Claude Code 使い方|インストールと基本操作【2026】
Claude Code 使い方|インストールと基本操作【2026】
Claude Codeは、ターミナルでコードを読み、編集し、コマンド実行まで任せられるぶん、最初の導入順を間違えると「便利そうだけど怖い」で止まりがちです。ここでは、Mac・Windows・Linuxそれぞれでの安全な入れ方から、初回起動、
Claude Codeは、ターミナルでコードを読み、編集し、コマンド実行まで任せられるぶん、最初の導入順を間違えると「便利そうだけど怖い」で止まりがちです。
ここでは、Mac・Windows・Linuxそれぞれでの安全な入れ方から、初回起動、質問・編集・テスト・再開の4操作を最初の1時間で再現するところまで、迷わない順番で整理します。
私自身、新しく導入するときは空の検証リポジトリで claude を立ち上げ、まず読み取り専用のままバグ再現テストと一括修正をひととおり試すのを“儀式”にしています。
最初に「勝手に書き換えられない」感触を確かめるだけで心理的な壁が下がるので、Claude Codeは権限を理解しながら小さく始めるのがいちばん失敗しません。
そのうえで、プロジェクト記憶になるCLAUDE.md、会話を積み直さないためのメモリと再開導線、チーム導入で見落としやすいコストと分析まで、2026年時点の公式情報に沿って実務目線でつなげます。
全体像はClaude Code の概要とClaude Code をセットアップするに沿いつつ、現場でそのまま再現できる形に落とし込みます。
Claude Codeとは?Claudeとの違いとできること

Claude Codeの位置づけ
Claude Codeは、コードベースの読解、ファイル編集、コマンド実行、開発ツール統合までをひと続きで扱える agentic coding tool です。
単にコード片を生成する補助ではなく、いま開いているプロジェクトを前提に、関連ファイルを横断しながら調査し、必要な修正を加え、テストやGit操作まで流れとして進められるところに本質があります。
ターミナルだけでなくIDE、デスクトップアプリ、ブラウザにまたがって使える開発向けツールとして整理されています。
Quickstart やクイックチュートリアルで「初回認証時に Console 側へ ‘Claude Code’ ワークスペースが自動作成される」と報告される例があります。
実務では、この「会話」と「作業」が分かれていない感覚が効きます。
私が最初に驚いたのも、既存モノレポでテストが落ちたPRの原因特定から、関連箇所の横断修正、テスト再実行までを一気通貫で回せたことでした。
通常のチャット型AIだと、状況説明を人間が細かく橋渡ししないと進みません。
Claude Codeでは、リポジトリの文脈を読みながら、修正対象と検証コマンドをつないで進められるので、開発の実作業にそのまま接続します。

Claude Code の概要 - Claude Code Docs
Claude Code は agentic coding ツールで、コードベースを読み取り、ファイルを編集し、コマンドを実行し、開発ツールと統合します。ターミナル、IDE、デスクトップアプリ、ブラウザで利用できます。
code.claude.com通常のClaudeとの違い
混同しやすいのは、Claudeという名前が同じでも、Claude Codeと通常のClaudeは主目的が違うということです。
Webやデスクトップアプリで使う通常のClaudeは、会話、文章作成、要約、設計相談、軽いコード相談の比重が高い道具です。
一方のClaude Codeは、ローカルにあるコードを直接読み、必要なら編集し、ターミナルコマンドを実行して検証まで進めるための道具です。
この違いは、開発中の「次の一手」に表れます。
通常のClaudeに「このテスト失敗の原因を考えて」と相談することはできますが、実際のリポジトリを横断して関連ファイルを見比べ、修正を入れ、npm test や pytest を叩いて結果まで確認するところは主戦場ではありません。
Claude Codeはそこを正面から担います。
コードベースを読んで終わりではなく、読解→編集→実行→再検証までをループで回せるのが決定的な差です。
Windows 環境はシェルやファイルシステム周りの差が大きいため、安定動作しやすい環境としては Git Bash または WSL 2 を推奨します。
挙動面では、いきなり何でも書き換えるツールではありません。
前述の通り、既定では厳密な読み取り専用パーミッションから始まり、編集やコマンド実行では承認を挟みます。
この設計だからこそ、初回に空の検証リポジトリや手元の安全なプロジェクトで claude を立ち上げ、まず読ませてから少しずつ編集を試す流れが自然につながります。
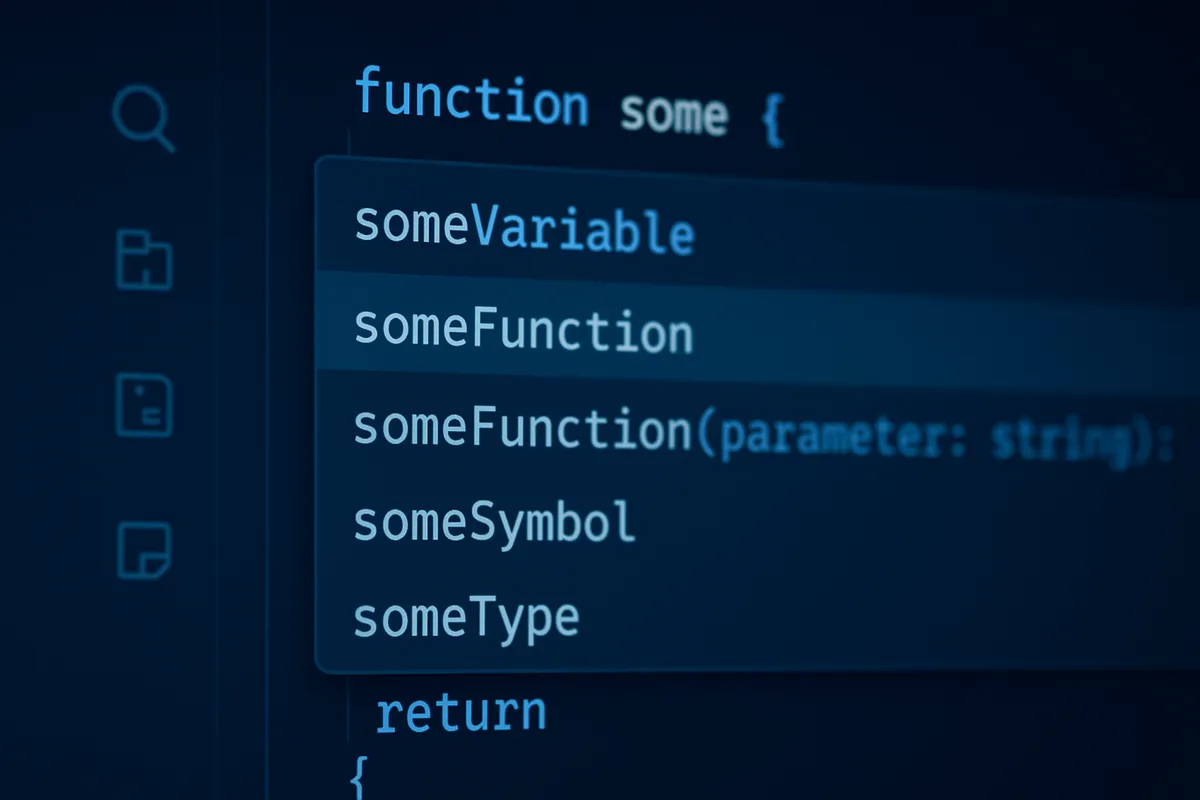
利用サーフェス
Claude CodeはCLI専用ツールと思われがちですが、実際には ターミナル、IDE、デスクトップアプリ、ブラウザ の4面で利用できます。
中心はあくまでCLIですが、作業スタイルに合わせて入口を変えられる構成です。
ここは文章だけだと伝わりにくいので、本文脇に次のような使い分け図を入れると理解が速くなります。
実際の使い分けは、次のイメージに近いです。
ターミナルは最も素の力が出る場所で、プロジェクトルートへ移動して claude を実行し、そのまま調査、編集、テスト、Git操作までつなげたいときに向いています。
IDE連携は、開いているファイルや差分を見ながら会話したい場面で効きます。
VS Code系ではインラインdiffや会話履歴、ファイル参照の文脈が活きるので、GUI中心の編集と相性がいいです。
デスクトップアプリやブラウザは、コードそのものに手を入れる前の相談や、作業ログの振り返り、軽い設計レビューの入口として噛み合います。
とはいえ、インストールして最初に再現したい基本動作はターミナルがいちばん明快です。
流れはシンプルで、まず公式セットアップページの手順で導入し、必要ならバージョンを更新し、対象リポジトリへ cd で移動してから claude を実行します。
初回はログインを求められるので認証を済ませ、その後に「このリポジトリで failing test の原因を調べて」のように依頼すると、Claude Codeらしい動きが見え始めます。
プロジェクト記憶として使う CLAUDE.md も、現在ディレクトリから親方向へ探索して読み込まれるため、この「どこで起動するか」がそのまま作業精度に関わります。
ℹ️ Note
Claude Codeを最初に触るときは、ホームディレクトリではなく対象プロジェクトのルートで claude を起動すると、読み込むコード範囲と CLAUDE.md の探索範囲が揃い、挙動の理由を追いやすくなります。
他ツール(Cursor/Windsurf)との比較要点
Claude Codeを評価するときは、通常のClaudeだけでなく、CursorやWindsurfのようなAI開発ツールと並べて見ると輪郭がはっきりします。
違いは「賢さ」だけではなく、どこで動き、どこまで自律的に作業を引き受けるかにあります。
| ツール | 主な利用形態 | ローカルコード編集 | コマンド実行 | 強い用途 | 体験の特徴 |
|---|---|---|---|---|---|
| Claude(Web/Desktop) | ブラウザ・デスクトップ中心 | 標準主目的ではない | 限定的 | 相談、文章生成、軽いコード相談 | 会話の立ち上がりが速く、非開発タスクにも広く使える |
| Claude Code | ターミナル中心、IDE・ブラウザ・デスクトップ対応 | 可能 | 可能 | 大規模コードベース探索、複数ファイル修正、テスト実行、Git操作 | 調査から修正、再検証までを一つの流れで回せる |
| Cursor | VS Code系AI IDE | 可能 | エージェント経由で一部可能 | 日常編集、補完、GUI中心のAI開発 | エディタ一体型で、普段の編集作業に溶け込みやすい |
| Windsurf | IDE型 | 可能 | 可能 | IDE内の日常作業、価格訴求を含む導入 | GUI中心で入りやすく、IDEを軸に運用しやすい |
実務で差が出るのは、大規模な既存コードベースをどこまで自律的に歩けるかです。
Claude CodeはCLI起点なので学習コストはありますが、複数ディレクトリをまたぐ探索、関連ファイルのまとめ読み、修正後のテストやCI前提の確認まで一本につながります。
モノレポや歴史の長い業務システムでは、この一貫性が効きます。
たとえば認証方式の移行や共通ユーティリティの差し替えのように、変更点が20ファイル以上へ広がる作業では、GUI中心のIDE型ツールより「まず全体を調べ、変更範囲を固め、実行で裏を取る」動きがそのまま武器になります。
一方で、CursorやWindsurfは、普段のエディタ体験の延長で使えることが強みです。
補完、部分編集、ファイルを見ながらの対話、GUIでの差分確認といった日常開発では、IDE統合の気軽さが効きます。
Claude Codeはその逆で、軽い補完よりも、バグ修正、テスト失敗の切り分け、複数ファイルの整合性確保、開発ツールとの接続を含めた「作業のまとまり」を取りにいく道具として見ると、立ち位置を誤りません。
始める前の準備と動作環境
Macの前提
Macでは、標準のTerminalでも進められますが、日常的に開発でiTerm2やzshを使っているなら、そのままの環境で問題ありません。
押さえておきたいのは、シェルがPOSIX系であること と、パッケージ管理にHomebrewを使う場面が多いということです。
Claude Codeはターミナル起点で動かすツールなので、GUIアプリのインストール感覚よりも、普段の開発シェルに1つコマンドを足す感覚に近いです。
権限まわりでは、macOS側のセキュリティ設定とターミナルの実行権限が影響することがあります。
初回は読み取り中心で始まり、編集やコマンド実行の前に承認が入る設計なので、いきなりリポジトリ全体を書き換える挙動にはなりません。
そのため、最初は検証用ディレクトリで起動して、どの操作で承認ダイアログや確認プロンプトが出るかを見ておくと、実務投入時の見通しが立ちます。
実際に試してみると、Macはセットアップ後の挙動が比較的素直で、シェル・PATH・権限の3点が揃っていれば詰まりにくい印象です。
Homebrew経由で入れる場合は更新方法も前提に入ります。
自動更新ではなく brew upgrade claude-code で手動更新する運用です。
普段Node.jsやPython系ツールを brew で管理している人なら違和感は少ないはずですが、アプリ本体のように黙って最新版になるわけではありません。
Homebrew経由でインストールした場合、更新は brew upgrade claude-code を手動で行う運用が前提になります。
次に、Windows 環境での前提を見ていきます。

Claude Code をセットアップする - Claude Code Docs
開発マシンに Claude Code をインストール、認証し、使用を開始します。
code.claude.comWindows
Windows の導入では、環境に応じた選択が肝心です。
ネイティブでの最小構成としては Git Bash が安定しやすい一方で、より一貫した Linux 相当の挙動が欲しい場合は WSL 2 を本命として検討してください。
PowerShell や Windows Terminal でも動くことがある反面、ファイルシステムや監視挙動、パス解決の差が出るため、どのシェルで運用するかは事前に検証しておくことをおすすめします。
WSL 1 を使う場合は一部機能やパフォーマンスで制約が出る報告もあるため、要件に応じて WSL 2 への移行を検討してください。
Linuxの前提
LinuxはUbuntuやDebian系、Fedora系などディストリビューション差はありますが、考え方は比較的シンプルです。
必要になるのは、標準的なシェル環境、git、開発で使うランタイム、そしてユーザー権限で扱える作業ディレクトリ です。
Claude Code自体はCLI中心のツールなので、ふだんの開発ターミナルがそのまま土台になります。
詰まりやすいのは、インストールよりも権限と作業場所です。sudo 前提のディレクトリや、チーム共有サーバー上の権限制御が厳しい場所で始めると、編集・コマンド実行・依存解決のどこかで止まりやすくなります。
実際に使ってみると、ホームディレクトリ配下か、開発用に権限を持ったワークスペースで起動したほうが挙動を素直に追えます。
逆に、権限が入り組んだサーバー環境で最初の検証をすると、「認証の問題なのか」「ファイル権限なのか」「シェル設定なのか」が分かれにくくなります。
公式ドキュメント(Claude Code の仕組み)を参照しつつ、OSごとの前提を押さえておくと導入がスムーズです。
アカウントとプラン/Console
導入前の見落としやすい点が、ローカル環境だけ整っていても使い始められない ということです。
Claude Codeの初回利用にはAnthropicのアカウントとサインイン導線が必要で、認証時にはConsole側の設定や状態も関わります。
プランの扱いは、このセクションでは断定より整理が欠かせません。
個人向けのPro系、チーム向けのTeam Premium系など、どの契約でClaude Codeの機能がどこまで含まれるかは、時期によって公式の表現が更新されることがあります。
2026年3月時点の把握でも揺れがあるため、料金や含有機能はAnthropic公式Pricingの最新表記を前提に読むのが安全です。
記事内の別セクションで料金は掘り下げますが、準備段階では「アカウントがあるだけでは足りず、契約とConsoleの状態も関係する」と捉えておくとズレがありません。
ネットワーク要件も先に整理しておくと、認証エラーと通信制限を切り分けやすくなります。
企業ネットワークでは、プロキシ必須、特定ドメインへのHTTPS通信制限、ブラウザ認証リダイレクトの遮断、証明書配布の独自運用が入っていることがあります。
加えて、端末管理の都合でターミナルからの外部通信、パッケージ取得、ブラウザ連携ログインが制限されることもあります。
こうした環境では、事前に見ておきたい論点は次の4つです。
- ブラウザ経由のサインインが端末ポリシーで遮断されていないか
- WSL 2やGit Bashの導入権限が端末ポリシー上で許可されているかを確認してください。
ここが揃っていない状態で進めると、「claude が起動しない」のではなく、「認証ページに飛べない」「サインイン後に戻れない」「更新コマンドだけ失敗する」といった分かりにくい止まり方になります。
準備段階でOSの前提、シェル、権限、そしてConsoleまで一本で見ておくと、インストール後の最初のつまずきをだいぶ減らせます。
Claude Codeのインストール手順
Mac
Anthropicの『Claude Code をセットアップする』に沿って入れるなら、まずはHomebrew経由が最短です。
ターミナルでそのまま実行するなら、導入は次の形になります。
brew install claude-codeインストール後は、作業したいプロジェクトのディレクトリへ移動してから claude を起動します。
CLI ツールなので、ホームディレクトリ直下で何となく立ち上げるより、対象リポジトリの中で始めたほうが、後の編集対象や権限確認の流れが自然につながります。
cd /path/to/your/project
claude(モデル)Macでは、空の playground リポジトリを一つ作って最初の起動確認を済ませると落ち着いて触れます。
私もHomebrewで入れた直後は、まずその空リポジトリで claude を叩きます。
最初に権限確認の案内が出るはずなので、そこでいきなり広い権限を渡さず、読み取り専用のまま進めると、ファイル探索や基本応答の雰囲気だけを安全側で確かめられます。
Homebrewで見落としやすいのが更新です。導入後に自動で新しい版へ追従するわけではないため、更新時は明示的に次のコマンドを使います。
brew upgrade claude-code新機能や不具合修正を追いたいのに、実際には古い版のまま動かしていた、というズレはここで起きます。brew install で入れたら、更新も brew upgrade claude-code とセットで覚えておくと運用がぶれません。
Windows

Windowsでも公式セットアップ導線を使うなら、WinGet経由が基本です。
管理者権限のあるPowerShellまたは通常のターミナルから、次のコマンドで導入できます。
winget install Anthropic.ClaudeCode起動手順は OS による違いがあるため、公式のセットアップページに沿って導入するのが確実です。内部手順を混在させないようにしましょう。
cd C:\path\to\your\project
claudeネイティブのWindows環境で使う場合は、シェルとしてGit Bashを使う前提で考えると流れが安定します。
前のセクションでも触れた通り、Windows TerminalとPowerShellだけでも動く場面はありますが、日常の開発コマンドやGit操作まで含めて揃えるなら、Git BashのほうがUnix系の手順と足並みが合います。
CLI での説明例もそのまま当てはめやすく、後からフックや補助スクリプトを入れる段階でも詰まりにくくなります。
更新はインストール時とは別に手動で走らせます。WinGet版は自動更新前提ではないので、次のコマンドを使います。
更新はインストール経路と同じパッケージマネージャで実行するのが分かりやすい運用です(例: WinGet で導入したなら winget upgrade を使う)。
winget upgrade Anthropic.ClaudeCode
Windowsで「起動はできるのに、更新だけ通らない」という状態は珍しくありません。端末ポリシーやWinGetの利用制限が入っている構成だとここで止まるので、導入経路と更新経路が同じ `winget` で揃っているかを見ておくと切り分けが早くなります。
### Linux
Linuxも、『Claude Code をセットアップする』に載っている公式手順から入るのが素直です。公式が案内する方法に沿ってインストールし、導入後はプロジェクトディレクトリで `claude` を起動します。
claude
Linux はUbuntuDebian系か、Fedora系かで普段使うパッケージ管理が違いますが、Claude Code自体はCLIツールなので、普段の開発シェルにそのまま乗せる形になります。インストール時に見るべきポイントは、どのユーザー権限で入れたかと、`claude` コマンドへPATHが通っているかの2点です。ここが揃っていれば、その後の起動確認はMacやWindowsと同じ流れで進みます。
作業開始は、やはり対象プロジェクトの中から行います。
cd /path/to/your/project claude(エージェント)
Linux では `/usr/local` 配下や共有サーバー上の権限が絡む場所で最初の検証を始めると、インストールは通っても実行時のファイルアクセスで引っかかることがあります。ホームディレクトリ配下の手元プロジェクトで `claude` を立ち上げ、まずはプロンプト表示まで確認する流れのほうが、認証・PATH・権限を一つずつ見分けられます。
### 初回ログインとワークスペース作成
インストールが済んだら、初回は**プロジェクトディレクトリで `claude` を実行する**ところから始まります。ここでブラウザ認証へ進み、サインインが完了するとCLI側にログイン成功のメッセージが返ってきます。文言は版によって多少前後しますが、「認証が完了した」「この端末で利用できる状態になった」と分かる内容が表示されれば流れは通っています。
cd /path/to/your/project claude(サービス)
初回ログイン時に、Console 側に “Claude Code” ワークスペースが自動作成される旨の案内が出るという報告があります(Quickstart 等)。
起動確認は難しくありません。ブラウザ認証を終えてCLIへ戻り、`claude` のプロンプトが表示されれば導入は成功です。最初の確認としては、主要コマンドを一覧できる `/help` を打つと、セッション内で何ができるかを把握しやすくなります。
/help
この段階で見ておきたいのは、「対話が始まるか」だけではなく、「今いるディレクトリを前提に会話できるか」です。たとえばリポジトリ直下で立ち上げて「このプロジェクトの構成を見て」と聞いたときに、ファイル探索の前提が自然につながっていれば、作業場所の選び方も合っています。
> [!WARNING]
> 初回は実プロジェクトではなく、検証用の小さなリポジトリで `claude` を起動すると、認証、権限確認、基本コマンドの流れを落ち着いて追えます。実プロジェクトでいきなり全権限を与えないでください。
### 更新・アンインストール
更新コマンドは導入経路ごとに分かれます。MacでHomebrewを使ったなら `brew upgrade claude-code`、WindowsでWinGetを使ったなら `winget upgrade Anthropic.ClaudeCode` です。どちらも自動で追従する前提ではないので、導入時のコマンドと同じパッケージマネージャで更新します。
brew upgrade claude-code
winget upgrade Anthropic.ClaudeCode
アンインストールも同じ考え方で整理できます。Homebrew版は `brew uninstall claude-code`、WinGet版は `winget uninstall Anthropic.ClaudeCode` という対応になります。Linux も、入れた方法に対応する削除手順で戻します。複数の導入経路を混ぜると、どの `claude` が呼ばれているのか分かりにくくなるので、入れた方法と消す方法を揃えて管理したほうが混線しません。
古いnpm版から移行する場合も注意したいところです。以前の `npm install -g` 系の導入が端末に残っていると、`which claude` や `where claude` で見える実体がHomebrew版やWinGet版ではなく、古いnpm版を指していることがあります。更新したつもりなのに挙動が変わらないときは、この二重導入が原因になりがちです。現行の公式セットアップ導線へ寄せるなら、古いnpm版を残したままにせず、PATH上でどの実体が使われているかを揃えておくと起動後の切り分けがぶれません。
{{related:claude-code-install}}
## 最初に覚える基本操作
### コードベースに質問する
最初の一歩は、いきなり編集させるより、今いるリポジトリを読ませて全体像をつかむ会話から入るほうが流れを作りやすくなります。Claude Codeはターミナルにいるぶん、会話の対象がその場のコードベースに結びついているのが強みです。起動直後に `/help` を一度見ておくと、使える操作の輪郭を短時間でつかめます。
たとえば最初の質問は、このくらい具体的で十分です。
このリポジトリのディレクトリ構成を上位から把握して、アプリ本体、テスト、設定ファイルがどこにあるか教えて
もう一段踏み込むなら、特定モジュールの役割を聞くと理解が速くなります。
具体的な抜粋やファイル参照を与えると、返答の精度が上がります。
auth まわりの実装を見て、ログイン処理の入口になっているファイルと、トークン検証をしている箇所を教えてこの手の質問では、回答の中にファイル名、役割、依存関係が入っているかを見るのがコツです。
「何となくこのへんです」ではなく、「src/auth/index.ts が入口で、middleware/verifyToken.ts が検証担当」という粒度まで落ちてくると、その後の修正依頼がぶれません。
ファイルを明示して読ませたいときは、会話中で対象を絞る書き方も有効です。@ でファイルを参照しながら、抜粋の意味を聞く流れにすると、広いリポジトリでも文脈が散りません。
@src/auth/index.ts と @src/middleware/verifyToken.ts を見て、この2つの責務の違いを説明してこの抜粋で例外処理が弱そうな箇所を指摘して最初の3プロンプトとしては、私は次の順番をよく使います。最初に構成を聞き、次に関係ファイルを絞り、そこから変更の見立てを作る流れです。
このリポジトリの構成を要約して。アプリ本体、テスト、設定の位置を分けて教えてユーザー登録フローの入口ファイルと、バリデーションをしているファイルを挙げて今の実装でメールアドレス重複時のエラーハンドリングがどうなっているか説明して
この段階で「どこを直せばよさそうか」の地図が見えてきます。
学習コストを下げるという意味でも、最初の数分で“このツールは勝手にコードを書くだけではなく、読解の相棒にもなる”と実感できる場面です。
自然言語で修正を依頼する
構造が見えたら、次は自然言語で修正を頼みます。
ここで効くのは、実装方法を細かく指定しすぎず、期待する挙動と制約だけを渡すということです。
たとえば次のように依頼できます。
ログイン失敗時のエラーメッセージを整理したいです。
未登録ユーザーとパスワード不一致を同じ文言に統一しつつ、
サーバーログには、原因が分かる形で残すようにしてください。
関連ファイルを調べて、必要な変更案を出してから編集してこの依頼だと、Claude Codeは関連ファイルをたどり、どこを触るべきかを提案してから編集に進みます。
複数ファイルにまたがる変更では、いきなり書き換えが走るのではなく、対象ファイルや差分の意図を示しつつ承認を求める流れになります。
ここで見るべきポイントは、変更対象が本当に必要最小限か、責務が変な場所へ広がっていないか、既存の命名や例外方針に沿っているかです。
インラインdiffの確認では、追加された条件分岐やメッセージ文言だけでなく、思わぬ import の増加や未使用コードの混入も見ておくと事故を減らせます。
特に複数ファイル編集では、主変更のついでに整形差分や小さなリファクタが混ざりやすいので、「今回の目的に直結する差分か」で線を引くと判断がぶれません。
実際、私は一度に大きく直すより、原因の仮説を立てるまず1ファイルだけ直すテストで確かめる必要なら関連修正を広げるの順で進めることが多いです。
この順番だと承認ダイアログの回数が増えるように見えて、実際には一回ごとの判断が軽くなります。
差分も読み切れる大きさに収まりやすく、結果として変更の質が安定します。
たとえば、こんな依頼だとその流れを作りやすくなります。
まずは原因候補を整理して、最小の1ファイル修正で再現ケースが改善するか見たいです。
変更前に対象ファイルを説明し、編集後は差分の要点を短くまとめてテストを実行・検証する
修正したら、次はその場でテストを回して結果を要約してもらいます。
ここもコマンドを自分で全部打つ必要はなく、自然言語で意図を伝えれば、Claude Codeが候補コマンドを提案し、承認後に実行する流れを取れます。
この変更に関連するテストを実行して。候補コマンドを出してから進めてJavaScript 系なら npm test、Python 系なら pytest のように、リポジトリに合った代表的なコマンドを提案してきます。
重要なのは、いきなりフルテストを投げるより、まず関連テストがあるかを見てもらうということです。
ユニットテストが分かれているプロジェクトなら、対象ディレクトリやテスト名に絞った提案が返ることがあります。
承認後は、実行結果をそのまま眺めるだけでなく、要約も一緒にもらうと判断が速くなります。
テスト結果を要約して。
失敗があれば、今回の変更起因か既存失敗かを切り分けて説明してこの一連の流れは、公式ドキュメントや。プロジェクトごとの運用ルールを CLAUDE.md に落とし込んでおくと、毎回の判断基準が安定します。
💡 Tip
テスト依頼は「全部回して」より、「今回触った認証周りのテストを優先し、その後必要なら全体テストへ広げて」と書くと、調査の焦点がぼけません。
テストの段階まで進むと、最初の基本操作が一本につながります。
コードベースに質問して構造を理解し、自然言語で修正を依頼し、提案コマンドを承認して検証する。
この一連の流れを一度通すだけで、CLI型の道具に対する心理的な壁が下がります。
セッションを再開・継続する
作業が長くなると、途中で端末を閉じたり、別タスクに移ったりします。
そこで覚えておきたいのが /resume と claude --continue 系の継続操作です。
対話中に過去セッションへ戻したいなら /resume が手早く、シェルから前回の流れを引き継いで始めたいなら claude --continue が自然です。
セッション再開で効くのは、前回の意図を短く添えるということです。履歴が残っていても、再開直後に一文あるだけで作業の軸が定まります。
前回は認証失敗時のメッセージ整理を進めていて、テストが1件落ちたところまで確認済みです。そこから再開してシェルから継続するなら、たとえば次の形です。
claude --continueこの操作は、前回の文脈を引き継いだまま作業を戻したいときに向いています。
対して /resume は、対話の中から再開候補を見ながら選ぶ感覚に近く、少し前のセッションへ戻りたいときに扱いやすいのが利点です。
どちらも「前に何をしようとしていたか」を一文で補足すると、関係ないファイル探索からやり直す回数が減ります。
継続操作は、単に便利というだけではありません。
複数ファイル修正の途中で中断しても、差分の意図とテスト状況を同じ流れで追えるので、翌日に再開しても判断が散りにくくなります。
よく使うコマンドとショートカット
基本操作を回し始めると、頻出の入口は自然に絞られてきます。
まず覚えておくと役に立つのが /help です。
コマンドを暗記するためというより、「今この場で何ができるか」を見失わないための地図として使う感覚です。
ファイル参照では @ が便利です。
会話に @src/app.ts のように書くだけで、対象を明示した質問や修正依頼に変えられます。
大きいリポジトリほど、この指定が効きます。
漠然と「このバグを見て」ではなく、「@src/auth/login.ts を見て、失敗時の分岐を説明して」と言えた瞬間から、やり取りの精度が一段上がります。
代表的なショートカット例としては Cmd+Esc / Ctrl+Esc、Alt+Ctrl+K のようなキー組み合わせが挙げられますが、割り当てはエディタや拡張、OSごとに異なります。
日常的によく使うものを小さくまとめると、最初はこの5つで十分です。
/helpで使えるコマンドを確認する@ファイル名で対象ファイルを明示する- 自然言語で「調査→提案→編集」の順に依頼する
- テスト実行前に提案コマンドを見て承認する
/resumeとclaude --continueで前回作業をつなぐ
このあたりを押さえるだけで、初回から「質問だけで終わるツール」ではなく、「読んで、直して、確かめて、続きを再開できる作業相手」として使い始められます。
実務で効く設定: CLAUDE.md・メモリ・ルール
CLAUDE.mdの役割と読み込み順序
Claude Codeを実務で安定運用するうえで、まず効くのが CLAUDE.md です。
役割は単なるメモではなく、プロジェクト固有の前提、禁止事項、レビュー観点、テスト方針、命名規約のような「毎回プロンプトで言い直していたこと」を長期記憶として一元化することにあります。
会話のたびに「このリポジトリでは npm test より対象テストを優先」「生成コードにはコメントを増やしすぎない」「変更後は型チェックまで回す」と書き直す運用は、回数を重ねるほどぶれます。
そこで CLAUDE.md に再現性の高い前提だけを置いておくと、毎回の立ち上がりが揃います。
読み込みの挙動も押さえておきたい判断材料になります。
Claude Codeのメモリ機能では、現在の作業ディレクトリから親ディレクトリ方向へ CLAUDE.md を探索して読み込みます。
つまり、リポジトリ直下で起動すればルートの CLAUDE.md が基準になり、さらに深いサブディレクトリで作業していれば、その場所に近い CLAUDE.md も発見対象になります。
『Claude があなたのプロジェクトを記憶する方法』 でも、この「現在地から上位へたどる」考え方が前提になっています。
この仕組みが効くのは、指示の重複を減らせるだけではありません。
私が特に効果を感じたのは、CLAUDE.md に「レビュー観点の順序」を書いたときでした。
たとえば「まず仕様逸脱、次に副作用、次にテスト不足、次に命名と可読性」の順で見る、と固定しただけで、毎回の修正からレビュー、微修正への往復が減り、返ってくる出力の揺れも目に見えて小さくなりました。
モデルの性能差というより、評価軸を先に揃えたことが効いた感覚です。

Claude があなたのプロジェクトを記憶する方法 - Claude Code Docs
CLAUDE.md ファイルで Claude に永続的な指示を与え、自動メモリで Claude が自動的に学習を蓄積できるようにします。
code.claude.comモノレポ/サブディレクトリでの設計

モノレポでは CLAUDE.md を一枚岩で巨大化させるより、ルートとサブディレクトリで役割分担したほうがうまく回ります。
ルートにはリポジトリ全体の共通ルールだけを書き、各アプリやパッケージ配下には、その領域でしか使わない制約を足す設計です。
たとえば apps/web ではフロントエンドのテストコマンドやデザインシステムの扱いを、packages/api では OpenAPI 更新手順やマイグレーションの注意点を書く、といった分け方です。
この構成にしておくと、サブディレクトリで作業を始めたときに、その場所に近い前提が自然に見つかります。
結果として、Web 側のルールを API 修正に持ち込んだり、逆にバックエンドの制約をフロントエンドへ誤適用したりする回数が減ります。
モノレポほど「全部入りの共通ルール」が罠になりやすく、1つの CLAUDE.md に全チームの事情を書き込むと、読まれる量は増えても実務精度は上がりません。
設計のコツは、ディレクトリごとに最小限の追加ルールだけを書くということです。
ルートの CLAUDE.md に「全体の原則」、サブディレクトリの CLAUDE.md に「その配下だけの例外」を置くと、衝突が起きにくくなります。
たとえばルートで「変更後は関連テストを優先」と定めつつ、apps/mobile 側だけ「UI スナップショット更新前に差分確認を挟む」と追加する形です。
これなら粒度が自然で、修正意図も追いやすくなります。
.claude/rules/の使い方
CLAUDE.md に全部を書かず、補助資料を .claude/rules/ に分割する運用も実務では効きます。
とくにレビュー手順、ブランチ運用、テスト実行の流れ、PR 記述ルール、生成禁止パターンのように、ひとつのテーマとして独立しているものはファイルを分けたほうが保守しやすくなります。
1ファイルに追記を重ねると、読む側も直す側も負担が増えますが、review.md、testing.md、coding-style.md のように分けておけば、差分レビューの単位も自然です。
ここでの考え方は、CLAUDE.md を入口、.claude/rules/ を詳細置き場として使い分けるということです。
入口側には「何を守るか」を短く書き、詳細側には「どう守るか」を記すと構造が崩れません。
チームで運用すると、コード規約だけ更新したいのに CLAUDE.md 全体を触る必要がある、という状況がよく起きます。.claude/rules/ に分けておけば、変更管理の粒度が揃い、レビューでも意図が読み取りやすくなります。
プロジェクト標準として定着させるなら、ルール名の付け方も揃えておくと効きます。
たとえば「禁止事項」「テスト」「レビュー」「リリース前確認」のように、誰が見ても置き場を想像できる名前にしておくと、新メンバーも迷いません。
名前付けが曖昧だと、同じ内容が別ファイルへ重複しやすくなり、結局 CLAUDE.md の肥大化と同じ問題に戻ります。
コンテキスト節約Tips

コンテキストが大きいからといって、毎回すべてを流し込む設計は得策ではありません。
Claude Codeまわりでは 200,000 トークン級の文脈サイズに触れられることが多いものの、その余裕を「何でも積める」と解釈すると、むしろ焦点がぼけます。
MCP ツール出力だけでも 10,000 トークン規模に達すると、セッション全体の中で無視できない比率を占めますし、長い SKILL.md や大量の差分説明が重なると、必要な論点が埋もれます。
効くのは、全量投入ではなく要約、除外、部分読み込みを徹底するということです。
コードレビューなら「今回の変更と依存範囲だけ」、不具合調査なら「再現手順と関連ファイルだけ」、リファクタリングなら「現状の制約と完成条件だけ」を先に渡すほうが、出力は安定します。
とくに長い設計資料やログを貼るときは、先に人間側で章立てを抜き出すだけで、応答の質が変わります。
指示文そのものも、長いほど親切とは限りません。
むしろ長すぎる指示は、優先順位が見えなくなります。
実務で残す価値が高いのは、禁止事項、レビュー手順、テストコマンド、コード規約のような「再現性に効く最小セット」です。
背景説明や理想論を何百行も載せるより、変更時の判断に直結する項目を短く固定したほうが、セッションごとの差が出にくくなります。
CLAUDE.md は「全部を覚えさせる場所」ではなく、毎回ぶれたくない判断軸だけを置く場所と考えると記述量が自然に絞れます。
出力の粒度を揃えたい場合は、要点(禁止事項・テスト方針・レビュー観点)を短く固定しておくと効果的です。
出力設計にも目を向けたいところです。
Opus 4.6では出力上限の拡張が CHANGELOG で案内された流れがあり、長文の生成余地は広がっていますが、それでも一度に大きな成果物を吐かせるほど、途中で粒度が粗くなりやすい印象があります。
大きな設計書、移行計画、レビュー結果は、最初から「概要」「差分」「懸念点」「次アクション」に分割して出させるほうが、読み手にも扱いやすく、再プロンプトも短く済みます。
サンプル構成
まずは最小構成です。小さなリポジトリや個人検証では、この程度でも十分に効きます。
# CLAUDE.md
{{related:claude-code-hooks}}
## プロジェクト概要
- TypeScript の Web アプリ
- パッケージ管理は npm
## 作業ルール
- 変更前に関連ファイルを確認してから編集する
- 破壊的変更は提案を先に出す
- 不要な大規模リネームは避ける
## テスト
- 変更後は関連テストを優先して提案する
- 必要に応じて `npm test` まで広げる
## レビュー観点
1. 仕様逸脱がないか
3. テスト不足がないかこの形なら、会話のたびに繰り返しがちな最低限の前提を固定できます。
とくに「関連テストを優先」と「レビュー観点の順序」は、出力の流れを揃える効果が大きく、初期導入でも差が出やすい部分です。
少し大きいチームやモノレポでは、推奨構成を分けておくと運用が安定します。
repo/
├─ CLAUDE.md
├─ .claude/
│ └─ rules/
│ ├─ review.md
│ ├─ testing.md
│ └─ coding-style.md
├─ apps/
│ ├─ web/
│ │ └─ CLAUDE.md
│ └─ admin/
│ └─ CLAUDE.md
└─ packages/
└─ api/
└─ CLAUDE.mdルートの CLAUDE.md には全体原則を書きます。
# CLAUDE.md
## 共通方針
- 変更は最小差分を優先する
- 関連しない修正を混ぜない
- 生成コードは既存構成に合わせる
## 実行前の原則
- コマンド実行前に候補と意図を示す
- 影響範囲が広い変更は先に計画を出す
## テスト方針
- まず関連テストを提案する
- 全体テストは必要時のみ広げる
## 参照ルール
- 詳細なレビュー手順は `.claude/rules/review.md`
- テスト手順は `.claude/rules/testing.md`
- コード規約は `.claude/rules/coding-style.md`apps/web/CLAUDE.md のようなサブディレクトリ側には、その領域だけの追加条件を書きます。
# CLAUDE.md
## web 固有ルール
- UI 変更時は対象画面と影響コンポーネントを先に列挙する
- デザインシステムの既存コンポーネントを優先して使う
- 文言変更では i18n キーの有無も確認する
## テスト
- 変更後は関連するフロントエンドテストを優先するこの分け方にしておくと、ルートで共通原則を維持しつつ、各ディレクトリでは本当に必要な前提だけを追加できます。
結果として、毎回同じ説明を打ち直さずに済み、レビューと修正の往復も短くなります。
応用機能: IDE連携・Agent Teams・MCP・Skills・Hooks

VS Code/Cursor拡張の使いどころ
Claude Codeをターミナル中心で使い始めると、まず強さを実感するのは広い調査と一括修正です。
そのうえで、日々の編集作業まで含めて往復回数を減らしたい場面では、VS CodeやCursor向け拡張が効いてきます。
エディタ上で差分を確認しながら進められるので、提案をそのまま飲み込むのではなく、インラインdiffで一行ずつ判断する流れを作れます。
複数ファイルをまたぐ変更でも、「どこが変わったのか」を視覚で追えるぶん、レビューの密度が落ちません。
拡張経由で便利なのは、会話欄に現在のファイルや選択範囲、関連ドキュメントをそのまま渡せるということです。
とくに @ 参照は実務で頻度が高く、@src/auth/session.ts を見て、今回の不具合の原因候補を3つに絞って のように書くと、対象を狭めたまま会話を始められます。
プロジェクト全体を丸ごと読ませるより、編集対象と周辺だけを指すほうが応答の芯がぶれません。
前のセクションで触れたコンテキスト管理とも相性が良い運用です。
エディタ拡張での呼び出しショートカットは環境依存です。
ここに挙げた Cmd+Esc(Mac)/Ctrl+Esc(Windows/Linux)などは代表例として紹介しているに過ぎないため、利用前に拡張の設定画面や公式キーマップを確認して、必要に応じて自分のキーマップへ合わせてください。
会話履歴がエディタ内に残る点も見逃せません。
レビューで「この方針にした理由」をあとから見返せるので、単なる補完ツールではなく、作業ログの一部として機能します。
設計メモを別に起こさなくても、プランレビューの履歴がそのまま意思決定の痕跡になります。
Agent Teamsでの並列探索
Agent Teamsは、ひとつの問いに対して複数の探索を同時に走らせたいときに真価が出ます。
『Orchestrate teams of Claude Code sessions』 でも示されている通り、依存関係の調査、複数アプローチの比較、広いコードベースの探索分担のような並列探索向きの仕事で効果が出やすい機能です。
ひとつのセッションに全部を抱え込ませると、調査ログと仮説と差分案が混ざって読みにくくなりますが、役割を分けると論点が整理されます。
使い方は難しくありません。
こちらが明示的に「2チームで分けて調べて」と依頼することもできますし、Claude Code側から「この調査は分担したほうがよい」と提案される流れもあります。
たとえば依存ライブラリ更新の影響確認では、片方に破壊的変更の洗い出し、もう片方に既存ラッパー層への影響確認を任せると、主セッションは比較と意思決定に集中できます。
実務で体感差が大きいのは、重い探索をメイン会話から切り離せる点です。
いわゆる“Explore系サブエージェント”にログ漁りやコードサーチを任せ、メインでは結論だけを受け取る形にすると、会話の文脈が濁りません。
大量の検索結果や候補列挙を親セッションに積み上げるより、調査役と判断役を分けたほうが、あとから見返しても筋道が追えます。
リファクタ方針を二案並走で検討するときも、この形は強力です。
私がよくやるのは、Agent Teamsに「A案は単純置換」「B案はアダプター導入」で別々に走ってもらい、数分後に比較レビューだけ受け取る運用です。
A案は変更量が少ない代わりに拡張余地が狭い、B案は導入コストがある代わりに移行期間の安全性が高い、といった違いが短時間で並ぶので、会議前の意思決定が止まりません。
ひとりで順番に考えるより、比較軸が早く立ちます。
💡 Tip
調査そのものに価値がある仕事ほど、メインセッションに生ログを溜め込まず、探索担当のサブエージェントへ逃がすほうが結果が安定します。親セッションには「結論・根拠・懸念」だけを返す形が扱いやすいのが利点です。

Orchestrate teams of Claude Code sessions - Claude Code Docs
Coordinate multiple Claude Code instances working together as a team, with shared tasks, inter-agent messaging, and cent
code.claude.comMCPで外部リソース連携

MCPはModel Context Protocolの略で、モデルと外部ツールや外部データをつなぐための共通ルールです。
検索、ドキュメント参照、GitHub連携、ローカルファイル操作のような外部リソース連携を、個別実装ごとのばらばらな方法ではなく、標準化された形で扱えるのが利点です。
Claude Codeでいうと、手元のコードだけでは足りない情報を外から安全に取り込むための接続口だと考えると掴みやすいはずです。
使いどころは明快で、リポジトリ外の情報が判断材料になる場面です。
たとえばGitHub上のIssueやPRを参照したい、外部ドキュメントを引きたい、ブラウザ操作を伴う検証をしたいといったときに、MCPサーバー経由で必要なツールを足します。
検索系やドキュメント系のサーバーをつなぐだけでも、セッション内で完結する作業範囲が広がります。
最小の設定フローも整理されています。
プロジェクト単位なら、ルートに .mcp.json を置いて自動読み込みさせる形がわかりやすく、CLIから追加するなら claude mcp add の流れで登録できます。
設定を書いたあとにClaude Codeを起動し直すか、セッションを再開して読み込ませる、という順序で覚えておけば十分です。
起動時に設定ファイルを明示したいときは --mcp-config を使う手もあります。
ここで気をつけたいのは、MCPは「何でも接続できる便利機能」ではなく、外部入出力の境界を増やす仕組みだという点です。
『Claude Code のMCP説明』 にもある通り、ツールの無効化設定や出力制限の考え方が用意されています。
実務では、まず検索やドキュメント参照のように読み取り中心のサーバーから始め、役割が固まってから書き込み系を足すほうが運用が崩れません。
MCPの出力は会話コンテキストも消費するので、返す情報量が多いサーバーは「必要な項目だけ返す」設計のほうが扱いやすいのが利点です。

MCP を使用して Claude Code をツールに接続する - Claude Code Docs
Model Context Protocol を使用して Claude Code をツールに接続する方法を学びます。
code.claude.comSkillsで頻出作業を拡張
Skillsは、よく繰り返す作業の手順や判断基準を、再利用可能なパッケージとして持たせる仕組みです。
単なるテンプレート置き場ではなく、必要な場面で関連スキルを読み込み、作業フローを動的に拡張できるところが肝です。
定型レビュー、テスト生成、リリースノート整形、特定フレームワーク向けの実装手順のように、毎回似た判断をしている仕事ほど相性が出ます。
構成はシンプルで、スキル用フォルダの中に SKILL.md を置くのが基本です。
個人用なら ~/.claude/skills/、プロジェクト共有なら .claude/skills/ に置く形なので、チームでGit管理もしやすいのが利点です。
プロジェクト配下に置いておけば、「このリポジトリではレビュー時に何を見るか」「UI変更時にどの確認を先にするか」を、人ごとの暗黙知ではなく共有資産に変えられます。
実際には、長いスキルを増やせば強くなるわけではありません。
スキルは読まれて初めて意味が出るので、説明が長すぎると、そのぶん本題の文脈を押しのけます。
私が運用していて収まりがよいのは、1スキル1目的を崩さず、対象、手順、出力形式を短く固定する書き方です。
たとえば「PRレビュー用」「DBマイグレーション確認用」「UI文言変更チェック用」を分けておくと、必要な時だけ呼ばれます。
逆に「開発全般の万能ルール」を1本に詰め込むと、何を読ませたのか自分でも追えなくなります。
チーム共有では、SKILL.md の本文よりも description の切り方が効きます。
関連場面が伝わる説明になっていれば、自動で選ばれる場面が増えますし、手動で /skill-name を呼ぶときも迷いません。
運用が回っているチームほど、スキルは知識ベースというより「よくある判断の圧縮」に近い形へ落ち着きます。
Hooksによる前後処理の自動化

Hooksは、ツール実行の前後やセッション開始・終了時に、任意のシェルコマンドを差し込める拡張点です。
役割はわかりやすく、前処理・後処理・検証の自動化です。
たとえば編集直後に prettier を走らせる、特定コマンドの前に秘密情報の混入を検査する、終了時に作業サマリーをログへ追記するといった流れを組めます。
設定先は .claude/settings.json、個人だけで閉じたいものは .claude/settings.local.json が基本です。
手早く触るなら /hooks メニューから追加して、その場で有効化する流れが扱いやすいのが利点です。
代表的なイベントには PreToolUse、PostToolUse、SessionStart、Stop、SubagentStop などがあり、どこで何を差し込むかを分けられます。
導入時に差が出るのは、フックを重くしすぎないということです。
たとえば PostToolUse で編集のたびに重い検証を何本も走らせると、操作ごとに待ち時間が積み上がります。
軽い整形や短いチェックはフック向きですが、時間のかかる検証はCIや明示コマンドへ分けたほうが流れが詰まりません。
マッチャーで対象を Write|Edit に絞るだけでも、無駄な実行は減ります。
Hooksは便利ですが、実態はホスト上でコマンドを実行する仕組みなので、チーム運用では「何を自動で走らせるか」を小さく始めるほうが安定します。
まずは整形、簡単な検証、通知のように挙動が読みやすいものから入れると、仕組みそのものがブラックボックス化しません。
詳細なイベント設計や実例はClaude Codeの個別記事側で深掘りしたほうが収まりがよく、この段階では「前後処理をコードで固定できる」と捉えておけば十分です。
セキュリティと安全運用
読み取り専用と承認フロー
基本は読み取り専用で始め、ファイル編集やシェルコマンド実行はその都度明示的に承認する運用を推奨します。
承認フローは副作用の可視化装置として使い、慣れてから許可範囲を段階的に広げると安全性が保てます。
権限確認ダイアログも、ただの「OK/キャンセル」ではなく、何をしようとしているのかを読み解く前提で見ると意味が変わります。
典型的には、対象がファイル編集なのか、シェルコマンド実行なのか、どのパスに影響するのかが表示され、こちらは承認・拒否に加えて、適用範囲を細かく切る判断を取れます。
単発で1回だけ通すのか、同種の操作に限って許すのか、逆にこの操作系は継続して拒否するのか、という粒度で考えると運用が安定します。
スクリーンショットを入れるなら、操作内容、対象パス、承認ボタン、拒否ボタン、そして「この範囲だけ許可」のような細粒度オプションが一目でわかる切り取り方が収まりのよい見せ方です。
ここで覚えておきたいのは、承認フローは作業の邪魔ではなく、副作用の可視化装置だという点です。
慣れてくると承認回数を減らしたくなりますが、最初に見えた危険な導線を把握してから絞るほうが、運用全体の再現性が上がります。

セキュリティ - Claude Code Docs
Claude Code のセキュリティ対策とセキュアな使用方法のベストプラクティスについて学びます。
code.claude.comサンドボックスと境界

編集やコマンド実行を許す場面でも、実行場所の境界は別に持っておく必要があります。
Claude Codeでは、コマンド実行を前提にするときもサンドボックス化された bash を軸に考えるのが安全側です。
さらに、書き込み可能な範囲を作業ディレクトリ内に閉じ、作業ディレクトリ外への書き込みを制限しておくと、誤操作の被害が横へ広がりません。
この境界は、地味ですが効きます。
たとえばコード整形、テスト生成、一括置換のような作業は、対象が広がるほど成果も大きくなりますが、同時に誤爆の半径も広がります。
作業ディレクトリの外、たとえばホーム配下の別プロジェクトや共通設定領域に書き込めない状態なら、最悪でも被害は今いるリポジトリに留まります。
事故対応でいちばんつらいのは「何がどこまで触られたか」を追う時間なので、境界を先に固定しておく意味は大きいです。
HooksやSkillsを組み合わせる場面では、この発想がさらに効きます。
どちらも実体としてはホスト側でコマンドやスクリプトに接続するため、見かけ上は便利な自動化でも、境界なしで広く実行できる状態は避けたいところです。
サブエージェントや分離コンテキストを使う設計が紹介されるのは、単に整理のためではなく、信頼度の低い処理を本流から切り離すためでもあります。
読み取り中心の調査と、実際に変更を加える作業を同じレーンで流さないだけでも、運用の手触りは変わります。
💡 Tip
調査、要約、差分確認のような仕事は読み取り専用のまま回し、編集と実行は承認付きの別フェーズに分けると、作業速度より先に安全側の型が固まります。
危険ファイル・設定のレビュー習慣
事故の入口になりやすいのは、ソースコード本体より設定ファイルや補助ディレクトリです。
とくに .claude/、.vscode/、package.json の scripts、CI設定は、見た目が設定でも実際には「何かを実行する導線」を抱えています。
ここをコード本体と同じ熱量で読む習慣がないと、意図しないコマンド実行や秘密情報の露出につながります。
.claude/ 配下では、settings.json や settings.local.json にフック設定や許可ルールが入り得ますし、.claude/skills/ の SKILL.md や付随スクリプトは、作業手順の顔をしながら実行可能な導線を含みます。.vscode/ では tasks.json や launch.json が、開発支援の名目でローカルコマンド実行の窓口になります。package.json の scripts は説明不要で、postinstall やテスト補助スクリプトに副作用が紛れ込む余地があります。
CI設定も同様で、ワークフロー変更はリポジトリ外の認証情報やデプロイ動線に接続しがちです。
この種のファイルは、内容を全部暗記する必要はありません。
見る観点を固定すると漏れが減ります。
私がまず追うのは、自動実行されるか、外部通信があるか、秘密情報に触れるか、書き込み先が広がるかの4点です。
設定ファイルの差分で行数が少ないと、つい「軽い変更」に見えますが、実際には1行で挙動を変えられる場所ほど危険度は上がります。
設定やプロジェクトファイル経由のリスクは、現実の脆弱性研究でも繰り返し指摘されてきました。
RCEやAPIトークン流出の足場は、派手なバイナリではなく、設定と実行導線の接合部に置かれることが多いからです。
レビュー時に拾う項目を固定しておくと、見落としは減ります。
.claude/に新しい Hook、Skill、ローカル実行前提の設定が追加されていないか- MCP 関連設定や環境変数注入で、不要な外部接続や権限拡大が起きていないかを確認してください。
こうしたレビューは、セキュリティ担当だけの仕事として切り出すより、通常のコードレビューに混ぜてしまったほうが続きます。
設定ファイルは「動く仕様書」なので、仕様変更として読む癖をつけたチームのほうが崩れません。
危険フラグの扱い

権限確認を飛ばすフラグは、速度の代わりに事故確率を引き上げます。
たとえば --dangerously-skip-permissions のような名前の通り危険性を明示したフラグは、初心者向けの導入フローには入れないほうが筋が通ります。
承認を省略した瞬間、これまで人間が最後に見ていた境界が消えるからです。
こうしたフラグを使う場面があるとしても、それは隔離環境の中に限定した話です。
たとえば使い捨ての検証用コンテナ、読み取り専用ファイルシステム、限定されたCI環境のように、失敗しても外へ広がらないガードが先にある構成でないと釣り合いません。
ローカル開発環境で普段使いする設定として扱うと、1回の成功体験がそのまま常態化し、レビューも承認も抜け落ちていきます。
危険フラグが怖いのは、露骨な破壊コマンドだけではありません。
設定変更、補助スクリプト更新、フック追加のような「一見地味な変更」が、そのまま実行面に接続されるところです。
だからこそ、読み取り専用を基準にし、編集と実行を承認付きで切り分け、境界はサンドボックス側に寄せる、という基本形が崩れない運用に価値があります。
便利さは後から足せますが、事故の学習コストは一度払うと重く残ります。
コスト・使用量・チーム導入時の見方
API課金 vs サブスクの見方
Claude Codeの費用感は、APIを従量で使っているのか、Claude ProTeamEnterpriseのようなサブスクで使っているのかで、見るべき数字が変わります。
ここを混ぜてしまうと、同じ「使用量」でも意味がずれて判断を誤ります。
API利用では、まず見るべきなのは実際にいくら発生したかです。
AnthropicのClaude Codeドキュメントでは、API利用時の平均コストは1人あたり1日平均6ドル、利用者の90%は1日12ドル未満という目安が示されています。
開発者数と稼働日数が読めるチームなら、この数字は導入初期の予算感を置く材料になります。
モデル単価の感覚もあわせて持っておくとぶれません。
たとえばSonnet 4.6は入力100万トークンあたり3ドル、出力100万トークンあたり15ドル、Opusは入力100万トークンあたり5ドル、出力100万トークンあたり25ドルという整理です。
長い出力を多く返す運用ほど、効いてくるのは入力より出力側です。
一方で、サブスクは見方が違います。
個人向けのClaude Proは公式サイトで月20ドル、チーム向けのTeam Premiumは1人あたり月150ドルという整理が流通しています。
どちらも価格ページの更新があり得るので、2026年3月時点の把握としての数字です。
サブスクでは、APIのように「1回の実行でいくら乗ったか」を追うより、固定費に対してどれだけ仕事が前に進んだかを見るほうが実務的です。
この違いを雑に言い換えると、API契約では「今日の費用」、サブスクでは「今月の回収具合」が主語になります。
個人なら、試行錯誤が多くて使う日と使わない日の差が大きいならAPIの数字が効きます。
チームで毎日触る人が増えるほど、サブスクの固定費で平準化したほうが管理しやすい場面が出てきます。
逆に、全員へ一律に配る前に、まず数人で集中的に使わせて使いどころを固めるならAPIのほうが輪郭が見えます。
私が運用で見ているのは、金額そのものよりも「何にどれだけ使ったか」が説明できるかです。
日次の使い道を週1で見直して、CLAUDE.mdの改善と並走させると、同じ調査を何度もやり直すような無駄な探索が減ります。
すると費用も使用量も、自然に暴れにくくなります。
コスト管理は節約テクニックというより、指示と前提の整備が効いているかを見る鏡に近いです。
/costと/statsとAnalytics

コストや使用量を追うときに混同しやすいのが、/cost と /stats とチーム向けAnalyticsの役割です。
名前が近いぶん迷いやすいのですが、見ている層が違います。
/cost は、課金実績の把握に向く見方です。
API利用時には「この使い方で実際にいくらかかったか」を押さえる軸になります。
モデル選択や出力量の重さがそのまま費用へ返ってくる契約では、まずこちらが基準です。
費用を締める場面では、長い調査をSonnet 4.6に寄せるのか、難所だけOpusへ切り替えるのかといった判断に直結します。
/stats は、使用傾向の把握に向く見方です。
どれだけ使ったか、どの時間帯やどの作業で伸びるのか、探索の偏りがないかを見るならこちらです。
サブスクでは特に、追加課金の明細というより、使われ方の偏りや過不足を掴む道具として意味があります。
席はあるのに誰も深く使えていないのか、逆に一部メンバーへ利用が集中しているのかは、契約の良し悪しより運用設計の問題であることが多いからです。
チーム導入ではAnalyticsも見逃せません。
AnthropicのAnalytics説明では、有効化後は24時間以内に表示が始まり、以後は毎日更新されます。
つまり、当日中の細かな最適化より、週単位で傾向を見るための道具です。
導入初週から日ごとの揺れを追い詰めるより、数営業日ぶんを溜めてから、使われた機能や利用の分布を読むほうが実態に合います。
サブスク契約のチームなら、中心に置くのは \/stats\` とAnalyticsです。/cost
API契約のチームなら、 を軸にしつつ \/stats\` で使い方の癖を補足する、という並びになります。
ここでもポイントは、契約形態に合わない指標を主役にしないことです。
固定費のプランで1回ごとの費用を細かく追っても判断が散りますし、従量課金で「なんとなく活用されている」で済ませると予算の線が引けません。
ROI/KPI設計
チームで入れるときに難しいのは、費用を出すことより回収できていると言える物差しをどう置くかです。
Claude Codeは会話ツールというより、調査、編集、テスト、差分確認までをまたいで仕事を前へ進める道具なので、単純に「生成回数」だけをKPIにすると現場の感覚とずれます。
ROIを見るなら、まずは開発フローのどこを短くしたいのかを分けたほうがきれいです。
たとえば、調査の立ち上がり時間を縮めたいのか、複数ファイル修正の往復を減らしたいのか、レビュー前のセルフチェックを厚くしたいのかで、効く指標は変わります。
ここにコスト指標を1本だけ当てると、便利だが高い、安いが効いていない、のような粗い評価になりがちです。
実務では、DORAメトリクスやスプリント速度を併用する見方が噛み合います。
たとえば変更リードタイム、デプロイ頻度、変更失敗率、復旧時間のような指標は、「AIを入れた結果、開発プロセスのどこが改善したか」を見るのに向いています。
スプリント単位なら、完了ストーリー数や持ち越し率、レビュー待ち時間、バグ修正の再オープン率と組み合わせると、導入効果が“気分”ではなく“流れ”で見えてきます。
ここで効くのは、AI専用の新しい指標を増やしすぎないということです。
チームの既存KPIに、Claude Codeの利用量と成果物の変化を重ねるほうが運用負荷が低く、解釈もぶれません。
たとえば「レビュー前にテストまで通したPRの比率が上がった」「初回調査から修正提案までの往復が減った」「大型リファクタで担当者の抱え込みが減った」といった変化は、使用量だけでは見えませんが、現場の生産性には直結します。
数字の置き方としては、費用、利用傾向、開発フロー指標の3層で持つと収まりがいいです。
APIなら \/cost\` が費用レイヤー、\/stats\` が利用レイヤー、DORAやスプリント速度が成果レイヤーです。
サブスクなら費用レイヤーは席単価がほぼ固定なので、利用レイヤーと成果レイヤーの比重が上がります。
ここで「何件プロンプトを打ったか」より、「どの工程が短くなったか」を先に見るほうが、チーム導入の説明が通ります。
💡 Tip
チームでのROIは、利用量だけでは読めません。費用、使用傾向、開発フロー指標を並べると、「使っているのに効いていない」と「使っていないのに席だけある」が分かれて見えてきます。
セッション制限と長時間タスクの扱い

費用やROIの話とセットで見ておきたいのが、長時間タスクを1本のセッションに載せすぎないということです。
Claude Codeは長い文脈を扱えますし、記事や実践知では200,000トークン級のコンテキスト言及もあります。
ただ、長い入力を持てることと、長い仕事を一気に流すことは同じではありません。
まず、モデル別の価格感を見ると、長文生成は出力側のコストが積み上がります。
とくにOpus系は出力単価が高く、難しい設計判断や詰まった調査で威力を発揮する一方、だらだら長く書かせる運用とは相性がよくありません。
Opus 4.6で出力上限の拡張が話題になる場面でも、実務では「一発で全部を書かせる」より、章立てや作業単位で分割したほうが扱いやすいのが利点です。
設計レビュー、差分案、テスト追加、ドキュメント更新のように区切ると、失敗時の手戻りも小さくなります。
セッション枠の存在も無視できません。
2025年8月末以降の利用制限として、5時間セッション枠に触れる整理が出回っており、長時間張りつく運用には上限意識が必要です。
ここで詰まりやすいのは、巨大な移行作業を1セッションで完結させようとするケースです。
認証移行、テスト刷新、設定見直しを全部ひとまとめにすると、文脈も判断も肥大化して、途中で精度が落ちやすくなります。
実務では、長時間タスクは分割と自動化に逃がすのが定石です。
調査フェーズ、変更フェーズ、検証フェーズを分け、繰り返し部分はHooksやスクリプトへ寄せると、1回ごとの会話が短く保てます。
大規模修正も、モジュール単位、ディレクトリ単位、PR単位で区切ると追跡が効きます。
長文の生成物も、アウトライン、各章ドラフト、統合レビューの3段に分けるだけで、トークン消費も見通しも整います。
この分割運用は、コスト対策だけではありません。
セッションが長引くほど、最初に置いた前提と途中で増えた前提が混ざり、どこで判断がぶれたのか追いにくくなります。
短い単位で閉じると、\/stats\`` でも使い方の癖が見えますし、チームAnalyticsとも照合しやすくなります。
費用管理、品質管理、運用管理がここでつながります。
よくあるつまずきと対処法
権限確認の負担を下げる
導入直後につまずきやすいのが、権限確認ダイアログの多さです。
読み取り、編集、コマンド実行が一つの流れでつながるClaude Codeでは、安全側に倒した確認が入るぶん、最初は「賢いけれど会話の腰が折れる」と感じやすくなります。
ここで効くのは、毎回その場で細かく判断するより、承認の単位を先に設計しておくことです。
実務では、修正を一気に広げるほど確認回数も判断負荷も増えます。
私自身、気になる点を全部まとめて直させるより、3〜5ファイル単位で小さく区切って承認したほうが事故が減り、結果として早く終わる場面が多いと感じています。
差分確認も追いやすく、テスト失敗時の切り戻し範囲も狭く保てるからです。
そのうえで、CLAUDE.md に「どこまでなら自動で進めてよいか」を先に書いておくと、対話の往復が減ります。
たとえば「テストは npm test まで許可」「依存追加は提案止まり」「本番設定ファイルは必ず事前確認」のように境界線を明記しておくと、判断が毎回ゼロからになりません。
AnthropicのClaude Codeドキュメントでも、プロジェクト固有の方針を明文化しておく運用が前提になっています。
初回起動では、CLI の画面文言が不安を和らげるかどうかも案外大きいです。
たとえば「このセッションでは読み取り中心で開始し、編集やコマンド実行の前に確認する」といった案内が先に見えるだけで、いきなり書き換えられる印象が薄れます。
記事や社内手順に載せるなら、起動直後のプロンプト例と、権限確認ダイアログがどの操作で出るかを示した画面イメージがあると、最初の心理的ハードルが下がります。
コンテキスト肥大化への対処

もう一つ、使い始めの段階で精度が落ちたように見える原因がコンテキストの膨張です。
Claude Codeは長い文脈を扱えますが、持ち込めることと、持ち込むべきことは別です。
関係の薄いファイルやログまで抱え込むと、肝心の判断材料が埋もれます。
対処の基本は、重要ファイルだけを明示的に渡すということです。
ルートの README、該当モジュール、テスト、設定ファイルのように、判断に必要な起点を @ 参照で絞って渡すだけでも会話の解像度が変わります。
たとえば認証バグの調査なら、@src/auth/ と @tests/auth/、@package.json だけを先に見せ、そのあと必要に応じて範囲を広げるほうが、最初からリポジトリ全体を読ませるより筋が通ります。
不要ディレクトリの除外も効きます。node_modules、ビルド成果物、生成済みドキュメント、巨大ログは、調査の邪魔になることのほうが多いです。
MCP 出力についても、ツール出力が大きくなると警告が出る設計になっています。
長い出力をそのまま会話に流し込むより、先に要約を作ってから本題へ戻したほうが、後段の編集やレビューが安定します。
要約投入も定番です。
長い issue や調査ログを丸ごと貼る代わりに、「再現条件」「原因候補」「未確認点」の3点だけに縮めて渡すと、モデルが保持すべき前提が整理されます。
探索だけをさせたい場面では、メインの修正セッションに混ぜず、Explore 系のセッションへ切り出して調査結果だけ持ち帰る運用が合います。
コード変更の会話と探索の会話を分けるだけで、文脈の混線が減ります。
💡 Tip
調査、変更、検証を同じ会話に積み上げるほど、途中で増えた前提が埋もれます。探索用の短いセッションで要点を作り、修正用のセッションに戻す流れのほうが差分レビューまで崩れません。
Windows特有の差分対応
Windowsでは、導入自体より周辺の差分で止まりやすいのが利点です。
とくにシェルの挙動とパス表記、改行コードは最初に揃えておかないと、ツール実行やフックで思わぬ詰まり方をします。
日常運用ならGit BashかWSL 2を使う構成のほうが話が早く、シェル前提のコマンド例とも噛み合います。
パス問題は、バックスラッシュ混在よりスラッシュ基準で寄せたほうが安定します。
フックやスクリプトの中で相対パスを優先し、絶対パス依存を減らすだけでも崩れ方が減ります。
改行コードは LF に寄せておくと、差分が不要に膨らみにくく、整形ツールとも衝突しにくくなります。CRLF が混ざると、実質無変更でもファイル全体が書き換わったような差分になり、権限確認やレビューの負担まで増えます。
GPU やドライバまわりは、Claude Codeそのものより、周辺ツールやテスト実行で顔を出します。
たとえばPlaywrightやローカル推論系の補助ツールを併用していると、描画や依存ライブラリで止まることがあります。
こういうときは本体の問題と切り分けて、まずシェル、Node、Git の基本動線が通っているかを見るほうが詰まりをほどきやすくなります。
大規模リポでの除外設計
モノレポや長寿命リポジトリでは、「全部見せたほうが賢くなる」という発想が逆効果になりがちです。
実際には、巨大な依存ディレクトリや生成物、バイナリが混ざるだけで探索コストが跳ね上がり、必要なファイルへ到達するまでの往復も増えます。
運用としては、node_modules、ビルド成果物、キャッシュ、巨大バイナリを既定で除外し、必要になった時点で範囲を狭く開けるほうが安定します。
つまり「最初は閉じておく」が基本です。
たとえば packages/web/src だけ、services/api/auth だけ、といった形で問題のある場所から順に開くと、差分と会話の両方が締まります。
この考え方は、MCP や Skills を足したあとほど効きます。
周辺機能が増えるほど、読み込める情報量ではなく選ぶ情報の質が効いてくるからです。
大規模リポジトリでうまく回っているチームほど、広く読ませるより、対象ディレクトリ、関連テスト、設定ファイルの三点セットに絞って作業を始めています。
広範囲の検索は調査セッションに寄せ、実際の編集セッションでは対象を細くする。
この切り分けだけで、導入直後の「思ったより散らかる」を避けやすくなります。
旧版からの移行注意

古い npm 経由の導入履歴が残っている環境では、移行時にコマンド衝突が起きやすいのが利点です。
表面上は claude が起動していても、実際には別の場所に残った旧版バイナリを拾っていることがあります。
ここで挙動が不安定だと、設定ミスなのかバージョン混在なのか判別しづらくなります。
移行時は、アンインストール、パス確認、再ログインの3点を一続きで見るのが定石です。
旧版のグローバルパッケージを外したあと、どの claude が解決されているかを確認し、シェルを開き直して認証状態を取り直す流れにすると、混線が残りにくくなります。
GitHubの変更履歴やコミュニティ記事でも、v1.0.24 や v2.0.74 のように系統の異なる版が話題になる時期があり、古い手順のまま更新だけ重ねた環境では差異が残りやすいことが見て取れます。
社内展開やオンボーディング資料では、この部分だけは短いチェックリスト化が向いています。
- 旧版の npm グローバル導入を削除する
claudeコマンドの解決先を確認する- シェルを再起動する
- 再ログインして認証状態を揃える
- 初回起動で表示される権限確認の流れを確認する
導入直後の離脱は、派手な失敗より「動いてはいるが、なんとなく不安」という状態から起こります。
権限確認の回数、文脈の膨らみ方、OS差分、除外設計、移行時の混線を先回りで潰しておくと、最初の1週間で手応えが出やすくなります。
はじめの1時間:チェックリストと次のアクション
この1時間で狙うのは、全部を理解することではありません。
Claude Codeに対して「読ませる」「直させる」「試させる」「途中から再開する」という最小ループを一度通し、どこで迷うかを自分の環境で把握するということです。
初回は空振りしても構いませんが、操作の順番だけは固定しておくと、2日目からの立ち上がりが目に見えて軽くなります。
導入チェックリスト10項目
最短で立ち上げるなら、次の10項目を上から順に潰していくのが確実です。ここでは「導入できたか」ではなく、「実務の入口まで通ったか」を確認します。
- 自分の OS に合わせてClaude Codeをインストールする
macOSLinuxWindowsで入口は異なります。
とくにWindowsは前述の通りGit BashかWSL 2を前提にしたほうが、後続のコマンド例と噛み合います。
- ターミナルで対象リポジトリを開き、
claudeを起動する
ここで起動できれば、以後の確認はその場で進められます。旧版が残っている環境は、前のセクションで触れた解決先の確認を先に済ませておくと混線しません。
- まずは質問だけさせる
いきなり編集に入らず、「このリポジトリの構成を3点で説明して」「認証まわりの入口ファイルを探して」のような探索から始めます。
読み取りだけの会話で、返答の粒度と探索範囲の癖をつかみます。
- 小さな編集を1つだけ依頼する
コメント修正、文言統一、型の小修正など、差分を一目で追える作業を選びます。
初回から複数ファイルの構造変更を投げるより、どのように提案し、どの単位で直すかを見るほうが後の事故が減ります。
- テスト実行まで通す
編集後に関連テストか既存の検証コマンドを実行させます。
修正だけで終えると、作業の半分しか体験できません。
読み取り、変更、検証まで一続きで動くことを確認しておくと、実務投入の判断がぶれません。
- セッション再開を一度試す
途中で閉じた作業を再開できるかは、日常運用で効く部分です。短い会話でも一度中断し、再開して文脈がどう戻るかを見ておくと、長時間作業の設計が組みやすくなります。
- プロジェクトルートに
CLAUDE.mdの雛形を置く
最初は長文にせず、プロジェクト概要、作業ルール、テスト方針の3ブロックだけで十分です。空のまま使うと毎回同じ前提説明を繰り返すことになります。
- 権限確認の出方を把握する
どの操作で確認が出るか、どの場面で止まるかを見ます。ここを体で覚えておくと、「止まったから壊れた」と誤解せずに済みます。
- コスト確認の入口を押さえる
API 利用では、会話の質だけでなく利用量の見方も初日から揃えておくべきです。
AnthropicのClaude Codeドキュメントでは、API 利用時の平均コストは1人あたり1日平均6ドル、90%のユーザーは1日12ドル未満という目安が示されています。
初回は「高いか安いか」を判断するより、どの作業で伸びるのかを見る視点を持つほうが効きます。
- Analytics と
/statsを確認して初日を閉じる
チームならAnalyticsが通常24時間以内に反映される前提を知っておくと、数字がすぐ出なくても慌てません。
個人でも、その日の終わりに /stats を開いて「何に時間を使ったか」を振り返る習慣をつけると、2週目に入ったあたりから無駄な探索と長すぎる依頼文が目に見えて減っていきます。
💡 Tip
初回は「質問だけ」「1ファイル編集」「テスト1本」の3点に絞ると、操作の詰まり場所がはっきり出ます。広く試すより、短い往復を一度きれいに通すほうが次の改善につながります。
ここまで通れば、導入作業は終わりではなく、すでに小さな運用開始です。
私自身、初日は機能を増やすよりも、この10項目を崩さず通すことを優先します。
そのほうが、翌日からMCPやHooksを足したときに、どこで複雑さが増えたのか切り分けられるからです。
最初の3プロンプト例
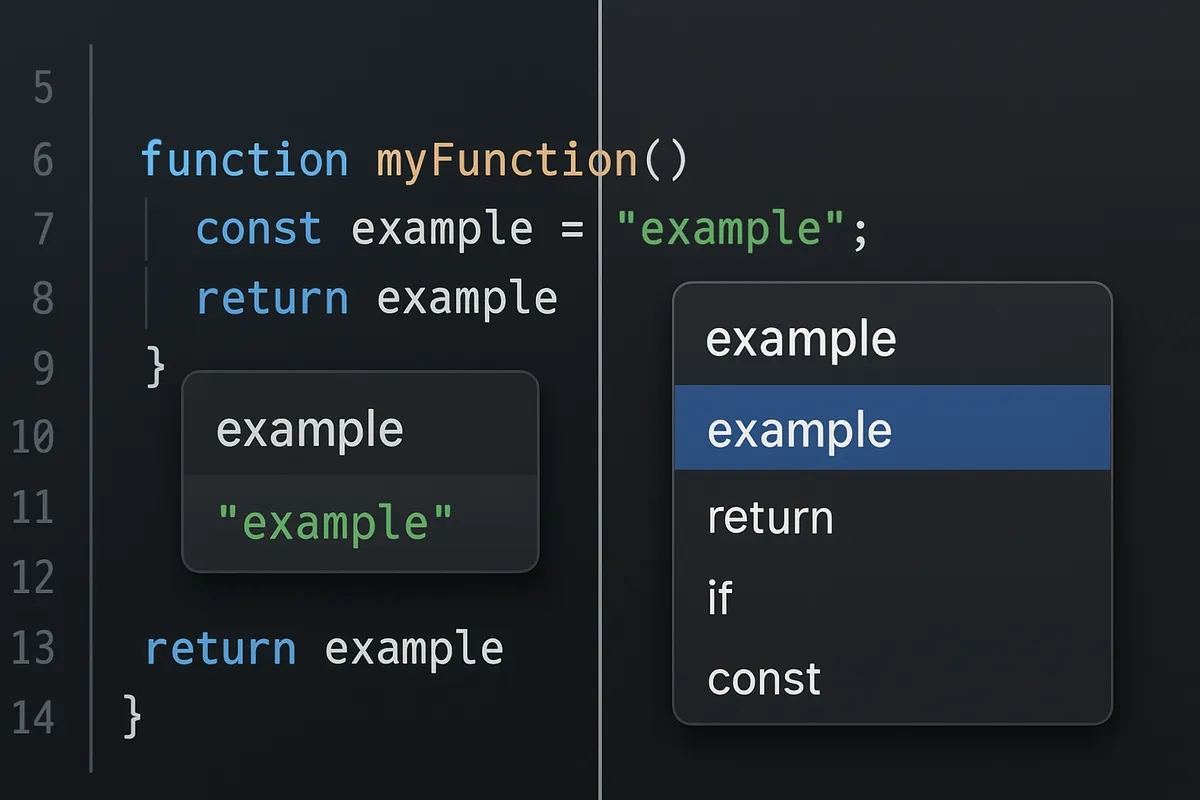
最初のプロンプトは、賢そうに見えるものより、返答の質を観察できるものが向いています。最初の1時間なら、この3本で十分です。
1本目は、リポジトリの地図を作らせるための要約です。
このリポジトリの目的、主要ディレクトリ、開発時に最初に読むべきファイルを要約してください。
出力は「概要」「重要ディレクトリ」「最初に見るファイル」の3項目に分けてください。
推測ではなく、確認できたファイル名ベースで答えてください。この依頼で見たいのは、表面的な README 要約で終わるか、実際にコードを横断して骨格を掴みにいくかです。
ここで雑な要約しか返らない場合は、対象ディレクトリを狭めて再依頼したほうが、その後の編集精度も上がります。
2本目は、失敗テストの原因特定です。
失敗しているテストを特定し、原因候補を3つに絞ってください。
各候補について、根拠になったファイルと確認したい追加ポイントを添えてください。
まだコードは変更せず、調査結果だけを返してください。この形にすると、いきなり直しに行かず、仮説と根拠を分けて返させられます。
調査と変更を混ぜると会話が膨らみやすいので、前のセクションで触れた探索セッションの切り分けとも相性が良いです。
3本目は、小さな修正とテストの実行です。
上の調査結果をもとに、最も影響範囲が小さい修正案を1つだけ実装してください。
修正後に関連テストを実行し、変更ファイル、実行コマンド、テスト結果を簡潔に報告してください。
想定外の変更が必要なら実装前に止まって相談してください。この依頼で確認できるのは、差分の節度です。
複数案を一気に飲み込ませると、初回は「直ったが広く触りすぎた」という状態になりがちです。
1つだけ実装させると、レビュー負荷も低く、権限確認の流れも追えます。
次に読むべき記事と拡張の順番
最初の1時間が終わったら、次は道具を足す順番を間違えないことが効いてきます。
Claude Codeは CLI を軸にすると全体像が見えますが、常用する窓口は人によって違います。
まずは使い分けを短く整理しておくと、次に読む記事も迷いません。
| 入口 | 向いている場面 | 先に触るべき人 |
|---|---|---|
| CLI | 調査、複数ファイル修正、テスト実行、Git 操作まで一気に回す | まず全体像をつかみたい人 |
| IDE | 日常編集に寄せながらClaude Codeを使いたい | エディタ中心で開発している人 |
| Desktop / Browser のClaude | 相談、文章整理、軽い設計相談 | コード変更前に考えをまとめたい人 |
CLI で基本操作が通ったあと、日常の編集導線を短くしたいなら、まずは 公式の VS Code / Editor 連携ドキュメントを参照してください(各エディタ向けの公式手順に従うのが確実です)。
当サイトは現時点で内部の連載記事を公開していないため、公開済みの記事が整い次第、ここにリンクを追加します。
AIビルダーの編集チームです。AI開発ツールの最新情報と使い方を発信しています。
関連記事
MCP接続トラブル対処|5層で原因特定
MCP接続トラブル対処|5層で原因特定
MCPサーバーを追加したのに、接続できない、認証が通らない、ツールが出てこない。そんな詰まり方は、設定を総当たりで触るより、Host・Client・Server・Transport・Authorization のどこで止まっているかを順に切り分けたほうが早く抜けられます。
MCPサーバー設定 入門|AI連携の始め方
MCPサーバー設定 入門|AI連携の始め方
MCPは、AIアプリと外部ツールやデータソースをつなぐ共通規格で、チャットの外にあるファイル、API、業務システムを同じ作法で扱えるようにする土台です。私も最初はローカルのMarkdownメモをFilesystem系サーバーで読ませるところから始めましたが、設定を足して再起動するとツール一覧に現れ、
Claude Code VS Code連携の設定と使い方
Claude Code VS Code連携の設定と使い方
『VS Code』で『Claude Code』を使い始めるなら、いちばん近道なのはVisual Studio Marketplaceから公式拡張を入れて、そのままパネルを開く流れです。
Claude Code vs Cursor 比較|違いと使い分け
Claude Code vs Cursor 比較|違いと使い分け
Claude Codeと『Cursor』はどちらもAIで開発を加速できる道具ですが、触ってみると得意な仕事がはっきり違います。VS Code歴の長い筆者は両方を試してきましたが、細かな実装修正をテンポよく詰める場面では『Cursor』の即応性が気持ちよく、