
まず見るのはツール列挙です。
クライアントからサーバーが見えているなら、少なくとも一覧取得は通るはずです。
ここで何も返らないなら、サーバー起動、接続先設定、トランスポート設定のどこかが崩れています。
『Cursor』には MCP Logs があり、『Claude Code』には /mcp の状態確認があります。
クライアントごとの導線は違っても、最初に「列挙できるか」を見る点は共通です。
次に見るのがスキーマバリデーションです。
ツール名は見えているのに呼び出しだけ失敗するなら、引数の JSON Schema、必須項目、型、enum のズレを疑います。
MCP は「つながっているのに使えない」状態が起きやすく、原因の多くはここにあります。
サーバー実装側では、受け取った引数をそのまま下流 API に投げる前に、境界で検証してエラー内容を明示した方が追跡が早くなります。
その後に認証を見ます。
HTTP 化やリモート配置で急に失敗し始めた場合、実際には OAuth トークンやヘッダー、セッションの問題であることが多いです。
ユーザー向けフローなのか、サービス間なのかで想定すべき認証方式も変わります。
ローカルでは通るのにリモートだけ失敗するなら、コード本体より先に認証経路を洗う方が近道です。
認証が通っているのに不調が残るときは、ネットワークを切り分けます。
到達していないのか、途中で遮断されているのか、プロキシで書き換わっているのかは、アプリログだけでは見えません。
HTTP ステータス、リバースプロキシのアクセスログ、TLS 終端位置を含めて見ないと、原因が別レイヤーに逃げます。
そして stdio では、stderr 分離を改めて確認します。
通信路とログ出力を分けていないだけで、他の確認が全部ノイズになります。
stdio で一度この罠に当たると、次からは「まずロガー設定を見る」という順番に自然と変わります。
私自身、サーバー実装の中身を疑って時間を使ったあと、stdout のログ1行が原因だった経験以来、ここを最初の確認項目に置いています。
デバッグは派手なテクニックより、順番の固定が効きます。
列挙、スキーマ、認証、ネットワーク、ログ経路の順に見ると、MCP のトラブルはだいぶ輪郭がはっきりします。

Cursor · 料金プラン
自分に合ったプランを選ぶ
cursor.comまとめと次のアクション

この記事の要点サマリ
MCPはToolsResourcesPromptsの三役を分けて、エージェントと外部機能の接続を整理する土台です。
A2Aはその先にあるエージェント同士の協調で、最初から混ぜて考えない方が設計の迷いが減ります。
導入は公開MCPサーバーをまず1つ足し、運用に進める段階で最小権限、認証、監査ログの順に固める流れが失敗を抑えます。
今日から着手するチェックリスト
まずは『Cursor』や『Claude Code』など、手元の既存クライアントに公開MCPサーバーを1つ追加して、ツール列挙と呼び出しの感触を掴んでください。
次に、自分たちが本当に使いたいAPIを、最小のMCPサーバーとして1本だけラップします。
私の経験では、まず1サーバー追加、その次に自作を1本という二段階で進めると、個人の思いつきで終わらず、チームでも導入手順を揃えやすくなります。
本番利用を見据えるなら、実装より先に認証方式、権限境界を決めておくと後戻りが減ります。
監査ログの残し方を決めておくことも欠かせません。
認証の考え方はOAuth 2.0の仕様をまとめた IETF や、『OpenID Connect』の 『OpenID Foundation』 が土台になります。
マルチエージェント化は、その後にMCPでツール接続が整理できてから検討する順番で十分です。
AIビルダーの編集チームです。AI開発ツールの最新情報と使い方を発信しています。
関連記事
Ollama×VSCodeでローカルLLM開発環境を無料構築
Ollama×VSCodeでローカルLLM開発環境を無料構築
Ollama、Continue、そして qwen2.5-coder を組み合わせたローカルAIコーディング環境は、月額課金もAPIキーも不要で、コードを外に出さずに手元のPCだけで立ち上げられる構成です。
AGENTS.mdの書き方|Codex対応の設定ファイル設計
AGENTS.mdの書き方|Codex対応の設定ファイル設計
AGENTS.md は、AIエージェントに毎回プロジェクトの作法を説明し直さなくて済むようにする、リポジトリ直下の「エージェント向けのREADME」です。READMEが人間向けなのに対し、AGENTS.md はビルド手順、テスト、規約、触れてはいけない境界を1ファイルにまとめて渡す責務分離の仕組みで、
Aider 使い方|ターミナルで動かす設定とGit連携
Aider 使い方|ターミナルで動かす設定とGit連携
Aiderは、ターミナルで動くOSSのAIペアプログラミングツールであり、普段のシェルにaiderコマンドを打つだけでローカルのGitリポジトリと会話しながらコードを直接編集できます。
Codex CLIの使い方|インストールとAGENTS.md設定
Codex CLIの使い方|インストールとAGENTS.md設定
Codex CLIは、OpenAIが出したオープンソースのターミナル向けAIコーディングエージェントで、Rust製です。ChatGPTのブラウザ画面ではなく自分のマシンのターミナルで自然言語の指示を出し、コード生成からファイル編集、シェルコマンド実行までを一気に進められるので、