MCPサーバー設定 入門|AI連携の始め方
MCPサーバー設定 入門|AI連携の始め方
MCPは、AIアプリと外部ツールやデータソースをつなぐ共通規格で、チャットの外にあるファイル、API、業務システムを同じ作法で扱えるようにする土台です。私も最初はローカルのMarkdownメモをFilesystem系サーバーで読ませるところから始めましたが、設定を足して再起動するとツール一覧に現れ、
MCPは、AIアプリと外部ツールやデータソースをつなぐ共通規格で、チャットの外にあるファイル、API、業務システムを同じ作法で扱えるようにする土台です。
私も最初はローカルのMarkdownメモをFilesystem系サーバーで読ませるところから始めましたが、設定を足して再起動するとツール一覧に現れ、読み取り専用のまま安全に動作を確かめられたので、導入の最初の一歩として筋がいいと実感しました。
この記事は、これからVS Codeや各種AIクライアントでMCPを試したい人に向けて、まずはローカルのFilesystem系サーバーを最小権限で入れる順序、そのうえで設定ファイルにサーバー定義を追加し、クライアントを再起動し、UIで有効化を確認するという共通パターンを軸に整理します。
あわせて、標準入出力で手元のプロセスとつなぐstdioと、リモート運用を前提にしたStreamable HTTPの違いも、『Model Context Protocol公式ドキュメント』や『VS CodeのMCP解説』で確認できる考え方に沿って図解イメージでつかめるようにします。
その結果、読者自身が「最初の一台」を迷わず選べる状態まで持っていきます。
MCPサーバーとは?AI連携の基本を最初に整理

MCPはModel Context Protocolの略で、AIモデルと外部のツールやデータソースをつなぐためのオープンな共通規格です。
ポイントは、MCPサーバーそのものがAI本体ではなく、AIアプリが外の世界に手を伸ばすための標準化レイヤーだという点にあります。
ホストとなるAIアプリの中にMCPクライアントがあり、そのクライアントが外部のMCPサーバーへ接続する構図です。
この役割分担は、言葉を正確に押さえると混乱しません。
まずホストはVS CodeやClaude系クライアントのような、ユーザーが直接触るAIアプリです。
そのホストの内部にMCPクライアントが組み込まれていて、サーバー一覧を読み込み、接続し、利用可能な機能をAIへ渡します。
そして外側にいるMCPサーバーが、実際のツール実行やデータ参照の窓口になります。
図にすると、ホストの内側にMCPクライアントがあり、その外側にMCPサーバーが配置されるイメージになります。
ユーザー → ホスト(AIアプリ) → ホスト内のMCPクライアント → 外部のMCPサーバー → ファイル・API・業務システム という並びです。
サーバーがホストに埋め込まれているのではなく、ホスト内のクライアントがサーバーへ接続する、ここが理解の芯になります。
この構造をAPI連携と見比べると、MCPはAPIの置き換えというより、APIやローカル機能をAI向けにそろった作法で扱うための規格だと捉えると腹落ちします。
たとえばGitHubのAPIや社内の検索APIがすでに存在していても、そのままではAIが「何を読めるのか」「どの操作を許されているのか」を統一的に扱いづらい場面があります。
MCPサーバーを間に挟むと、そのAPIをToolsやResourcesとして整理して渡せるので、ホスト側は接続先ごとに別実装を増やさずに済みます。
短いたとえ話を入れるなら、MCPサーバーはUSB-Cハブに少し近い存在です。
ノートPC本体がホスト、そこに内蔵された接続制御がMCPクライアント、ハブの先にぶら下がるHDMIやUSBメモリのような外部機能がToolsやResourcesに当たります。
ただし主役は比喩ではなく規格の理解で、実際には標準化されたインターフェース越しに、ホスト内のクライアントが外部サーバーとやり取りするという説明のほうが正確です。
私自身、ToolsとResourcesの両方を出しているサーバーを触ったときに、この設計の気持ちよさを実感しました。
AIが先にResourcesで仕様書や社内メモを読み、その内容を踏まえてToolsでファイル更新やAPI実行に進む流れが自然で、提案の順番が「参照してから操作する」形にそろいます。
単にボタンが増える感じではなく、AIの思考手順そのものが整う感覚があり、MCPサーバーの価値はここにあると感じました。
MCPサーバーが提供できる3機能
Model Context Protocolの公式ドキュメント(Build an MCP server)では、MCPサーバーが提供する代表的な機能はTools、Resources、Promptsの3つに整理されています。
名前はシンプルですが、役割は明確に分かれています。
Toolsは、AIが外部に対して何かを実行するための操作です。
例: GitHubのissueを作成する、ローカルのMarkdownファイルを書き換える、価格APIを呼び出す。
Resourcesは、AIが判断材料として読む参照データです。
例: プロジェクトのREADME、社内ドキュメント、ディレクトリ内の設定ファイル、ナレッジベースの記事。
Promptsは、作業の型を渡す定型プロンプトです。
この3つを分けて考えると、MCPサーバーの設計意図も読み取りやすくなります。
Toolsだけなら「実行エンジン」、Resourcesだけなら「外部知識の供給源」に見えますが、両方を備えるとAIはまず資料を読み、次に必要な操作を提案し、承認後に実行するという流れを取りやすくなります。
Promptsまで加わると、同じ接続先に対して毎回ゼロから指示を書かなくても、作業パターンごと再利用できます。
なお、MCPの仕様は固定されたままではなく更新が続いています。
2026年3月5日更新のModel Context Protocolロードマップでは、『Roadmap - Model Context Protocol』にある通り、Streamable HTTPのスケーリングに加えて、認証の企業管理や監査証跡の強化といった運用面の進化もテーマとして示されています。
こうした流れを見ると、MCPサーバーは個人のローカル実験だけでなく、チームや企業で扱う接続基盤として整備が進んでいる段階だと捉えられます。

Roadmap - Model Context Protocol
Our plans for evolving Model Context Protocol
modelcontextprotocol.ioMCPとAPI連携は何が違うのか

ここで整理したいのは、MCPはAPIの代わりではないという点です。
APIはもともとアプリ同士をつなぐための入口で、RESTでもGraphQLでも社内CLIでも、それぞれが独自の呼び出し方や認証方法を持っています。
一方のMCPは、そうした既存のAPIやローカル機能をAIが扱いやすい形にそろえる共通インターフェース層です。
Model Context ProtocolのBuild an MCP serverでも、MCPサーバーがToolsResourcesPromptsを公開できる前提で整理されており、AIクライアントはその共通ルールに沿って外部機能を利用します。
この違いは、実際に複数の連携先をまたぐと見えやすくなります。
たとえばGitHubのAPI、社内の承認CLI、SaaSの検索APIをそれぞれ個別につなぐ構成だと、AI側は連携ごとに呼び出し方法や返り値の癖を抱えることになります。
MCP経由に寄せると、AIから見える入口は「使えるツール一覧」「参照できるリソース一覧」という形でそろいます。
筆者も、社内CLIとSaaS APIを混在させるより、MCP経由の統一UIに寄せた方が、オンボーディング時の説明が短くなりました。
新しく入ったメンバーに対しても「このクライアントで見えているツールが使える範囲です」と伝えれば済むので、個別APIの認証方式や実行条件を一つずつ説明する場面が減ったんですよね。
MCPの利点としてよく挙がるのが、動的発見・標準化・権限制御の3つです。
動的発見というのは、AIクライアントが接続先サーバーから「どんなツールがあり、どんな引数で呼べるか」を受け取れることです。
従来のAPI連携では、AIアプリ側があらかじめそのAPIの仕様を個別実装しておく必要がありました。
標準化は、接続先がファイルシステムでもAWS系サーバーでもAzure MCP Serverでも、AI側の扱いがそろうことを指します。
権限制御についても、APIごとにバラバラに考えるのではなく、MCPサーバー単位で公開ツールや参照範囲を整理しやすくなります。
企業向けの文脈では、ように、クライアント・サーバー構成の上で認証や運用を考えられるため、監査やID基盤との整合も取りやすくなります。
その一方で、APIそのものの価値が下がるわけではありません。
MCPサーバーの中身は既存APIの呼び出しであることも多く、MCPはその上に乗る整理レイヤーです。
言い換えると、APIは実体、MCPはAI向けの接続規約です。
この視点で見ると、「APIがあるならMCPは不要か」という問いには、「1対1の単純な連携なら不要なこともあるが、AIが複数の機能を横断して使うならMCPの意味が出てくる」と答えるのが実務に近い整理です。
その差分を一覧にすると、次のようになります。
| 項目 | MCP | 従来API連携 |
|---|---|---|
| 役割 | AI向けの共通インターフェース層 | アプリ同士を直接つなぐ個別インターフェース |
| 始めやすさ | ローカルの stdio 型なら初期検証を始めやすい | 既存APIがあればすぐ呼べるが、AI向け調整は個別実装 |
| 動的発見 | 可能。ツールやリソースをクライアントが把握できる | 基本は不可。仕様を事前に埋め込む前提 |
| 標準化 | ToolsResourcesPromptsで整理できる | APIごとに設計が異なる |
| 権限設計 | サーバー単位で公開範囲や実行範囲を整理しやすい | APIごとに個別設計が必要 |
| 監査・運用 | チーム運用や監査の設計に広げやすい | 連携が増えるほど管理点が分散しやすい |
| 向く場面 | AIが複数ツールをまたいで判断・操作する場面 | 単一機能を確実に呼ぶ1対1連携 |
向いているケース
MCPが活きるのは、AIが複数のツールやデータを横断しながら作業する場面です。
たとえばVS CodeやClaude Codeのようなクライアントから、ローカルファイル、社内ドキュメント、チケット管理、リポジトリ操作を同じ流れで扱いたいときです。
AIに「まず仕様書を読み、関連ファイルを確認し、必要ならissueを更新する」といった段取りを任せるなら、接続先が共通ルールで見えている方が自然です。
特に効くのが、AIによる自律的な機能発見がほしいケースです。
従来APIだと、AIに使わせたい操作を開発側が個別に埋め込む必要があります。
MCPなら、接続先サーバーが公開しているツール群をクライアントが把握できるので、AIは「使える機能の中から選ぶ」という振る舞いを取りやすくなります。
これは、機能追加のたびにAIアプリ本体を改修したくない場面で効いてきます。
もう1つ相性がいいのが、権限管理や監査を統一的に考えたい場面です。
VS Codeでもユーザー設定とワークスペース設定の両方でMCPサーバーを管理できるように、個人用とチーム共有用を分けて運用する考え方と相性があります。
個別API連携が増えると、「このトークンは誰が持つのか」「どこまで実行可能なのか」が散らばりがちです。
MCPの構成に寄せると、少なくともAIに何を見せ、何を実行させるかをサーバー単位で整理できます。
『Add and manage MCP servers in VS Code』のような実装例を見ると、この整理のしやすさがチーム運用で効く理由がつかめます。
実際にローカル検証から始めると、この違いはさらに体感しやすくなります。stdio 型のMCPサーバーは同一マシン上で立ち上げる前提なので、最初の試行ではネットワーク公開や複雑な認証を抱え込まずに済みます。
ファイル参照やローカルCLI連携のような小さな入口から試して、必要になったらStreamable HTTP型へ広げる流れだと、MCPを導入する意味が見えやすいはずです。
Add and manage MCP servers in VS Code
Learn how to add and manage Model Context Protocol (MCP) servers with GitHub Copilot in Visual Studio Code.
code.visualstudio.com向かない/過剰なケース

一方で、単一APIを単純に1対1で呼ぶだけなら、従来のAPI連携で十分なことも多いです。
たとえば「社内システムの在庫APIを呼んで結果を返すだけ」「決まったWebhookを1本たたくだけ」のような処理です。
この場合は、MCPサーバーを別途立てて標準化レイヤーを挟むより、既存APIクライアントをそのまま使った方が構成が短くなります。
過剰になりやすいのは、AIに求める役割が限定されているケースです。
使う機能が1つ、入力項目も固定、認証も既存アプリ側で完結しているなら、MCPの動的発見や抽象化の恩恵が出る余地は小さめです。
MCPは「AIが複数の候補から機能を選ぶ」「接続先が増える」「運用ルールを共通化したい」といった条件で価値が出ます。
逆にそこまでの要件がなければ、層を1枚増やす意味は薄くなります。
また、リモート共有を前提にしたMCPサーバーは、ローカル検証より設計項目が増えます。
Model Context ProtocolのSecurity Best。
これは裏を返すと、本番運用では考えることが多い、という意味でもあります。
単発の業務自動化にそこまでの運用を持ち込むと、構成の説明コストの方が先に立つことがあります。
つまり判断軸は、「AIにどこまで汎用的な接続口を持たせたいか」です。
単機能の自動化ならAPI直結、複数ツールを横断するAIワークフローならMCP、という切り分けで考えると、無理なく整理できます。
トランスポートの選び方:stdio と Streamable HTTP
用語整理
MCPのトランスポートを選ぶ場面で、まず押さえたいのはstdioとStreamable HTTPの役割の違いです。
どちらもAIクライアントとMCPサーバーをつなぐ手段ですが、向いている配置が異なります。
stdioは、クライアントがローカルでMCPサーバーのプロセスを起動し、標準入力と標準出力で通信する形です。
ネットワーク越しの公開を前提にしないので、最初の検証では構成が短くなります。
Filesystem系のようにローカルファイルを読むサーバーや、手元のCLIを薄く包むサーバーと相性がよく、権限も対象ディレクトリや環境変数の範囲で絞り込みやすいのが特徴です。
私も最初の動作確認ではこの形をよく使いますが、同一マシン内で完結するぶん、数分で「AIから道具が見える状態」まで持っていけます。
一方のStreamable HTTPは、リモートのMCPサーバーへHTTPで接続する前提の方式です。
本番での共有利用やSaaS連携、チーム横断の利用ではこちらの比重が上がります。
Model Context Protocolの『Roadmap』でも認証や認可の整理が進められており、2025年以降の運用では、単につながるかよりも「誰が使ったか」「どの操作が実行されたか」を残せる構成が価値を持ちます。
Azure MCP Serverや公開型のMCPサーバーを視野に入れると、TLS、認証、監査ログまで含めて設計する前提で考えたほうが流れに合います。
判断軸は大きく4つです。
1つ目は開始の容易さで、ここはstdioが明確に有利です。
2つ目はセキュリティ境界で、ローカルに閉じるのか、ネットワーク越しに切り出すのかで考えるべきことが変わります。
3つ目は監査と認証で、チーム運用ではStreamable HTTPのほうがID基盤と結びつけやすく、操作の追跡もしやすくなります。
4つ目はデプロイと運用で、個人の開発端末で完結するならstdio、複数人や複数環境に同じ接続先を配るならStreamable HTTPが収まりやすい、という整理です。
ローカル検証をstdioで立ち上げ、その後にStreamable HTTPへ移した経験だと、この差は運用フェーズでいっそうはっきり出ます。
最初はファイル参照の確認だけならstdioで十分でしたが、チーム展開の段階になると、誰の認証でどのツールが呼ばれたのかをログとして残せる構成のほうが説明しやすく、障害時の切り分けも速くなりました。
単にリモート化したというより、監査の設計を持ち込めたことが移行の実益でした。
テキスト図解

頭の中で構成をつかむには、接続の位置関係をテキストで見ると早いです。ローカル検証でよくあるのは次の形です。
AIクライアント —[stdio]— ローカルサーバー この形では、AIクライアントとMCPサーバーが同じPC上で動きます。
通信は標準入出力なので、Webサーバー公開やTLS終端を考えなくて済みます。
ローカルファイル、手元のスクリプト、開発用CLIの橋渡しに向いており、「まず1本つないで挙動を見る」という段階で回り道が少ない構成です。
チーム利用や外部サービス統合では、構図が次のように変わります。
AIクライアント —[Streamable HTTP/TLS]— リモートMCPサーバー(認証・監査)
こちらはMCPサーバーをネットワーク上に置き、クライアントがHTTP経由で接続します。
TLSで通信路を保護し、必要に応じてOAuthなどの認証を通し、サーバー側で監査ログを残す、という本番寄りの設計です。
『Security Best Practices - Model Context Protocol』で整理されている観点も、この構図を前提に読むと腹落ちします。
AIにツールを触らせる範囲が広がるほど、接続方式は単なる通信手段ではなく、運用ルールそのものになります。
Security Best Practices - Model Context Protocol
Security considerations, attack vectors, and best practices for MCP implementations
modelcontextprotocol.io初手の推奨
初手として推奨されるのはstdioです。
理由は単純で、MCPそのものの価値を確かめる段階では、ネットワーク設計や認証基盤より先に「AIが道具を発見して呼べるか」を確認したほうが理解が深まるからです。
ローカルで完結し、対象ディレクトリや環境変数を絞った最小権限の構成にしておけば、入口として負担が小さく済みます。
VS CodeやAmazon Qの設定例でも、ユーザー単位とワークスペース単位を切り分ける発想が見えますが、この段階では個人環境に閉じて試すのが取り回し上望ましいでしょう。
そのうえで、チームで共有したい、SaaSと結びたい、監査証跡を残したい、という要件が出てきたらStreamable HTTPの検討に進む、という順番が素直です。
stdioは「動くかどうか」を確かめる入口として優秀で、Streamable HTTPは「継続運用に耐えるか」を詰める段階で効いてきます。
最初から本番前提の構成に寄せると論点が増えますが、ローカルで1つ成功体験を作ってから移ると、認証や監査の設計が何のために必要なのかが見えやすくなります。
設定前の前提条件と最初に選ぶべきMCPサーバー
前提環境チェックリスト
ここで見たい項目は、実は多くありません。
つまり、重要なのは「クライアントが外部コマンドを起動できること」と「パッケージ名が実際に存在すること」です。uv / uvx のような表現を見かけたら、該当するパッケージの公式 README や配布元を確認し、正しい実行コマンド名を使うようにしてください。
最初はFilesystem系やドキュメント参照系から
初手で選ぶMCPサーバーは、できるだけ「読める」「見える」「触っても被害が広がらない」ものが向いています。
その条件に最も合うのがFilesystem系とドキュメント参照系です。
前者はローカルの特定ディレクトリだけを対象にでき、後者は製品ドキュメントやナレッジベースを参照する用途が中心なので、いきなり外部SaaSの状態を書き換える構成になりません。
なお、起動用ランチャーやコマンド名についてはコミュニティで使われる呼称と公式の表記が異なることがあります。
たとえば一部の非公式サンプルでは uv / uvx と表記される例が見られますが、これらは実装や配布元によって意味合いが変わるため、「実際に使うときは配布元の README や公式ドキュメントでパッケージ名・実行コマンドを必ず確認する」ことを推奨します。
コマンド名が誤っているとクライアント側では単に「起動しない」事象として現れるため、事前確認が欠かせません。
避けたい初手の例

反対に、最初の1本として遠回りになりやすいのは、広い書き込み権限を持つGitHub系や、操作対象が多いブラウザ自動化系です。
どちらもMCPの価値を強く感じやすい領域ではありますが、初手だと「MCPの理解」より「権限事故をどう防ぐか」「操作履歴をどう残すか」に論点が移ります。
GitHub系はトークンスコープの設計次第で、issue更新、PR操作、ブランチ作成、リポジトリ変更まで守備範囲が広がります。
便利さと引き換えに、どこまで書けるのかを曖昧にしたまま使うと、学習コストより先に管理コストが立ち上がります。
ブラウザ自動化系も同様です。
ログイン済みセッション、フォーム送信、管理画面の遷移、外部サイトへのアクセスなど、触れる対象が一気に増えるため、検証の焦点がぼけます。
Security Best Practices - Model Context Protocolで触れられている認証情報管理やセッションの扱いを考えると、ここは「つながるか」より「運用設計が固まっているか」で着手順が決まる領域です。
監査ログ、ID基盤、権限分離が整理されたあとに段階導入するほうが、判断の筋が通ります。
初手で避けたいのは、難しい技術そのものではなく、失敗したときに原因が増えすぎる構成です。
ローカルの限定ディレクトリを読むFilesystem系なら、問題が起きても実行環境、設定、対象パスのどこかに絞れます。
GitHub系やブラウザ自動化系は、そこに認証、スコープ、対象サービス側の状態、UI変化まで加わります。
MCPの最初の成功体験として必要なのは派手な自動化ではなく、「AIが道具を見つけ、狙った範囲で動いた」と言い切れる一回です。
その感覚を先につかんでおくと、次にSaaS連携へ進んだときも、どこから権限と監査の話が始まるのかが見えます。
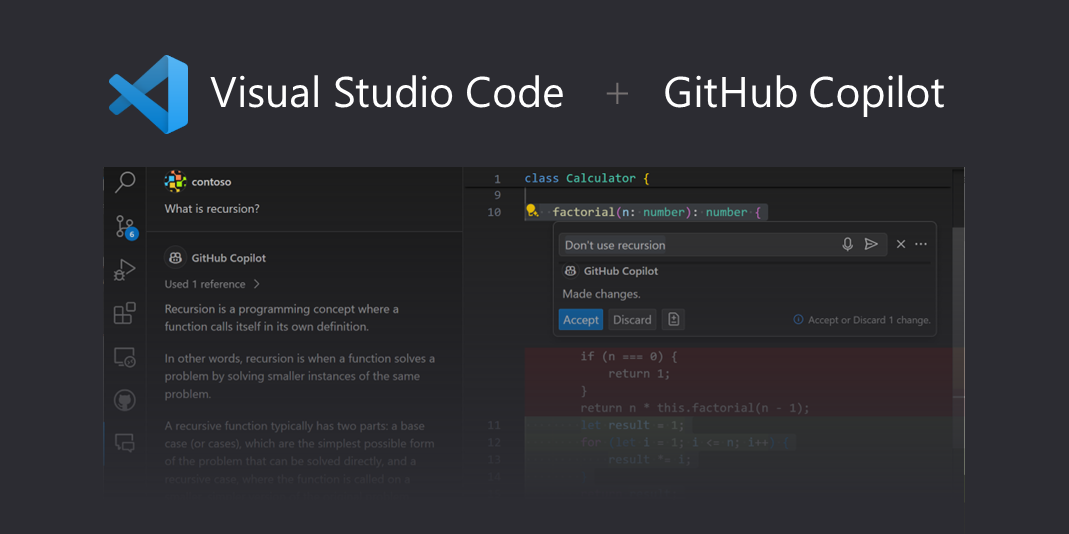
MCPサーバーの基本設定手順
設定ファイルの考え方
MCPサーバーの初期設定は、クライアントごとの差はあっても、実際にやることはほぼ共通です。
設定ファイルにサーバー定義を追加し、クライアントを再起動し、UI上で有効になっているかを見る。
この3段階で捉えると、VS CodeでもAmazon Q Developerでも迷いにくくなります。
Model Context Protocolの実装説明で整理されている通り、クライアントは外部のMCPサーバーに接続して、そこからToolsやResourcesを受け取ります。
その入口になるのが設定ファイルです。
設定ファイルでまず押さえるべき項目は、command / args / env の3つです。command は起動する実行ファイル、args はその実行時引数、env はAPIキーや動作に必要な環境変数を渡す場所です。
たとえばローカルのstdio型サーバーでは、クライアントがこの定義を見て外部プロセスを起動し、標準入出力で通信します。
設定の理解はここから始まります。
この考え方で整理されていますし、Amazon Q DeveloperもAmazon Q Developer MCP設定ファイルについて。
最小構成のイメージは、たとえばVS Codeなら .vscode/mcp.json にサーバー定義を書く形です。
{
"servers": {
"filesystem": {
"command": "node",
"args": ["./server.js"],
"env": {
"ROOT_DIR": "./workspace"
}command に何を指定するかはサーバー実装ごとに変わりますが、見方は同じです。
クライアントは「どのコマンドで」「どの引数を付けて」「どの環境変数を渡して」サーバーを立ち上げるかを、この定義から読み取ります。env に秘密情報を直接書けるクライアントもありますが、共有対象の設定にそのまま埋め込むと管理が崩れるので、ユーザー設定とワークスペース設定の使い分けが効いてきます。
個人専用のAPIキーはユーザー設定、チームで共通化したいサーバー定義はワークスペース設定、という切り分けだと運用の筋が通ります。
Amazon Q Developerでも考え方は近く、ユーザー全体に効かせる定義と、特定プロジェクトだけで使う定義を分けられます。
構成の形は次のように理解しておくと把握しやすくなります。
{
"mcpServers": {
"docs": {
"command": "node",
"args": ["./docs-server.js"],
"env": {
"DOCS_TOKEN": "YOUR_TOKEN"
}名前の付け方にも少し実務的なコツがあります。
サーバー名は、役割が見える短い名前のほうが後で一覧を見たときに判別しやすく、同種のサーバーを複数入れた場面でも混線しません。
Amazon Q DeveloperではMCPサーバー名に250文字以下という上限がありますが、そこまで長い名前を付ける場面はまずなく、実際は「何を扱うサーバーか」が一目で読める命名のほうが効きます。
stdio型サーバーでは、もうひとつ見落とされがちな前提があります。
stdoutにプロトコル以外の不要なログを出さないことです。
デバッグ用の console.log や起動メッセージを標準出力に流すと、クライアントとの通信データに混ざって壊れます。
状態表示やデバッグ出力が必要ならstderrへ逃がす、もしくはファイルログに分ける、という整理が必要です。
接続できない原因が設定値ではなくログ出力そのものだった、という場面は珍しくありません。
再起動が必要なクライアントの例と見落とし対策

stdio 型サーバーでは、もうひとつ見落とされがちな前提があります。
stdout にプロトコル以外の不要なログを出さないことです。
デバッグ用の console.log や起動メッセージを標準出力に流すと、クライアントとの通信データに混ざって壊れます。
状態表示やデバッグ出力が必要なら stderr へ出力するか、ファイルログに切り分けてください。
接続できない原因が設定値ではなくログ出力そのものだった、という場面は珍しくありません。
設定を書き終えた直後に、そのままツール一覧を開いて「サーバーが出てこない」と首をかしげるのは、MCP導入ではよくある詰まり方です。
私も最初にここで止まりました。
設定ミスだと思ってファイルを何度も見直したのに、クライアントを再起動した途端に即座に認識されたことがあります。
設定ファイルを起動時に読む実装が多いので、この手の空振りは珍しい失敗ではありません。
VS CodeやAmazon Q Developerのように設定ファイルベースでMCPサーバーを扱うクライアントでは、新規追加や編集のあとに再起動を挟む前提でいたほうが流れが安定します。
ウィンドウの再読み込みだけで足りる場面もありますが、MCPサーバーのプロセス起動まで含めて反映させたいときは、クライアント自体を閉じて立ち上げ直したほうが切り分けが早く進みます。
見落としを減らすには、設定作業を「保存したら確認」ではなく、「保存したら再起動、そのあとUI確認」という固定手順にしてしまうのが効きます。
MCPは設定値、実行コマンド、環境変数、サーバープロセス起動の4点が連動するので、設定ファイルだけ正しくても、起動中のクライアントが古い定義を握ったままだと結果がズレます。
とくに最初の1本では、設定内容そのものより再起動漏れで時間を使いがちです。
⚠️ Warning
MCPサーバーを追加した直後に認識されないときは、設定ファイルの再読込を疑う前に、クライアントの再起動有無を切り分けると原因が一気に絞れます。
この段階でエラーが出た場合も、焦点は意外と単純です。command のパスが違う、args の指定が不足している、env に必要な値が入っていない、あるいはサーバー側がstdoutへ余計な文字列を出している。
このどれかに収まることが多く、再起動後も認識されなければ、その順で潰していくと追いやすくなります。
UIでの有効化確認とログの見方
再起動まで済んだら、成功判定は設定ファイルではなくUIで行います。
見る場所はクライアントごとに少し違っても、観点は共通です。
ツール一覧にサーバー由来の項目が現れているか、サーバー状態が running になっているか、ログに起動失敗や接続失敗が出ていないか。
この3点が揃えば、少なくとも「定義が読まれ、起動され、クライアントから見えている」状態までは確認できます。
VS CodeではMCP関連の管理画面やツール一覧に、追加したサーバー名やその配下のツールが現れます。
Amazon Q Developerでも同様に、MCPサーバーが有効化されると一覧や管理UIから見える状態になります。
アイコンが表示される、サーバー名の横に稼働中の表示が付く、ツール呼び出し候補に対象機能が混ざる、といった変化が確認判断材料になります。
ここで何も出ていなければ、設定が保存されていないか、再起動が反映されていないか、起動時点で落ちています。
ログを見るときは、MCPそのものの抽象論より、起動プロセスの失敗として読むほうが把握しやすくなります。
たとえば「command not found」であれば実行ファイルの参照先が違い、「missing environment variable」であれば env が不足し、「unexpected output on stdout」に近い内容なら標準出力の混入を疑う、という見方です。
running 表示が出ないのにツール一覧にも何もない場面では、サーバー起動前に落ちていることが多く、ログの最初の数行に手がかりがあります。
UI確認で意識したいのは、「設定を書いた」ことではなく「クライアントが使える状態になった」ことを見届けることです。
MCPは接続できた瞬間から価値が出る仕組みなので、サーバー名が見える、ツールが並ぶ、running が付く、エラーが消えている、という具体的な変化まで確認すると、次の権限調整やツール追加にも進みやすくなります。
クライアント別の設定例:Claude Desktop・Claude Code・VS Code・Amazon Q

Claude Desktop:運用例(公式手順は限定的に確認)
Claude Desktopに関する情報は、コミュニティで共有されている設定ファイルベースの運用例が見られますが、Anthropic の公式ドキュメント上で同等の手順が明確に示されているかは限定的です。
非公式な事例では command / args / env のような項目でローカルの stdio 型サーバーを定義する運用が紹介されています。
実際に設定を行う際は「コミュニティで報告されている運用例」であることを明示したうえで、公式のサポート情報やリリースノートを合わせて確認することを推奨します。
Claude Code:CLIでの追加例(コミュニティ例)
一部のコミュニティ投稿では、claude CLI を使ってローカルの MCP サーバー定義を追加する例が共有されています。
代表的な非公式例としては次のような構文が挙げられます claude mcp add
この例では `<name>` で識別名を付け、`-s user` 相当のオプションでユーザー単位の設定にする流れを示していますが、CLI の正式なフラグや挙動はバージョンにより変わります。導入時は公式の CLI リファレンスや製品ヘルプで構文とフラグの意味を確認してください。
CLI経由の利点は、同じ形を端末に残しやすいことです。ローカル検証では stdio 型サーバーを短時間で立ち上げたい場面が多く、コマンドラインにしておくと「どの実行ファイルを、どの引数で起動したか」をそのまま共有できます。逆に、引数のひとつでも抜けると起動に失敗するので、設定ファイルを直接編集する場合よりも、実行単位で意味を確認しながら扱えるのがCLIの強みです。
CLIで登録したあとも、見るべき場所は同じです。サーバーが一覧に出るか、対象ツールが認識されるか、起動時エラーが出ていないか。この3点が揃えば、登録コマンドがクライアント側の設定へ正しく落ちたと判断しやすくなります。
### Claude Desktop:運用例
Claude Desktopに関する具体的な操作手順や設定ファイル名は、現時点で Anthropic の公式ドキュメントで包括的に示されているとは限りません。コミュニティで共有されている設定ファイルベースの運用例が参考になる場合もありますが。
### Claude Code:CLIでの追加例(コミュニティ例としての扱い)
一部のコミュニティ投稿では、`claude` CLI を使ってローカルの MCP サーバー定義を追加する例が共有されています。代表的な非公式例としては次のような構文が挙げられます:
# コミュニティ例 claude mcp add
この種の CLI 例は便利ですが、バージョン差やフラグ名の違いで挙動が変わる可能性があります。導入時はまず端末でコマンドを手動実行して初回プロンプトの有無や必要なフラグを確認し、公式の CLI リファレンスや製品ヘルプで構文・フラグの意味を裏取りしてから手順に落とし込んでください。
この継承の考え方を押さえると、設定の置き場所で迷いにくくなります。個人用の共通ツールまで各リポジトリに複製すると、少しの修正でも複数箇所を直すことになります。逆に、案件固有の設定をすべてグローバルに寄せると、関係のないプロジェクトでも一覧に出てきて見通しが悪くなります。Amazon Q Developerはこの二層構造で分けておくと、どこまでが自分の標準装備で、どこからが案件専用かを自然に保てます。
ユーザー単位とワークスペース単位の違いは、VS CodeでもAmazon Q Developerでもほぼ同じです。前者は個人の基盤、後者はプロジェクトの再現条件です。クライアントが変わっても、この軸で設定を置き分けると読み替えが効きます。MCPの導入そのものより、**どの設定を誰と共有するのか**を先に決めたほうが、あとからサーバーが増えても構成が散らばりません。
## 安全に使うためのセキュリティ設定
MCPを実務で使い始めると、便利さより先に設計しておきたいのが**どこまで触らせるか**です。信頼できるサーバーの採用、最小権限、認証情報の分離、ネットワーク境界の管理が基本線として整理されています。MCPサーバーはAIから見れば「使える道具」に見えますが、運用する側から見ると、ファイル、外部API、社内データへの入口をまとめて増やす行為でもあります。導入時に権限の輪郭を曖昧にすると、あとで監査も切り戻しも難しくなります。
### 信頼できるサーバーだけを追加する
最初に見るべきなのは、便利そうな機能より配布元です。GitHub上に公開されているMCPサーバーやコミュニティ製のラッパーは数が増えていますが、追加対象は**配布元が明確で、署名や公開リポジトリの履歴が追え、更新頻度に不自然な空白がなく、脆弱性対応の姿勢が見えるもの**に絞ったほうが運用が崩れません。企業が出しているものでも、更新が止まっていたり、依存パッケージの修正が追随していなかったりすると、実際のリスクは下がりません。
私がチームに配る前提でMCP構成を整えるときは、まず検証用リストを短く保ちます。便利なサーバーを次々に足すより、配布元、更新履歴、既知の不具合への反応を見ながら少数で始めたほうが、レビューの粒度が落ちません。とくに外部APIとファイル操作の両方を持つサーバーは、ひとつ入れるだけで権限面の影響範囲が広がるので、ツール一覧の見た目以上に慎重に扱っています。
### 最小権限はディレクトリとツールの両方で絞る
権限を絞るときは、サーバー単位で見るだけでは足りません。**どのディレクトリに触れられるか、読み取りだけか書き込みも含むか、どのツールを有効にするか、トークンのスコープがどこまでか**を分けて考えると、事故の入口が見えます。Filesystem系のMCPサーバーなら、まず対象ディレクトリを限定し、可能なら読み取り専用に寄せるのが基準になります。GitHub系なら、リポジトリ全体の管理権限ではなく、必要な操作に絞ったトークンスコープで止める形です。
テスト段階では、私は“書き込み”を先に封じることが多いです。読み取り専用ディレクトリだけを許可した状態でチームに配ると、メンバーは安心して触れますし、導入の心理的な抵抗も下がります。実際、この形にしてからは「設定を入れたら何か壊しそう」という不安が減り、レビューも「このサーバーはどこを読むのか」に集中できました。最初から万能にするより、読めるが書けない構成で使い道を固め、それから必要な箇所だけ書き込みを開けるほうが、運用の筋が通ります。
> [!WARNING]
> チーム配布の初期構成は、Filesystem系なら読み取り専用の限定ディレクトリ、API系なら参照中心のスコープから始めると、導入直後の事故点が減ります。
### 認証情報は設定ファイルと分離する
前のセクションで触れた共有範囲の話は、セキュリティ設定ではそのまま**秘密情報の置き場所**に直結します。APIトークンやシークレットを設定ファイルへ平文で直書きすると、ワークスペース共有の時点で漏えい経路が増えます。ここは、サーバー定義と認証情報を分けるのが前提です。サーバーの command や args は共有設定に置いても、トークンは環境変数に逃がし、秘密値が必要なものはユーザー設定側に閉じ込める、という分離が基本になります。
この運用にしておくと、設定レビューで見たいものと見せたくないものが自然に分かれます。たとえば `.vscode/mcp.json` や `.amazonq/mcp.json` のような共有設定には「どのMCPサーバーを使うか」だけが残り、個人トークンは各自の環境変数にだけ置かれるので、差分確認のたびに秘密情報をマスキングする必要がありません。トークンのローテーションも設定ファイルの変更と切り離せるため、構成管理の見通しが保てます。
### OAuthとResource Indicatorsは認可対象を曖昧にしないための土台
Streamable HTTP型のMCPサーバーをチームや企業で運用する段階になると、認証は「ログインできるか」だけでは足りません。MCPのロードマップでは認可まわりの整理も進んでおり、OAuth Resource Server の文脈や関連仕様の整備が見えてきます。ここで押さえておきたいのは、**誰が、どのMCPサーバーというリソースに対して、どの権限でアクセスするのか**を分離して設計することです。
OAuthの流れを短く言えば、ユーザーまたはクライアントが認可基盤からトークンを受け取り、そのトークンを持ってMCPサーバーへアクセスします。Resource Indicatorsの考え方は、そのトークンがどのリソース向けなのかを明示して、用途の違うサーバーへ曖昧に使い回されるのを防ぐためのものです。エンタープライズ環境では、MCPサーバーごとに audience や resource を分け、ファイル参照用、社内ナレッジ参照用、変更操作を伴う業務サーバー用で認可境界を切ると、権限棚卸しと監査の両方が回しやすくなります。
### 監査ログとキャッシュは「残る前提」で扱う
見落とされやすいのが、MCPサーバーが返した内容そのものより、**どこに記録が残るか**です。監査ログ、クライアント側キャッシュ、ローカル保存、ターミナル履歴、例外発生時のデバッグ出力には、機微情報がそのまま残ることがあります。たとえば社内文書の一部、顧客識別子、トークン断片、外部APIのレスポンスが、操作ログやローカルファイルに保存されると、後から意図しない持ち出し経路になります。
そのため、監査ログは「何を記録するか」だけでなく、「何を記録しないか」まで決めておく必要があります。誰がどのサーバーのどのツールを呼び出したかは残す一方で、本文そのものや秘密値はマスクする、といった線引きです。キャッシュも同じで、利便性のために保持するなら保存先と保持期間を先に定め、ローカル保存を許す端末範囲まで含めてポリシー化したほうが後工程で揉めません。監査のために全部残す発想は、機微データの複製を増やしてしまいます。
### 外部呼び出しを伴うサーバーは送信先を縛る
ネットワーク越しに動くMCPサーバーや、内部から外部へHTTPリクエストを投げるツールでは、SSRFのように**想定外の宛先へアクセスさせられる経路**も意識しておきたいところです。とくにURLを引数で受け取る取得系ツール、Webhook連携、クローラ型のサーバーは、入力の自由度が高いぶん送信先制限が甘くなりがちです。ここはアプリ側のバリデーションだけに頼らず、許可ドメインの allowlist、メタデータIPや社内管理面への到達遮断、プロキシ経由の外向き通信に寄せる構成が効きます。
ローカル検証で始めた stdio 型のサーバーはネットワーク面の論点が少ないぶん立ち上げが軽いのですが、外部呼び出しを含む構成へ広げた瞬間に管理対象が増えます。社内で共有するHTTP型サーバーほど、プロキシで送信先を一元管理できる形のほうが、ログ保全と出口制御を同時に揃えられます。MCPは「AIのための接続規格」ですが、運用ではふつうの業務システムと同じく、認証、権限、通信経路、記録の四点を先に固めた構成のほうが長く保てます。
## よくあるエラーと対処法
導入でつまずく場所はある程度決まっていて、原因の切り分けも順番があります。MCP自体はローカルの `stdio` 型から入ると立ち上げが軽いぶん、設定の一文字違いと起動手順の抜けで止まりやすく、実際には「難しい」のではなく「詰まりどころが細かい」という感触です。設定反映にはクライアント再起動が必要になるケースが多いと整理されており、挙動が不自然なときはまず読み込み直しの有無から疑うと空振りが減ります。
### 設定を変えたのに反映されないときは再起動不足を先に疑う
いちばん多いのは、設定ファイルやサーバー定義を修正したのにクライアント側へ反映されていないケースです。ウィンドウを閉じただけではバックグラウンドでプロセスが残っていて、古い設定を握ったまま再接続していることがあります。追加したサーバーが一覧に出ない、前の `args` のまま起動する、修正した `env` が効かない、といった症状はこのパターンで説明できます。
対処は単純で、クライアントを**完全終了してから再起動**します。タブを閉じるだけでなく、アプリ本体を落として立ち上げ直すと解消する場面が多いです。私も設定内容ばかり見直して時間を使ったあと、クライアントを落として開き直しただけで通ったことが何度もありました。設定差分を追う前に、まず読み込みタイミングをリセットしたほうが早く片づきます。
### `npx` や `uvx` の対象名が違うと起動前に止まる
次に多いのが、パッケージ名やコマンド名の誤記です。`npx` で起動するつもりが対象パッケージ名を一文字取り違えていたり、`uvx` で呼ぶ名前と実際の配布名が食い違っていたりすると、クライアントから見ると「サーバーが起動しない」挙動になります。設定ファイルの JSON 構文は正しいのに `failed` になる場合、原因は設定フォーマットではなく、**そもそも起動コマンドが存在しない**ことが少なくありません。
このときは `command` と `args` をまとめて見るより、実際にそのコマンドをターミナルで単体実行して、同じ名前で起動するかを確認すると切り分けが進みます。とくに `npx <package>` の `<package>` 部分と、`uvx <package>` の指定は見慣れた単語ほど思い込みで打ってしまうので、コピーしたつもりでも別名になっていないかを見直す価値があります。
### `npx -y` を付け忘れると初回確認で止まる
`npx` 系で見落としやすいのが `-y` です。初回実行時に確認プロンプトが出るパッケージでは、非対話で起動されるMCPサーバーがその確認待ちで停止し、クライアント側では「追加したのに応答が返らない」状態になります。画面上は静かでも、裏では yes/no 待ちになっているだけということがあります。
ここは実際に一度ひっかかると記憶に残ります。私も `npx -y` を付けずにサーバーを追加したとき、設定ミスだと思って JSON と環境変数を見直し続けたのですが、ターミナルで同じコマンドを打ち直したら初回確認が出て、その場で原因が見えました。以後は `npx` で非対話起動するものは `-y` を前提に置くようになり、ハングと見分けがつかない停止はほぼ消えました。
> [!NOTE]
> `npx` で起動するMCPサーバーが無反応のときは、同じコマンドをターミナルで一度だけ手動実行すると、初回確認・不足パッケージ・認証エラーのどこで止まっているかが分かります。
### 認証エラーは `env` の設定漏れで起きることが多い
GitHub系や外部API連携系のサーバーでは、環境変数の不足がそのまま認証エラーになります。サーバー定義そのものは正しくても、`env` に必要なキーが入っていない、変数名のスペルが違う、`.env` に定義したつもりで読み込まれていない、というズレで失敗します。症状としては「サーバーは起動するのにツール実行だけ失敗する」形が典型です。
ここでは、クライアントのエラーログに出ている不足項目と、実際の `env`、さらに手元の `.env` の内容が一致しているかを突き合わせます。トークン値そのものではなく、**変数名が一致しているか**を見るのが先です。たとえば `API_KEY` と `SERVICE_API_KEY` のように、値は存在していてもキー名が違えば読み取れません。設定ファイル側の `env` で何を渡しているかと、サーバーが何を期待しているかを同じ画面で見ると、見落としが減ります。
### `failed` と `running` の表示を見落とすと原因を取り違える
クライアントUIや管理画面に状態表示がある場合、`running` なのか `failed` なのかで読むべきログが変わります。`failed` なら起動時点で落ちているので、コマンド、引数、パッケージ名、初回プロンプト、標準出力の破損を疑う流れになります。反対に `running` なのに使えないなら、認証、権限、入力値、ツール個別エラーの線が濃くなります。
この二つを混同すると、起動に失敗しているのに API トークンばかり見たり、逆に起動済みなのに `command` の書式ばかり直したりして、調査の方向がずれます。UIの状態表示とログを突き合わせるだけで、「起動できていない問題」と「起動後に失敗する問題」を分離できます。ログを読む前に状態ラベルを確認するだけでも、手を入れる場所が絞れます。
### `stdio` サーバーは stdout の不要ログで壊れる
`stdio` 型で見逃せないのが、標準出力 `stdout` にデバッグログや `console.log` を出してしまう問題です。MCPのプロトコル通信は `stdio` を流れるため、そこへ人間向けのログが混ざると、クライアント側は正しいメッセージとして解釈できなくなります。起動直後に切れる、途中で応答が読めなくなる、理由不明の通信断に見える、といった壊れ方をします。
これは実際に再現すると厄介です。ローカルで挙動を見たくて `stdout` にデバッグ出力を足したところ、サーバー単体では動いているのにクライアント接続だけが途切れ、原因に気づくまで遠回りしました。対処は明確で、**プロトコル用の出力は `stdout` に残し、ロギングは `stderr` へ逃がす**ことです。Node系なら `console.error`、他の実装でも標準エラー出力へ寄せるだけで通信は安定します。`stdio` 型はローカル検証を素早く始められる反面、出力先を雑に扱うとプロセス自体は生きていても会話だけ壊れるので、この一点は実装段階で意識しておくと詰まりません。
## MCPでできることと、次に試すと効果が大きい連携
### まず試す:Filesystem系
導入直後に効果をつかみやすいのは、Filesystem系のMCPサーバーです。理由は明快で、AIがローカルの作業ディレクトリを読んで、ファイルを作り、既存のコードやメモを編集するところまでを一続きで扱えるからです。要するに、チャットで方針を決めて終わるのではなく、その場で `README` を更新したり、サンプルコードを新規作成したり、設定ファイルの差分を出したりできます。最初の検証がローカルの `stdio` 型から始まるケースで相性がいいのもこの系統で、ネットワーク公開や認証の準備を先に抱え込まず、実際の作業フローに直結した変化を見やすいのが利点です。
私自身、MCPの価値を最初に実感したのはこの段階でした。たとえば仕様メモを読ませて、同じ内容を反映したサンプル実装を別ファイルに出し、ついでにテストのひな形まで生成させる、といった一連の流れが一つの会話の中で閉じます。コピー&ペーストの往復が減るので、AIに依頼した内容と実ファイルのズレも起こりにくくなります。初心者向け適性が高いとされるのも納得で、APIキー不要で始められる構成が多く、まず「AIが外の世界に手を伸ばすと何が変わるのか」を体感するには十分です。
ここでの典型例は、議事録から `docs/` 配下に要約を保存する、既存コードを読ませて `examples/` に最小サンプルを生成する、CSVを読んでレポート用Markdownを吐き出す、といったものです。単体でも便利ですが、この段階では「MCPサーバーを1個増やす」より、「AIにどのディレクトリを触らせるか」を設計したほうが、後の運用が安定します。ユーザー設定で広く持たせるより、ワークスペース設定でプロジェクト単位に閉じるほうが、再現性のある使い方に寄せやすい場面も多いです。
### 次に追加:ドキュメント参照系で知識の鮮度を補う
次に追加して手応えが出やすいのが、公式ドキュメントや製品資料を引けるドキュメント参照系です。ローカルのファイル操作だけでも便利ですが、そこへ「今の仕様」を補給できるようになると、AIの回答が過去知識だけで閉じなくなります。MCP自体も更新が続いており、『Model Context Protocol roadmap』 では更新日が2026-03-05になっているように、仕様や周辺実装の前提が動く領域です。こういうテーマでは、学習済み知識だけに頼るより、最新の一次情報を都度参照できる構成のほうが現場向きです。
この系統は、単に「調べ物ができる」だけでは終わりません。AIが新しいSDKの変更点を確認し、その結果を踏まえてローカルにサンプルコードを書き出せるようになると、調査と実装の間にある手作業が一気に短くなります。私も、最新SDKの差分をドキュメント参照系サーバーで確認してから、必要なサンプルをFilesystem側に生成し、そのままPRの土台まで作る流れを日常的に使うようになって、タブを行き来しながら要点をメモし直す時間が目に見えて減りました。以前は「読む」「まとめる」「コード化する」が分断されていましたが、MCPを挟むとこの3つが同じ会話の連続になります。
複数サーバー連携のイメージを持つなら、「資料検索→ファイル生成→Git PR作成」の3段構成がわかりやすいです。まずドキュメント参照系で新仕様や料金表、設定条件を調べ、次にFilesystemで設計メモやコード、運用手順書を出力し、その成果物をGitHub系でブランチ作成やPR作成につなげます。この流れだと、AIが参照した根拠と生成物と提出先が一本のワークフローでつながるので、「何を見て、何を作って、どこへ反映したか」を追いやすくなります。
> [!TIP]
> [!NOTE]
> 体感差が出やすい順番は、Filesystemでローカル作業を固めてから、ドキュメント参照系で知識の鮮度を足す構成です。生成物の置き場所が先に決まっていると、参照した情報をそのまま成果物へ落とし込みやすくなります。
{{ogp:https://modelcontextprotocol.io/|What is the Model Context Protocol (MCP)? - Model Context Protocol||https://raw.githubusercontent.com/modelcontextprotocol/docs/2eb6171ddbfeefde349dc3b8d5e2b87414c26250/images/og-image.png}}
### 本番志向:GitHub/ブラウザ/クラウド系は権限設計とセットで
本番に近い活用へ進むと、GitHub連携、Playwrightのようなブラウザ自動化、クラウド情報参照の価値が一段上がります。GitHub系では issue の参照や起票、branch 作成、PR 作成といった開発運用そのものに触れられるので、AIが「提案者」から「変更を運ぶ実務者」に近づきます。2025年8月時点でGitHub MCPはパブリックプレビュー段階とされていましたが、開発現場で注目されやすいのは自然です。ローカルにファイルを作るだけでなく、変更の提出先までAIが扱えるようになると、作業の切れ目が減ります。
ブラウザ自動化は、管理画面の確認、フォーム入力、表示崩れの検証、ログイン後のフロー確認といった、人がブラウザでやっていた反復作業を置き換える場面で効きます。特にドキュメントだけでは拾えないUIの実在確認や、設定変更後の画面状態チェックは、ブラウザを触れるかどうかで差が出ます。コード生成だけでは埋まらない「実画面で本当にそう見えるか」をAI側の流れに取り込めるからです。
クラウド系も実務では外せません。料金や設定の確認が会話の中でできると、構成案の現実味が上がります。たとえばAWS Pricing MCP Serverは Pricing API の呼び出し自体が無料で、料金試算の入口を作りやすい構成です。運用設計ではMicrosoft SentinelのMCPツールに追加費用なしの範囲がある、といった課金境界の把握も判断材料になります。こうした情報参照は、AIが「この構成が技術的に可能か」だけでなく、「費用や設定の観点で筋が通るか」まで踏み込む土台になります。
ただし、この段階ではサーバーを足すこと自体より、権限範囲をどう切るかのほうが先に効いてきます。前述の通り、ローカルの `stdio` 型は立ち上げが軽い一方、チーム共有や本番公開に寄るほど認証や監査の設計が前面に出ます。ユーザー設定に個人用の強い権限を持たせ、ワークスペース設定にはプロジェクトに必要な最小限だけを置く、という分離は実務で扱いやすい形です。そこに監査ログをどう残すか、トークンのスコープをどこまでにするか、誰がどのMCPサーバーを追加できるかまで含めて事前に合意しておくと、運用に入ってからの摩擦が減ります。
外部エコシステムの成熟度を見る材料としては、Scale Labs MCP Atlas が1,000 tasks、36 MCP Servers、220 Toolsで評価を行い、最高Pass Rateとして62.3%を示している点も示唆的です。もう「一部の実験的な連携」ではなく、比較可能な単位で検証が進む段階に入っています。だからこそ、導入順序はFilesystemで土台を作り、ドキュメント参照で鮮度を補い、その先でGitHub、ブラウザ、クラウドを権限設計と一体で広げる流れが噛み合います。用途を増やすほど、MCPは単なる便利ツールではなく、チームの作業経路そのものを整える層として見えてきます。
{{product:4}}
## まとめと次のアクション
MCPは、AIに外部ツールを個別実装ではなく共通の作法で渡すための土台です。最初はローカルで閉じる `stdio`、共有や本番に広げる段階で `Streamable HTTP` と考えると判断がぶれません。実際、私もFilesystemから入り、次にドキュメント参照、その後にGitHubやクラウドへ広げたことで、移行コストと権限リスクを抑えたまま定着させられました。入口で欲張らず、最小権限から始めた構成ほど後で運用に乗ります。
今日やることは次の3つで十分です。
1. Filesystem系サーバーを読み取り中心の範囲で追加する
2. クライアントを再起動して有効化を確認する
3. ドキュメント参照系サーバーを足し、作業速度の差を見比べる
関連の内部記事(作成推奨)
- 「MCP 入門:Filesystem サーバーで始める手引き(チュートリアル)」
- 「VS Code での MCP 運用ポリシー(ワークスペース設定とユーザー設定の分離)」
> [!NOTE]
> 現在サイトに内部記事が未作成のため、上記は作成推奨タイトルです。実装時はこれらを個別記事として作成し、該当箇所から内部リンクを張ると読者の導線が改善します。AIビルダーの編集チームです。AI開発ツールの最新情報と使い方を発信しています。
関連記事
MCP接続トラブル対処|5層で原因特定
MCP接続トラブル対処|5層で原因特定
MCPサーバーを追加したのに、接続できない、認証が通らない、ツールが出てこない。そんな詰まり方は、設定を総当たりで触るより、Host・Client・Server・Transport・Authorization のどこで止まっているかを順に切り分けたほうが早く抜けられます。
Claude Code VS Code連携の設定と使い方
Claude Code VS Code連携の設定と使い方
『VS Code』で『Claude Code』を使い始めるなら、いちばん近道なのはVisual Studio Marketplaceから公式拡張を入れて、そのままパネルを開く流れです。
Claude Code vs Cursor 比較|違いと使い分け
Claude Code vs Cursor 比較|違いと使い分け
Claude Codeと『Cursor』はどちらもAIで開発を加速できる道具ですが、触ってみると得意な仕事がはっきり違います。VS Code歴の長い筆者は両方を試してきましたが、細かな実装修正をテンポよく詰める場面では『Cursor』の即応性が気持ちよく、
Claude Code 使い方|インストールと基本操作【2026】
Claude Code 使い方|インストールと基本操作【2026】
Claude Codeは、ターミナルでコードを読み、編集し、コマンド実行まで任せられるぶん、最初の導入順を間違えると「便利そうだけど怖い」で止まりがちです。ここでは、Mac・Windows・Linuxそれぞれでの安全な入れ方から、初回起動、