Cursor Automations 入門と活用例
Cursor Automations 入門と活用例
Cursorを普段の開発で使っていても、Automationsまで触れている人はまだ多くありません。2026年3月5日に公開されたこの機能は、Slack、GitHub、Linear、PagerDuty、Webhook、
Cursorを普段の開発で使っていても、Automationsまで触れている人はまだ多くありません。
2026年3月5日に公開されたこの機能は、Slack、GitHub、Linear、PagerDuty、Webhook、スケジュールなどを起点に cloud agents を自動で起動できる仕組みです。
Cursor Automations とは

公開日は 2026年3月5日で、Cursor の公式ブログの発表記事と変更履歴(changelog)で案内されています。
混同しやすいのが Cursor Rules(プロジェクト規則)との関係です。
Cursor Rules は .cursor/rules に置く恒久的な指示で、エージェントに「このプロジェクトでは何を守るか」を教える層です。
コーディング規約、出力方針、リポジトリ固有の前提知識を持たせる役目で、いわば振る舞いの土台にあたります。
公式ドキュメントでも AGENTS.md はその簡易な代替手段として扱われていて、まず AGENTS.md や .cursor/rules で方針を定義し、その方針を背負った agent を Automations で必要なタイミングに起動する、という関係で整理すると腑に落ちます。
旧来の .cursorrules もサポートは続いていますが、軸足は Project Rules、つまり .cursor/rules 側に移っています。
同ブログでは過去の運用で頻繁にトリガーが発生し多数の不具合を検出したと説明していますが、たとえば「1日あたり数千回」「数百万件」といった具体的な数値については、集計期間や計測方法が本文上で明示されていないため、概況説明として扱うのが安全です(注: 詳細は該当ブログ記事を参照してください)。
ここがうれしい点でもあります。
従来は「この PR を見て」「この障害を要約して」「このチケットを起票して」と、その都度人がプロンプトを投げていました。
Automationsが入ると、その都度呼び出す運用から、レビュー、監視、保守といった後工程を待ち受けで回す運用に変わります。
GitHub で PR を開くと、数十秒から数分で Slack に要約や注意点が届く形にしておくと、感覚としては“自走するレビューボット”に近いです。
人が依頼して動かすのではなく、出来事に反応して agent 側から仕事を取りにくるため、開発フローの後半が詰まりにくくなります。
関連機能の違いを一枚で整理する
| 項目 | Cursor Automations | Cursor Rules | Bugbot |
|---|---|---|---|
| 主目的 | イベントやスケジュールで agent を自動起動する | エージェントへの恒久的な指示を定義する | PR レビューを自動化する |
| 起動方法 | Slack、GitHub、Linear、PagerDuty、Webhook、Timer | agent 実行時に文脈として適用 | PR のオープン・更新時 |
| 主な用途 | レビュー、監視、障害対応、起票、通知 | 規約、出力方針、プロジェクト文脈の共有 | バグ検出、コードレビュー |
| 実行の位置づけ | cloud agents の実行基盤 | 行動ルールの定義層 | Automations の先行例に近い機能 |
Cursorが公式に語っている方向性も、この整理と一致しています。
コード生成そのものだけでなく、その後ろにあるレビュー、監視、保守の工程へ agent を伸ばすという発想です。
開発者が IDE の前で明示的に指示する世界から、リポジトリや運用ツール側の出来事を受けて自律的に動く世界へ踏み込んだのが、Cursor Automationsの輪郭だと捉えると混乱しません。
まず押さえたい仕組み:トリガー・エージェント・MCP・ガードレール
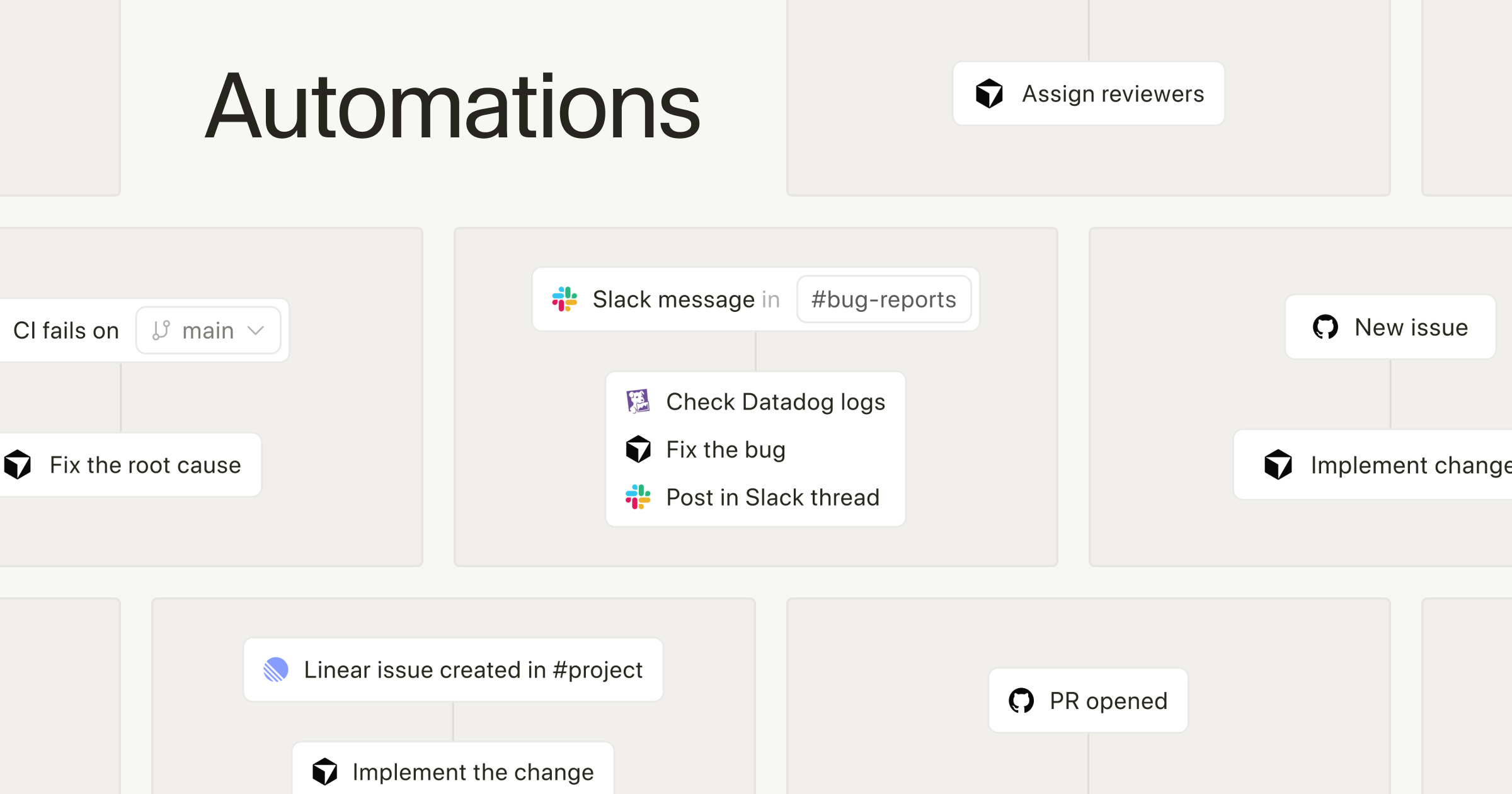
全体フロー
Cursor Automationsの動きは、4つの段階に分けると頭の中で整理できます。
まずSlackLinearGitHubPagerDuty、あるいは Webhook や Timer がトリガーになります。
たとえばGitHubで PR が開かれた、Slackで特定のメッセージが投稿された、PagerDutyでインシデントが発生した、といった出来事が起点です。
次に、そのイベントを受けてクラウド側のサンドボックス上でエージェントが起動します。
ここでのポイントは、ローカルのCursorを開いていなくても処理が進むことです。
人が席を外している間でも、レビュー、要約、起票、通知といった後工程が裏側で回ります。
実際にこの考え方で捉えると、「AI に依頼する」のではなく「条件がそろったら AI が出動する」運用に変わるんですよね。
その後、エージェントは必要に応じて外部ツールや MCP を使って情報を取りに行き、処理を組み立てます。
GitHub から差分や PR 情報を取得し、Linear からチケット内容を参照し、PagerDuty のイベント情報を読んで、そこから要点整理やコメント生成を進める流れです。
ルール面では、前述の .cursor/rules に置いた方針が「どう振る舞うか」の土台になります。
たとえば「レビューコメントは日本語で返す」「破壊的変更は提案までに留める」といった指示をあらかじめ持たせておくと、毎回プロンプトで細かく縛らなくても動作がぶれにくくなります。
処理が終わると、結果をSlackのスレッド、GitHubの PR コメント、Issueの更新などに返す形になります。
つまり、Automations は単独で完結する機能ではなく、外部イベントを受け取り、クラウド上で実行し、必要な文脈を集め、元の仕事場に結果を戻すための配線です。
この「イベント起動の cloud agent」という位置づけが軸になっています。
この流れを実務に当てはめると、設計時に見るべきポイントも自然に決まります。
どのイベントで起動するのか、どのツールに触らせるのか、どこへ結果を返すのか、そしてどこまでの操作を許可するのかです。
ここで曖昧さを残すと、便利さより先に運用負荷が増えます。
たとえばレビュー専用の automation なのに書き込み権限まで持たせると、意図しない変更提案が混ざることがあります。
逆に、対象リポジトリ、変更許可範囲、実行時間、レビュー承認の要否を先に決めておくと、導入直後でも挙動を追いやすくなります。
ガードレールは、AI の自由度を下げるためではなく、担当範囲を明確にするための枠として考えると納得しやすいのが利点です。
人のチームでも「この担当は一次切り分けまで」「本番反映は承認後」と分けるはずで、Automations でも同じです。
特に最初の1本は、「コメント返却だけ」「PR への要約貼り付けだけ」といった非破壊の役割に絞ると、運用の輪郭が見えます。
MCPの補足(1行)

MCP(Model Context Protocol)は、エージェントが外部システムやツールと安全にやり取りするための共通規格です。
ツール連携の例
ツール連携は、抽象論より具体例で見たほうがイメージが固まります。
たとえばGitHub APIで PR の差分を取得し、その変更内容を要約してSlackへ返す構成は、もっとも入りやすいパターンです。
レビュー担当者はまず差分全体の要旨を把握したいので、ファイル数、影響範囲、気になる変更点が自動でまとまっているだけでも、PR を開いた直後の判断が速くなります。
Linear APIとの組み合わせも実務効果が出やすいところです。
筆者は、Slackに流れたメッセージからLinearのチケット ID を拾い、MCP 経由でタイトルや優先度、関連情報を取得して、その要点をGitHubの関連 PR に貼り付ける流れだけでも十分役に立つと感じています。
人が毎回Linearを開いて確認し直す往復が減るので、PR を見た時点で「これは何の作業か」がほぼ把握できます。
機能として派手ではありませんが、日々のレビューではこういう接続のほうが効きます。
PagerDutyをトリガーにした障害対応も、Automations の相性が良い領域です。
インシデント発生時に、イベントのメタ情報を取得し、関連リポジトリや直近の変更候補をまとめてSlackへ投稿する形なら、初動で必要な情報がひとつの場所に集まります。
さらに状況によってはGitHubに調査用の Issue や PR を起票するところまでつなげられます。
人手でやると、通知を見て、監視画面を開いて、変更履歴を調べて、共有文面を書く、という順番になりますが、その前半を cloud agent に肩代わりさせるわけです。
こうした連携を組むときは、接続先を増やすこと自体が価値なのではなく、1回のトリガーで必要な文脈を集めて、次の担当者がそのまま動ける状態にすることが価値になります。
GitHubで差分取得、Linearで背景取得、PagerDutyで障害情報取得、Slackで共有、という並びはその典型です。
補足として、外部解説ではメモリやナレッジ参照の活用に触れているものもありますが、このあたりは現時点では補足情報として捉え、まずは公式に確認できるトリガー、ツール連携、返却先の流れを軸に理解しておくと混乱しません。
Cursor Rules や Bugbot と何が違うのか
役割の違いを整理
Cursor AutomationsCursor RulesBugbotは、同じ「AI が開発フローに入る機能」に見えても、担当しているレイヤーが違います。
混ざって見える原因は、どれもGitHubの PR やレビュー文脈に関わるからですが、実際には「何を起動する仕組みか」「何を指示する仕組みか」で切り分けると整理できます。
まずRulesは、エージェントに対する恒久的な行動指示です。
プロジェクトで共通化したいレビュー観点、出力言語、禁止事項、提案の粒度などを持たせる場所で、現在の推奨は .cursor/rules です。
Project Rules としてこの構成が案内されており、AGENTS.md は簡易な代替として扱われています。
以前から使われてきた .cursorrules は継続サポートされていますが、これから整備するなら .cursor/rules を前提に考えたほうが文脈に沿っています。
一方のAutomationsは、条件付きでエージェントを起動する実行基盤です。
Slackのメッセージ、GitHubの PR 更新、Linearのイベント、PagerDutyの通知、Webhook、Timer といったトリガーを受けて、cloud agent を走らせます。
つまり「どう振る舞うか」を決めるのが Rules で、「いつ動かすか」「どのイベントで走らせるか」を決めるのが Automations です。
この位置づけは一貫しています。
Bugbotは、その中間にある別カテゴリではなく、PR 自動レビューを具体化した先行例として捉えるとズレません。
役割としては「レビュー自動化の実装例」に近く、Automations が一般化する前から見えていた、Cursor 流の自動化の原型です。
Bugbot そのものはレビュー用途にフォーカスしていますが、Automations はその考え方をレビュー以外にも広げた土台だと考えると理解が早いです。
短く対比すると、次のようになります。
- 起動方法
- Cursor Rules: エージェント実行時に文脈として適用
- Cursor Automations: イベントやスケジュールで自動起動
- Bugbot: PR のオープンや更新で起動するレビュー自動化
- 用途
- Cursor Rules: コーディング規約、出力方針、プロジェクト文脈の固定
- Cursor Automations: レビュー、監視、障害対応、起票、通知
- Bugbot: バグ検出、コードレビュー
- 実行環境
- Cursor Rules: IDE や agent の指示レイヤー
- Cursor Automations: cloud agents / cloud sandbox
- Bugbot: 自動レビュー機能としての運用レイヤー
- 主目的
- Cursor Rules: 振る舞いを揃える
- Cursor Automations: 条件に応じて実行する
- Bugbot: PR レビューを自動化する

Cursor Docs
Cursor is the best way to build software with AI.
docs.cursor.com関係性

この3つは競合ではなく、むしろ組み合わせて使う前提で見ると腑に落ちます。
Automations で起動したエージェントは、プロジェクト側に置かれた .cursor/rules や AGENTS.md を文脈として参照できます。
つまり、Automations は実行の入口で、Rules はその中で動くエージェントの判断基準です。
この関係が効いてくるのは、レビュー品質の一貫性です。
たとえば同じ PR を見ても、Rules が未整備だと「命名だけ細かく指摘する回」と「設計意図まで踏み込む回」が混ざりやすく、コメントの口調も揺れます。
逆に Rules を整えると、同じ PR でも警告の粒度と口調が安定し、レビュアーが再確認で使う時間が目に見えて短くなる感覚があります。
自動化の価値は件数をさばくことだけでなく、毎回の出力をチームの流儀に寄せられる点にもあります。
公式ブログでは、Bugbot の運用を通じて多くの不具合が検出された旨が述べられています(出典: Cursor 公式ブログ)。
「1日あたり数千回」「数百万件」といった定量表現は集計条件が明記されていないため、公式が概況としてそのように表現している点は留意が必要です。
誤解防止
よくある誤解は、「Automations を使うなら Rules は必須なのか」という点です。
公式ドキュメントで Rules の必須/非必須が明確に定義されているわけではありません。
実務上は、Rules を設定せずともトリガーで agent を起動する構成は取り得ますが、出力の一貫性や再現性を求める運用では Rules を整備することが実務的に推奨されます(運用方針として Rules を用意する理由を先に決めると導入が安定します)。
もうひとつ混同されがちなのが、AGENTS.md と .cursor/rules の関係です。
どちらもエージェントへの指示を書けますが、現在の主軸は .cursor/rules です。AGENTS.md は軽量に始めたいときの入口として便利ですが、プロジェクト内でルールを育てていくなら、推奨されている配置に寄せたほうが管理しやすく、後から見たときにも意図を追いやすくなります。.cursorrules を見かけることもありますが、これは旧来の流れを引き継いだ形式で、今からの基準としては .cursor/rules を中心に考えるのが自然です。
ℹ️ Note
Automationsを「起動の仕組み」、Rulesを「振る舞いの基準」、Bugbotを「レビュー自動化の具体例」と置くと、機能の重なり方で迷いません。
導入の始め方
作成の入口は Cursor の Automations ページです。
ここから新規の Automation を作成できます。
UI のボタン表記や画面の細部は時期によって変わることがあるため、概念的には「作成 → トリガー選択 → Agent 定義 → 出力先設定 → テスト → 有効化」という流れを押さえてください。
スクリーンショットがなくても進められる最小手順に絞ると、流れは次の5段階です。
NewもしくはCreateから新規 Automation を作成するTriggerを選ぶAgentを定義するOutputの送り先を設定する(例: Slack、PR、Issue のいずれか)- 設定を保存してテスト実行します。意図した出力になることを確認してから有効化してください。UI 上のボタン表記は時期により変わるため、概念的には「作成 → トリガー選択 → Agent 定義 → 出力先設定 → テスト → 有効化」という流れを押さえておくと迷いません。
ここで詰まりやすいのは、2 と 3 を一度に考えようとする点です。
まず Trigger では「何をきっかけに起動するか」だけを決めます。
最初の候補としては Timer、Slack mention、PR opened の3つがわかりやすいのが利点です。Timer なら決まった時刻に動き、Slack mention なら誰かが呼び出したときだけ動き、PR opened ならレビュー系の入口になります。
最初の1本なら、毎日か毎時で動く Timer が扱いやすく、挙動の追跡もしやすいのが利点です。
次に Agent では、使うモデル、参照させるルール、実行権限を決めます。
前述の通り、プロジェクト側に .cursor/rules があれば、それを読ませるだけで出力の口調や判断基準が揃いやすくなります。
ここで広い権限を渡す必要はありません。
最初は読み取り中心、あるいは通知を返すだけの設定に寄せたほうが、失敗しても影響範囲が狭く収まります。
Output は、結果をどこへ出すかの設定です。
候補は Slack、PR、Issue などが中心になります。
通知目的なら Slack、レビュー文脈に乗せたいなら PR、あとで追跡したいなら Issue が自然です。
作って終わりではなく、Save & Test で一度走らせ、意図した出力になることを見てから Enable します。
この順番にしておくと、いきなり本番運用に入って想定外の投稿が飛ぶ事故を避けやすくなります。
最初は通知専用かスケジュール実行から入る

公式のテンプレートを利用すれば、テンプレートを元に必要項目を埋めるだけで開始できます。
初回はゼロから全部組み立てるより、通知専用か毎日・毎時のスケジュール実行から入ることをおすすめします。
私なら最初の1本は、Timerで毎朝動かして、Slack DMに「昨晩の PR 要約」を送る形から始めます。
これだと変更を自動適用するわけではなく、届く先も自分の DM に限定できます。
影響範囲が小さいので試行錯誤しやすく、翌朝に未確認の PR を拾い直す手間も減ります。
自動化の価値をいきなり大きなフローで証明しようとすると調整項目が増えますが、朝の情報整理を肩代わりさせる程度の用途なら、良し悪しの判定も明快です。
導入前に見ておきたい初回チェック項目
初回導入では、設定画面を埋める前に4点だけ頭の中で整理しておくと、途中で止まりません。
- トリガー: いつ、何を条件に起動するのかを定める
- 権限: agent に何を読ませ、何を触らせるのかを定める
- 通知先: 誰に、どこへ返すのかを指定する
- ガードレール: 承認、上限、対象範囲をどう絞るのか
この4つのうち、初回で差が出るのは権限とガードレールです。
たとえば PR opened を使うとしても、全リポジトリを対象にするのか、特定のリポジトリだけに絞るのかで運用の重さが変わります。
通知先も、いきなりチームの共有チャンネルへ流すより、自分向け Slack DM や限定チャンネルに閉じたほうが挙動を観察しやすくなります。
承認フローを入れられる場面では、人が確認してから次のアクションに進む形にしておくと、導入直後の想定外を吸収しやすくなります。
この段階で目指すのは、立派な自動化基盤を一気に作ることではなく、1トリガー、1出力、1目的で回る Automation を作ることです。
1本目が素直に動けば、そこに .cursor/rules を足して出力を揃えたり、Slack から PR や Issue に広げたりと、拡張の方向が見えてきます。
現場で使えるユースケース5選
導入初期の Automation は、単に「自動で動く」だけでは価値が見えにくいものです。
実感を持ちやすいのは、レビュー待ち、起票漏れ、初動の遅れといった日々の小さな詰まりを減らす場面です。
Cursor Automationsの強みは、GitHub、Slack、Linear、PagerDuty、Timer など、開発チームがすでに触っている入口から cloud agent を起動できる点にあります。
ここでは、実際の現場で組み込みやすい5つの使い方に絞って見ていきます。
PRセキュリティレビュー(PR起点)
もっとも導入イメージを持ちやすいのは、PR が開かれた瞬間にセキュリティ観点のレビューを走らせるパターンです。
コード差分を見て、認証まわりの抜け、危険なシリアライズ、入力値検証の欠落、秘密情報の露出につながる記述など、脆弱パターンを先に拾います。
あわせて依存パッケージの更新内容も確認し、既知の注意点がある変更なら、その要点だけをレビュアーに返す流れです。
このとき出力先を PR コメントにするか、Slackにするかで運用の手触りが変わります。
PR 内に残せば監査線が残り、共有チャンネルに送ればチームの目に早く触れます。
私の感覚では、PR 作成直後に“危ない臭い”のある変更だけでもSlackにハイライトされると、レビュアーの意識が散りません。
全件を重く読む前に、どこへ注意を向けるべきかが揃うからです。
さらに一歩進めるなら、問題の指摘だけで終えず、修正提案の下書きまで返す構成が効きます。
たとえば「この入力は allowlist で絞る」「このトークンはログへ出さない」「依存更新に伴う breaking change の確認項目はここ」といった形で、コメント案や修正パッチの叩き台を返すわけです。
Cursorがセキュリティ運用で PR 処理速度を 9 か月で 5 倍に伸ばしたと書いているのも、こうした前さばきが効く仕事に agent を置いたからだと読むと納得感があります。
近い発想が確認できます。

Securing our codebase with autonomous agents · Cursor
Cursor's security team built a fleet of security agents to find and fix vulnerabilities across a fast-changing code
cursor.comリスク分類とレビュアー割当(GitHub/Linear連携)

PR レビューが滞る原因は、単純に件数が多いことだけではありません。
誰が見るべき変更なのかが曖昧なまま流れると、手の早い人に負荷が偏ります。
そこで効くのが、GitHub 上の変更内容を読み取り、影響度を 3 段階でタグ付けして、必要ならLinear側にも反映しながら専門レビュアーを割り当てる Automation です。
たとえば UI テキストの修正と、認証基盤の変更と、決済処理の差分は、同じ「1 PR」でも重みがまったく違います。
変更ファイル、依存差分、触っているディレクトリ、過去の障害履歴といった文脈を見て、low、medium、high のように分類しておけば、レビューの並び順が整います。
high に分類されたものだけはセキュリティ担当やオーナーへ自動でアサインし、low は通常キューへ流す形にすると、チーム全体の判断コストが下がります。
ここでCursor Rulesや .cursor/rules を併用しておくと、「payments 配下は必ずこのメンバー群へ」「auth を触る変更は high 扱いに寄せる」といった組織固有の基準を agent に持たせられます。
単なるキーワード判定より現場の感覚に寄るので、タグ付けの納得感も上がります。
Bugbot 的な自動レビューの流れを、レビュー内容だけでなく、レビューの交通整理まで広げるイメージです。
Slack上のバグ報告→Linear起票(Slackトリガー)
日常運用で効き目を感じやすいのは、Slackに流れた不具合報告を、そのままLinearの起票までつなぐ使い方です。
バグ報告は会話の中に埋もれやすく、「誰が見たか」「再現条件は何か」「スクリーンショットはあるか」が揃わないまま流れます。
そこで Slack トリガーで agent を起動し、テンプレートに沿って要点を抽出し、再現手順、発生環境、ログ断片、期待動作と実際の挙動を整えてLinearにチケット化します。
このワークフローの価値は、単に入力を代行することではありません。
会話文をそのまま転記すると、あとで読んだ人が解釈に時間を取られます。
agent が「発生条件」「再現手順」「影響範囲」「添付ログ」に整理してから起票すると、着手時の迷いが減ります。
朝一で夜間のSlack報告がLinearに整理済みになっていると、デイリースタンドアップの立ち上がりが目に見えて軽くなります。
未整理のスレッドを読み返す時間が消えるので、話題の選別から始めずに済みます。
💡 Tip
バグ報告の整形 Automation は、最初から全チャンネルを対象にせず、障害報告や QA 用の限定チャンネルに絞ると、ノイズの少ない運用にまとまります。
イベント起点で起票や通知へつなぐ方向性が示されています。この種の用途は、コード生成よりも「情報の型を揃える」仕事に agent を当てる好例です。
Build agents that run automatically · Cursor
Cursor now supports automations that run based on triggers and instructions you define.
cursor.comPagerDuty起点の障害調査(PagerDutyトリガー)
障害対応で最初に必要なのは、深い分析より状況整理です。
PagerDutyでインシデントが発報した瞬間に Automation を走らせ、関連サービス、直近デプロイ、既知障害、監視アラート、変更履歴を集めて、Slackへ初動メモを投稿する構成は、オンコールの負担を目に見えて軽くします。
人が最初の 10 分でやっている「何が落ちたのか」「直前に何を入れたのか」「過去に似た事故はあったか」を先に束ねる役割です。
実運用では、初動メモに加えて修正 PR の雛形まで出せると強いです。
たとえば、ロールバック候補のコミット、関連設定ファイル、影響がありそうな feature flag、確認すべきログの場所を本文に埋めた PR テンプレートを作っておくと、担当者はゼロから書き始めなくて済みます。
障害時は「書く」より「判断する」側に時間を残したいので、ここを自動化する意味は大きいです。
この手の初動自動化は、長い調査を置き換えるというより、最初の空白時間を埋めるためのものです。
発報直後のチャンネルに、関連情報がまとまった一枚のメモがあるだけで、参加メンバーの認識が揃います。
会話が「何が起きたかわからない」から始まらず、「どの仮説から切るか」に入れるのは大きな差です。
セキュリティドリフト監視(スケジュール実行)

レビューや障害対応のようなイベント起点だけでなく、Timer で定期実行する監視系も相性がいい用途です。
代表例が、セキュリティルールからの逸脱や設定ドリフトの検査です。
権限設定、CI の保護ルール、秘密情報の扱い、依存ポリシー、危険な例外設定などを、決まった時刻に見回して、逸脱があればオーナーへ通知します。
ここでは「正しい状態」をコードやテンプレートとして持っておくことが効きます。
Cursorのセキュリティ系記事でも、Invariant Sentinel のように守るべき不変条件を定義して監視する発想が出てきます。
たとえば「main への直接 push を許さない」「本番系 secrets を平文で保持しない」「特定ディレクトリの権限変更には承認を要する」といった条件を agent に読ませ、差分を検査する形です。
イベント単位では見逃す小さなずれも、毎日あるいは毎時の点検にすると拾いやすくなります。
このユースケースは目立つ成果が派手に出るものではありませんが、静かに効き続けます。
問題が起きたあとに「いつからずれていたのか」を追うより、ずれた時点でオーナーへ知らせるほうが運用コストは低く収まります。
PR レビューで入口を締め、スケジュール実行で継続監視する組み合わせにすると、単発チェックでは届かない範囲までカバーできます。
導入時の注意点:コスト・権限・誤動作
コスト
Cursor Automationsは、固定回数のジョブ実行というより、使った分だけ増減する運用コストとして捉えるほうが実態に合います。
とくに agent に長い会話履歴や大きな差分、関連ファイル一式を渡す構成では、1回の実行が軽い通知ワークフローとは別物になります。
短い要約を返すだけの Automation と、PR 全文を読み込んで修正案まで生成する Automation では、同じ「1回実行」でも重さが違います。
増えやすい要因は見えやすくて、重いモデルを使う、長いコンテキストを渡す、トリガー頻度を高くする、そして Max モード寄りの設定にする、の4つです。
たとえばGitHubの PR 更新ごとに走らせるレビュー系は、差分が大きい週に一気に跳ねますし、SlackやPagerDutyからのイベントをそのまま全部受ける設計も、夜間障害やアラート集中時に実行回数が膨らみます。
Cursorの料金まわりは 『Models & Pricing | Cursor Docs』 で追うのが前提で、本稿での料金確認日は 2026-03-18 です。
運用に入ると、最初に気づくのは「賢くしたくて文脈を足すほど、請求の見通しが読みにくくなる」という点です。
私自身、最初は関連 Issue、直近コミット、障害ログ、過去のSlackスレッドまで一度に読ませたくなりますが、その設計はだいたい重くなります。
まずは入力を削っても成立する最小構成で始めて、精度不足が出た場所だけ文脈を足すほうが、コストも挙動も安定します。
Models & Pricing | Cursor Docs
Explore all frontier coding models, two usage pools, plan pricing, and per-model API rates.
cursor.com参考単価(外部解説)
Auto モードの目安としては、『Cursor Pricing Explained 2026』 で次のように整理されています。
cache read が $0.25 / 1M tokens、input が $1.25 / 1M tokens、output が $6.00 / 1M tokens。
出力単価のほうが高いので、長文レポートや修正パッチを毎回返す Automation は、短い分類や通知より費用が乗りやすい構造です。
ここで見落としやすいのは、入力より出力が効いてくる場面があることです。
たとえば「障害ログを読んで 3 行で要約」ならまだ抑えやすい一方で、「原因候補、影響範囲、対処方針、PR 下書きまで全部返す」設計だと、output が膨らみます。
参考単価は外部解説ベースなので、実運用では公式の価格表示を優先して読む前提になりますが、何にお金が乗るのかを掴むには十分役立ちます。
Cursor Pricing Explained 2026 | Vantage
Cursor might feel like “just a dev tool” but it's infrastructure spend hiding in plain sight. Therefore it's i
www.vantage.shトリガー頻度の見積もり

頻度の見積もりでは、1回ごとの重さだけでなく、何回走るのかを先に洗うのが肝になります。
大規模運用の話に見えますが、考え方は小さなチームでも同じで、自チームでは「PR 数」「Issue 数」「Alert 数」に「再実行回数」を掛けるだけでも、ざっくりした輪郭が出ます。
たとえば PR 更新のたびに再実行するレビュー Automation は、PR 本数そのものより、レビュー指摘後の push し直し回数で増えます。
障害対応系は通常時の件数ではなく、アラートが連鎖した日の山で見ないと、実態を外します。
夜間にアラートがまとまって鳴るチームでは、試行 2 回で失敗したらSlackに控えめな通知だけ残して止める構成にしておくと、アラート嵐の中で bot まで騒がしくなる事態を避けられます。
人が眠れない原因を増やさない、という意味でこの設計は効きます。
フェイルセーフも頻度設計の一部です。
タイムアウトや外部 API エラーのたびに即再試行すると、同じ失敗を短時間で積み上げます。
通知だけして止める、再試行の回数を絞る、間隔を空ける、という制御がないと、障害時ほど Automation がノイズ源になります。
自動化は「止まらず動くこと」より、「怪しいときは静かに止まること」に価値が出る場面があります。
権限最小化
MCPや外部連携は便利ですが、導入初期ほど権限を削る方向で設計したほうが事故を防げます。
GitHubSlackLinearPagerDutyの各連携では、読めれば十分な工程と、書けないと成立しない工程を分けて考えるのが基本です。
たとえば PR の要約、障害メモの生成、Issue 下書きの作成は読み取り中心でも回せます。
一方で本番反映や設定変更まで自動化すると、誤動作の影響が一段上がります。
最初の段階では、書き込み系をオフにするか、下書き限定に寄せるのが安全です。
GitHubならコメント投稿は許可してもマージは人間に残す、Linearならチケット作成までに留めて状態変更は担当者が行う、Slackなら専用チャンネルへの通知だけに絞る、といった切り分けです。
これだけでも自動化の恩恵は出ますし、誤った判断が本番フローへ直結しません。
人間レビューを残す場面も、あらかじめ線を引いておく必要があります。
本番環境への自動反映、セキュリティポリシー変更、重大インシデント時の意思決定は、Automation の守備範囲から外しておくほうが運用が荒れません。
agent が材料を集め、要点を整理し、PR や提案文を下書きするところまでは相性がいいのですが、実行責任まで委ねると、判断の背景が薄いまま進みやすくなります。
導入時に求めたいのは、全自動で置き換えることではなく、人が判断すべき瞬間に集中できる状態を作ることです。
小さく始める運用テンプレート
おすすめ順序
運用テンプレートは、通知から始めて、次に調査、続いて提案 PR、承認を伴う自動処理はその後に置く流れが崩れにくい設計です。
Cursor AutomationsはSlackGitHubLinearPagerDutyなど複数の起点を持てますが、導入直後から書き込みや承認まで一気に広げると、精度の検証より先に影響範囲だけが広がります。
最初の一手は、イベントを受けて状況を要約し、人へ知らせるところに留めるのが定石です。
通知の次に置きたいのが調査です。
たとえば PR 更新やアラート発生をきっかけに、関連ログ、直近コミット、Issue の文脈を読ませて「何が起きているか」を整理させます。
この段階では、エージェントが判断した結論そのものより、拾ってきた材料が妥当かを見るほうが価値があります。
Cursor Automations 公式発表でも、コード生成の後工程としてレビュー、監視、保守へ自動化を広げる位置づけが示されており、いきなり実行より観測と整理から入る考え方と噛み合います。
提案 PR は三段目に置くと収まりがよくなります。
通知と調査で「どの情報を読ませると当たりが良いか」「どの条件でノイズが増えるか」が見えたあとなら、修正案のドラフト化に進めます。
ここでもマージやデプロイまでは渡さず、差分の下書きを人が受け取る形にしておくと、作業時間だけを削りつつ責任の線引きを保てます。
実際、私はこの順序を崩して先に変更系を動かしたとき、直せる不具合より「直さなくてよかった差分」の扱いに時間を取られました。
自動承認は、精度と監査の両方が揃ってから扱う領域です。
前述の通り、自動化の価値は全工程を機械に渡すことではなく、人が見るべき瞬間を絞ることにあります。
承認まで含めると、誤判定そのものより「なぜ通ったのか」が追えない状態が問題になります。
少なくとも導入初期は、通知、調査、提案 PR の三段で回し、承認系は別レイヤーとして切り離したほうが運用の摩擦が少なくなります。
私の経験では、最初の 2 週間は観測モードとして回し、週次で誤検知と無駄通知を一つずつ削ると、その後の安定度が一段上がります。
この期間に見るべきなのは、賢い出力が出た回数ではなく、放置された通知と読まれなかった提案です。
そこに運用上の無理が集まるからです。
失敗しにくい初期設定

初期設定でまず効くのは、トリガーをスケジュールのみに寄せることです。
イベント駆動は便利ですが、PR 更新やアラート連鎖のたびに走らせると、導入直後は挙動の把握より実行の多さに気を取られます。
朝夕の定時チェックや平日だけの定期実行にしておくと、結果をまとめて見返せますし、失敗時の影響も局所に収まります。
対象リポジトリも最初から広げないほうが安定します。
共通基盤、運用負荷の高いサービス、変更頻度の高いアプリを一括で入れるより、まずは 1 つか少数のリポジトリに限定し、そのチームの流儀で回るかを見るほうが筋が良いです。
Cursor Rulesを併用しているなら、.cursor/rules 側にレビュー観点や禁止事項を寄せ、Automation 側は起動条件と出力先だけに絞ると責務が分かれます。
Rulesは恒久指示の層なので、運用ルールをそちらに置くと Automation 定義が肥大化しません。
通知先は、導入初期だけ DM に寄せるのが失敗を減らします。
Slackの公開チャンネルへ最初から流すと、精度が固まる前の通知がチーム全体のノイズになります。
担当者かオーナーへの DM に限定しておけば、見直しのサイクルを静かに回せます。
そこで当たり外れが揃ってから専用チャンネルへ移す流れのほうが、チーム内の印象も悪くなりません。
変更系アクションはドラフト PR までで止めるのが無難です。
コメント投稿や差分生成までは許可しても、レビュー依頼、自動マージ、状態遷移まで一気に持たせる必要はありません。
ドラフト PR であれば、タイトル、要約、変更理由、想定影響をひとまとめに残せるので、人が介入する入口として扱いやすくなります。
PR 処理速度の改善事例はSecuring our codebase with autonomous 。
実行上限も、最初に文字で明示しておくとブレません。
1 日に何回まで動かすか、1 回の処理をどれくらいで打ち切るか、再試行を何回まで許すかを定義に含めるだけで、暴走時のふるまいが読めます。
ここは UI の項目名より、「回数」と「時間」の上限をチーム文書に残しておくことが効きます。
画面の細部は時期で変わることがあるため、導入時に実画面で対応箇所を見ながら揃える前提です。
運用に入る前の確認項目は、次の 4 つに絞ると抜けが出にくくなります。
| 項目 | 最初に決める内容 | 初期値の置き方 |
|---|---|---|
| トリガー | スケジュールかイベントか、どの条件で起動するか | まずはスケジュールのみ |
| 権限 | 読み取りだけで足りるか、書き込みが必要か | 読み取り中心、変更はドラフト PR まで |
| 通知先 | 誰が最初に受けるか、公開チャンネルに出すか | オーナーへのSlack DM |
| ガードレール | 実行回数、時間上限、停止条件をどう置くか | 回数と時間の上限を明文化 |
監査・可視化
運用が落ち着くかどうかは、精度だけでなく「あとから追えるか」で決まります。
通知先は個人 DM から始めても、定着段階では専用チャンネルを持ったほうが全体の視界が揃います。
障害初動、PR 提案、定期点検の通知が同じ場所に積まれると、どの Automation が役に立っていて、どれが空振りしているかを横並びで見られます。
人が bot を信用するのは、当たりの多さより、外したときに追跡できることのほうが大きいです。
GitHub側ではラベル運用を合わせると、提案 PR や起票の流れが整理されます。
たとえば自動生成物に共通ラベルを付けるだけでも、手動作成のものと切り分けて後追いできます。
修正提案、要確認、観測中といった分類を持たせると、チーム内で「今どこまで人が見たか」も残せます。
通知だけで終わる運用より、ラベルがついた成果物として残る運用のほうが、チューニングの判断材料が揃います。
監査ログは、保存方針を先に決めておくのが肝です。
どのトリガーで起動し、何を読み、どこへ出力し、結果がどうだったかが辿れないと、誤動作の再現ができません。
Cursorの実行 UI は今後も変わり得るので、ボタン名や表示位置を基準に運用文書を書くより、最低限残したい情報を先に定義しておくほうが強いです。
私は、起動条件、対象リポジトリ、入力ソース、出力先、実行結果の 5 点が見えれば、だいたいのトラブルは追えました。
💡 Tip
通知先を専用チャンネルに集約し、成果物には共通ラベルを付け、実行ログの保存項目を固定すると、誤検知の調整が人依存になりません。
可視化は管理者向けの飾りではなく、導入判断を支える実務そのものです。
Cursorは社内で毎時数百回規模の Automations 実行が報じられる運用まで広げていますが、そのスケールでも回る理由は、個々の agent が賢いからだけではなく、挙動を見直せる前提があるからです。
小さく始めるチームほど、通知先、ラベル、ログ保存の 3 点を先に固めたほうが、Automation を「便利そうな仕掛け」ではなく「追跡可能な運用部品」として扱えます。
よくある質問

IDE内の Agent と何が違う?
いちばん大きい違いは、待ち方です。
Cursorの IDE 内で使う Agent は、開発者がその場で話しかけて、手元の文脈を見せながら進める対話型の道具です。
いま開いているファイル、いま気になっているエラー、いま直したい関数に寄り添う使い方が中心になります。
一方のCursor Automationsは、誰かが毎回呼び出さなくても、イベントやスケジュールをきっかけにクラウド側で動きます。
Slackへの投稿、GitHubの更新、Linearの起票、PagerDutyのインシデント、Webhook、Timer といった合図を受けて走るので、使い心地は「対話する assistant」より「待機している運用部品」に近いです。
開発中に横で相談する相手が IDE 内の Agent だとすると、Automations は裏側で定期巡回や一次対応を受け持つ担当です。
この差は、向いている仕事にも表れます。
たとえば実装中のリファクタや設計相談は IDE 内の Agent のほうが噛み合います。
反対に、朝に未対応 PR を集計してSlackへ流す、障害通知を受けてログを要約する、定期的に依存関係の更新候補をドラフト PR にする、といった仕事は Automations のほうが自然です。
手で開いて対話する前提ではなく、条件が揃ったら先回りして動くからです。
個人開発でも使える?
使えます。
むしろ個人開発のほうが、効果を体感しやすい場面があります。
チームの合意や権限設計に時間をかけず、自分の定型作業をそのまま置き換えられるからです。
最初から複雑なワークフローを組む必要はなく、朝にタスク一覧をまとめる、夜に未レビュー PR を通知する、週次で依存更新候補を洗い出す、といった小さな反復作業だけでも十分に意味があります。
個人開発で現実的なのは、Slack通知か Timer 実行から始める形です。
たとえば毎朝決まった時刻に「昨日から止まっている issue」「レビュー待ちの PR」「今週触っていない保守タスク」を流すだけでも、頭の切り替えコストが減ります。
自分で全部覚えておく運用は、忙しい日ほど抜けが出ますが、Automation が先に並べてくれると、その日の最初の判断に集中できます。
私自身、個人で試すときは「通知まで」を先に定着させるほうがうまくいきました。
自動で何かを変更させるより、まず状況を集めて知らせるだけにすると、外れても被害が広がりません。
毎日の定型作業をひとつずつ bot に渡していく感覚で進めると、無理なく運用に乗ります。
必須かどうかで言えば、Rules が技術的に「絶対に必須」と明記されているわけではありません。
ただし、出力の口調や警告の粒度、禁止事項などをチーム水準で揃えたい場合は、Project Rules(推奨配置: .cursor/rules)を整えておくのが運用上は効果的です。AGENTS.md は軽く始めるための入口として便利ですが、長期運用では Project Rules に寄せる運用が管理しやすくなります。
役割分担で考えると。
Automation には「いつ動くか」「何をきっかけにするか」「どこへ出すか」を持たせ、Rules 側には「どんな観点で見るか」「何を禁止するか」「このリポジトリでは何を優先するか」を置く、という切り分けです。
これを逆にすると、Automation ごとに長い指示文が増えて、似た修正を何か所にも入れることになります。
特にレビューコメントや要約文の調子を揃えたいとき、Rules の有無で差が出ます。
同じGitHub連携でも、ある Automation は丁寧語、別の Automation は箇条書き、別のものは観点が抜ける、という状態になると、人が読む側の負担が増えます。
Rules を先に薄く敷いておくと、bot ごとの個性ではなく、チームとしての出力に寄っていきます。
料金はどう考える?

料金は「月額プラン」と「実行の膨らみ方」を分けて考えると整理できます。
まずCursorCursor Proの目安価格が月額 20 ドルです。
加えて、実行内容によってはトークン消費が効いてきます。
外部解説のVantageでは Auto モードの参考単価として、cache read が 100 万 tokens あたり 0.25 ドル、input が 1.25 ドル、output が 6.00 ドルと整理されています。
ここで重くなりやすいのは output です。
長い要約、長いレビュー、差分提案を増やすほど、実行回数だけでなく 1 回あたりのコストも膨らみます。
感覚としては、料金の中心は「何回動かすか」より「何を出させるか」に寄ります。
短い通知なら軽く済みますが、毎回長文の調査レポートや修正案まで書かせると、すぐに効いてきます。
Cursorは自社運用で毎時数百回規模の Automations 実行が報じられているので、運用のスケール自体は現実的ですが、同じやり方をそのまま持ち込むのではなく、まずはしきい値と上限を持たせる設計が前提になります。
実務では、対象件数の上限、1 回の出力文字数、起動条件の絞り込みを最初から入れておくと、費用の読み違いが減ります。
たとえば「未対応が一定件数を超えたときだけ通知する」「PR ごとに全文レビューを書かず、要点だけ返す」「毎分監視ではなく定時バッチに寄せる」といった設計です。
Pricing の数字を見るだけでは足りず、どの Automation が何を出力したかを見ながら調整する運用になります。
どこまで自動化してよい?
線引きは、本番影響の有無で決めるとぶれません。
通知、要約、起票、コメント生成、ドラフト PR までは自動化の相性がよく、日常運用にも乗せやすいのが利点です。
反対に、変更の適用、マージ、本番設定の切り替え、リリースの実行まで bot に持たせると、ひとつの誤判定がそのまま影響になります。
人の確認を残す場所を、最初から決めておくほうが運用は落ち着きます。
現場で納得を得やすかったのは、通知と提案までは自動、マージとリリースは人間、という分け方でした。
この線だと、bot が先回りして材料を集め、人が最終判断を握る形になります。
自動化に前向きな人も慎重な人も、責任の境界が見えやすく、初期の合意形成で揉めにくい設計です。
⚠️ Warning
自動化の対象を「観測」「整理」「提案」に寄せると、導入初期の信頼を崩さずに効果を積み上げられます。自動で実行まで行わせる設計は、承認や監査が整ってから段階的に導入してください。
Cursorのセキュリティ運用では、9 か月で PR 処理速度が 5 倍になった事例もありますが、効いているのは人の判断を消したことではなく、前処理を機械に渡したことです。
Automation に向くのは、情報を集める、候補を並べる、差分を草案にする、といった工程です。
最終的に誰が承認するかを曖昧にしない限り、Automation は「人を置き換える仕組み」ではなく「判断の前段を削る仕組み」として機能します。
まとめと次のアクション
Cursor Automationsは、イベントやスケジュールを起点に cloud agents を動かし、実装後のレビュー、監視、保守を前へ進めるための基盤です。
毎時の定期ダイジェストが回り始めると、会議前の情報収集が一気に短くなり、集める時間より判断する時間に頭を使える感覚が出てきます。
着手は、トリガー、権限、通知先、ガードレールを先に決めて、通知中心の低リスク用途から入るのが堅実です。
料金の目安はCursor公式の Pricing と外部解説を2026年3月時点で確認しました。
- まずは通知中心の Automation を1本だけ作る
AIビルダーの編集チームです。AI開発ツールの最新情報と使い方を発信しています。
関連記事
バイブコーディングとは?始め方とおすすめツール3選
バイブコーディングとは?始め方とおすすめツール3選
バイブコーディングは、2025年2月にAndrej Karpathyが提唱した、自然言語でAIに意図を伝えながらコードを書かせる開発スタイルです。人が「こう動いてほしい」と言葉にし、AIがコードを生成し、人はそれを確かめて直していく。この流れなら、プログラミング未経験でも小さなアプリから形にできるでしょう。
Cursor Agent Modeの使い方|Ask/Plan/Agentの違いと使い分け
Cursor Agent Modeの使い方|Ask/Plan/Agentの違いと使い分け
Cursorのチャットは、Ask・Plan・Agentの3モードを使い分ける設計で、デフォルトはAgentです。Askはコードを変更せずに読み取りだけを行い、Planは調査結果をもとに計画書を作るだけ、Agentは複数ファイルの編集やコマンド実行まで進めます。
MCP自動化パターン10選|導入順と最小手順
MCP自動化パターン10選|導入順と最小手順
筆者の試用では、Jira と Notion を横断して要約する流れを組むと、毎朝の状況把握にかかる時間が短く感じられ、概ね2〜3分程度で済むことがありました。これはあくまで筆者の環境での体験値であり、環境や設定によって大きく変わります。一般化して示す場合は、社内PoCや計測ログなどの出典を併記してください。
Cursor ComposerとAutomationsの違い
Cursor ComposerとAutomationsの違い
Composerは人がCursorのIDE内で対話しながら実装を前に進める高速ループで、Automationsはイベントやスケジュールを起点にクラウドで回り続ける運用ループです。この前提を押さえるだけで、両者を「似たAI機能」とひとまとめにして迷う状態から抜け出せます。