Cursor ComposerとAutomationsの違い
Cursor ComposerとAutomationsの違い
Composerは人がCursorのIDE内で対話しながら実装を前に進める高速ループで、Automationsはイベントやスケジュールを起点にクラウドで回り続ける運用ループです。この前提を押さえるだけで、両者を「似たAI機能」とひとまとめにして迷う状態から抜け出せます。
Composerは人がCursorのIDE内で対話しながら実装を前に進める高速ループで、Automationsはイベントやスケジュールを起点にクラウドで回り続ける運用ループです。
この前提を押さえるだけで、両者を「似たAI機能」とひとまとめにして迷う状態から抜け出せます。
実際、筆者の運用例としては日中に Composer で実装と修正を刻み、夜間は Automations に PR の自動レビューと論点の集約を任せてから、翌朝は人間が判断すべき差分だけに集中できるようにする、という流れにしています。
この記事では、その違いを起点・実行場所・向く業務の3軸で整理し、迷いどころを5パターンに仕分けながら、PRレビュー、Linear起点の定型実装、PagerDuty一次調査まで連携パターンを設計図レベルで示します。
読後には、まずどちらから触るべきかだけでなく、最初の1本をどう作るかまで手を動かせるはずです。
Composer と Automations の違いを先に結論で整理
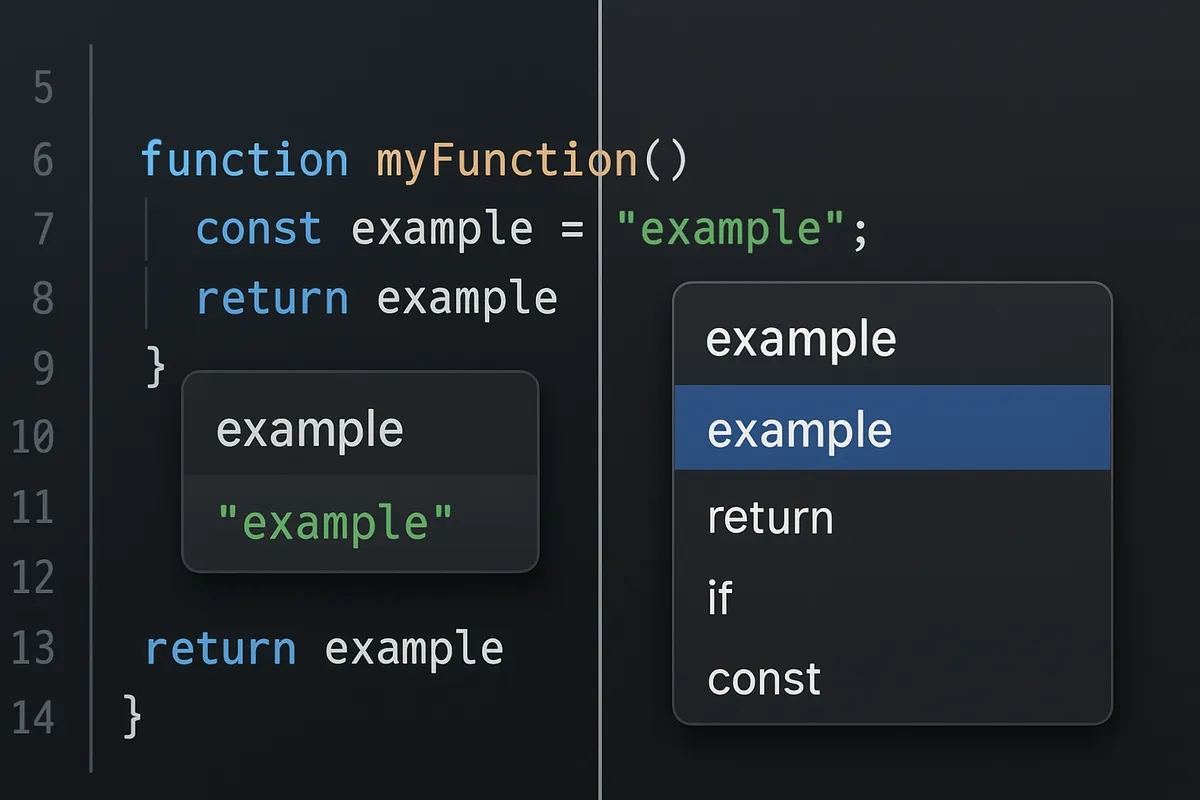
Composerをひとことで置くなら、人がCursorのIDE内で対話しながら実装を進めるエージェントです。
仕様がまだ固まり切っていない段階で、コードベース理解を踏まえて探索し、必要なら複数ファイルにまたがるマルチステップのコーディングを回していく役割を担います。
対してAutomationsは、人の都度指示を待たず、イベントやスケジュールを起点にクラウド側で走る運用エージェントです。
似たAI機能に見えても、起点と置き場が違うので、任せる仕事も自然に分かれます。
Composerの核は、低レイテンシで反復を刻めることです。
ほとんどの対話が30秒未満で終わること、同等知能比で4倍高速であることが打ち出されています。
ここにコードベース全体へのセマンティック検索が重なるので、大規模コードベースでも「まず読んで、次に直して、最後に関連箇所まで寄せる」という往復が途切れません。
実務でも、一回の大きな指示で完成品を求めるより、抽象度を少しずつ調整しながら反復したほうが、実装の精度もレビューの通し方も安定します。
一方のAutomationsは、Slack、Linear、GitHub PR、PagerDuty、Webhookを起点に、スケジュールまたはイベントで自動実行される仕組みです。
実行場所はIDEの中ではなく、クラウドサンドボックス上のCloud Agentです。
そこで設定済みのMCPとモデルを使い、レビュー、監視、調査、後処理のような後工程を引き受けます。
メモリツールを使って過去の実行結果を踏まえた継続学習につなげられる点も、毎回その場の会話から始めるComposerとは性格が異なります。
私のチームでも、朝になるとGitHub PRが積み上がって状況把握だけで時間を取られていましたが、夜間にAutomationsへ集約レビューを回すようにしてから、朝会前に論点だけ見れば全体像がつかめる流れになりました。
3軸の要約表
まずは、迷ったときに戻るための3軸を表にしておきます。
| 軸 | Composer | Automations |
|---|---|---|
| 起点 | 人がIDEで都度指示する | イベント、スケジュール、Webhookで自動起動する |
| 主な実行場所 | IDE内エージェント | クラウドサンドボックス |
| 向く業務 | 実装・修正・探索 | レビュー・監視・調査・後処理 |
この表は、単なる機能比較ではなく、ルーティングの基準として読むと腹落ちしやすくなります。
1つ目の見方は起点です。
人がその場で「この関数を直したい」「この画面の状態管理を整理したい」と投げるならComposer、PR作成や障害通知のように外から信号が来たら自動で処理したいならAutomations、という切り分けです。
Cursor 2.0で並列エージェントの整理が進んでおり、git worktreesで作業領域を分けて相互干渉を避ける設計が示されています。
一部の技術解説では「最大8エージェント並列」の記述が見られますが、この数値は第三者の解説による整理であり、公式ドキュメントでの明確な表記は執筆時点で要確認です。
3つ目の見方は向く業務です。
Composerは、曖昧な仕様を詰めながら進める実装、既存コードの修正、挙動の探索、横断的なリファクタリングに向きます。
セマンティック検索を使って関連箇所を見つけ、マルチステップのコーディングで変更を積み上げる流れが得意だからです。
反対にAutomationsは、GitHub PRの一次レビュー、Slackへの通知集約、PagerDuty起点の初動調査、定期的な保守ジョブのように、決まった入口から繰り返し発生する仕事に向きます。
自動化の深さを決めるときは、この業務軸で見れば、どこまで任せてどこに人のレビューを置くかが決まります。
判断フレーズ集

現場では、厳密な定義より短い判断フレーズのほうが役に立ちます。
たとえば「今から対話しながら実装を詰める」の主語が人ならComposerです。
「誰も触っていない時間にも回っていてほしい」ならAutomationsです。
「コードベースを読みながら複数箇所を直す」はComposer、「PRが来たら自動で論点を集める」はAutomationsに寄ります。
「低レイテンシで細かく往復したい」もComposer側のサインです。
30秒未満で返る前提があると、実装を1回で当てに行くより、短いサイクルで仮説を刻むほうが合います。
逆に「毎回同じ入口から始まる仕事を外出ししたい」ならAutomationsです。
SlackやLinear、GitHub PR、PagerDuty、Webhookのようなトリガーが明確な時点で、対話型より運用型の設計に乗せたほうが流れが整います。
「大規模コードベースで反復実装したい」もComposerを選ぶ理由になります。
コードベース理解とセマンティック検索があるので、局所修正ではなく関連箇所まで含めた変更に入りやすいからです。
「レビュー、監視、調査、後処理をまとめて回したい」はAutomationsの担当です。
クラウドサンドボックス上でMCPとモデルを呼び出し、実行結果を積み重ねていく設計は、日中の手作業を置き換えるより、開発ライフサイクルの後ろ側を支える方向で効きます。
迷ったら、「その仕事は人の会話から始まるか、外部イベントから始まるか」と置き換えると、ほぼ答えが出ます。
ここでComposerを“対話しながら実装を進めるエージェント”として先に定義しておくと、両者を同じ棚に置かずに済みます。
これが見えていると、IDEで育てるべき流れと、クラウドへ渡して常時回すべき流れが混ざりません。
Composer は何に向いているか
低レイテンシと反復実装ループの作り方
Composerが向いているのは、対話しながら実装を前に進める場面です。
役割をひとことで言うなら、IDEの中で開発者の隣に付き、設計、実装、確認を小刻みに回すエージェントと言えます。
ほとんどの対話が30秒未満で完了し、同等知能レベルのモデルと比べて4倍高速という位置づけが示されています。
ここで効いてくるのは、単なる待ち時間の短さではありません。
実装中に「少し依頼する→差分を見る→追加で詰める」という反復実装ループを崩さずに回せることです。
実際に使ってみると、Composerは“一発で完成品を出させる道具”として扱うより、マルチステップのコーディングを細かく刻むほうが結果が安定します。
たとえば「この仕様を全部実装して」ではなく、「まず関連ファイルを洗い出す」「次にAPI層だけ直す」「その後でテストを更新する」と分けると、各ターンの目的がはっきりします。
応答が30秒未満に収まりやすいので、会話のテンポが落ちず、コードレビューに近い感覚で方向修正できます。
筆者がモノレポの横断的な型修正を進めたときも、この刻み方が効きました。
最初に影響範囲だけを調べてもらい、次に狭い差分で型定義を直し、その場でビルドやテスト観点を確認してから、次のパッケージへ進める流れです。
毎回の返答が30秒未満で返ってくるので、「広く直して壊れる」より「狭く直して検証し、次の差分へ進む」ループを作れました。
大規模コードベースでの反復実装は、1回の大仕事として投げるより、この速度を前提に小さな前進を積むほうが噛み合います。

Cursor 2.0 と Composer のご紹介 · Cursor
どちらもエージェントとの連携に特化して設計された、新しいインターフェースと初のコーディングモデル。
cursor.com大規模コードベース理解とセマンティック検索の活かし所

Composerのもう1つの強みは、コードベース理解を前提にした探索と修正です。
大規模コードベースでは、変更そのものより「どこを触るべきか」を見つける時間のほうが長くなりがちです。
ここで効くのがセマンティック検索です。
ファイル名や関数名の完全一致だけでなく、役割や意味の近さから関連箇所を拾えるため、複数ファイルにまたがる変更候補を見つけやすくなります。
この性質は、リファクタリングや仕様変更のように影響範囲が横に広がる作業で特に役立ちます。
たとえば認証ロジックの変更、共通型の更新、APIレスポンス形状の統一といったタスクでは、呼び出し元、型定義、テスト、ユーティリティが別々の場所に散っています。
Composerはセマンティック検索を足場にしてコードベース全体のつながりをたどれるので、「関連箇所の洗い出し」から「修正案の提示」までを1つの流れで進めやすいのが利点です。
実際に大規模コードベースで使うと、最初の依頼を抽象的にしすぎないほうが精度が上がります。
「この不具合を直して」より、「この型変更に連動する利用箇所を探し、まず3ファイル以内で直せる範囲を提案して」のように範囲を切ると、探索と実装の境目がはっきりします。
そのうえで次のターンで広げれば、コードベース理解を保ったまま反復実装を続けられます。
大規模コードベースでの反復実装に向いていると言われるのは、単に文脈を長く持てるからではなく、検索と編集を往復できるからです。
並列エージェント設計(最大8)と git worktree の安全策
たとえば1つの機能追加でも、「設計のたたき台を作る担当」「実装担当」「テスト更新担当」「既存コードへの影響確認担当」に分けると、会話ごとの焦点がぶれません。
並列エージェントに関しては一部解説で「最大8エージェント」と整理される記述も見られますが、出典が第三者記事である点と、公式の明示を要確認であることを踏まえて運用設計してください。
たとえば1つの機能追加でも、「設計のたたき台を作る担当」「実装担当」「テスト更新担当」「既存コードへの影響確認担当」に分けると、会話ごとの焦点がぶれません。
1つの長いセッションに設計議論も実装の細部も失敗調査も入れると、途中から何を前提に話しているのか曖昧になります。
並列エージェントは、その混線を避けるための仕組みとして理解すると納得しやすいのが利点です。
このとき安全策として出てくるのが git worktree です。
エージェントごとに別の作業ツリーを持たせると、同じブランチや同じファイルを同時に触って壊す事故を避けやすくなります。
たとえばAのエージェントはAPI変更、Bのエージェントはテスト追加、Cのエージェントはドキュメント修正という形で分ければ、差分の責任範囲が明確になります。
あとで統合するときも、「どの会話がどの変更を生んだか」を追いやすく、レビューの粒度も整います。
並列化するときは、各エージェントに渡す依頼を短くし、役割を1つに絞るのがコツです。
Composerはマルチステップのコーディングに向いていますが、その“ステップ”を1つの会話内ですべて抱え込む必要はありません。
対話しながら実装を進めるエージェントだからこそ、抽象度を調整しつつ、必要なら担当ごとに分ける使い方が合っています。
用語ミニ解説: git worktree
git worktree は、1つのGitリポジトリから複数の作業ディレクトリを切り出して使う仕組みです。
通常のブランチ運用では、同じフォルダの中でブランチを切り替えながら作業しますが、git worktree を使うと、ブランチごとに別フォルダを持てます。
つまり、同じリポジトリを元にしながら、複数の作業空間を同時に開けます。
Composerとの相性が良いのは、エージェント単位で独立した作業場所を与えられるからです。
Aのエージェントが feature/api-refactor を触っている横で、Bのエージェントは feature/test-update を別ディレクトリで進める、といった形が取れます。
これならファイルの上書きや意図しない変更混入を避けながら、並列エージェント設計を実務に落とし込めます。
言い換えると、git worktree は「複数エージェントを安全に走らせるための作業部屋の分離」です。
Composerを大規模コードベースで使うとき、探索、実装、検証が並行して進む場面が出てきます。
そのときに作業場所まで分けておくと、反復実装の速さを保ったまま、差分の整理と統合も進めやすくなります。
Automations は何に向いているか

トリガー設計
Automationsは、単に「定期実行できる便利機能」ではありません。
役割をひと言で置くなら、常時待機し、条件を満たした瞬間に走る運用エージェントです。
人がCursorのIDE内で都度話しかけるComposerと違って、こちらは人が席にいなくても動きます。
だから向いているのは、新しいコードを書く場面そのものというより、コード作成後のレビュー・監視・調査・保守といった開発ライフサイクルの後工程です。
トリガーとして明示されているのは、Slackメッセージ、Linear issue、GitHub PR、PagerDutyインシデント、Webhook です。
たとえばGitHubのPRが作られたら差分を読んで論点を整理する、PagerDutyでインシデントが起きたら関連ログや直近の変更を集めて一次調査の叩き台を返す、Slackで特定チャンネルの投稿を拾って定型対応に回す、といった流れが自然に作れます。
ここで効いてくるのは、何を起点にするか以上に、どの時点で起動し、どこまで自動で進めるかを設計することです。
この発想はComposerの守備範囲と補完関係にあります。
Composerは低レイテンシで、しかもセマンティック検索を足場にコードベース理解を進めながら、マルチステップのコーディングを反復できるので、大規模コードベースでの反復実装に向きます。
一方でAutomationsは、その実装の後に必ず発生する「見張る」「拾う」「まとめる」「調べる」を自動化する位置に置くと、役割分担がきれいに収まります。
スケジュール vs イベント駆動の使い分け
Automationsにはスケジュール実行とイベント駆動の両方がありますが、使い分けの軸は単純です。
決まった時間に棚卸ししたいものはスケジュール、何か起きた瞬間に反応したいものはイベント駆動です。
スケジュール実行が合うのは、夜間バッチのような集約処理です。
私が実務で手応えを感じたのは、深夜にAutomationsを走らせて、翌朝のSlackには失敗PR、落ちたテスト、要対応issueだけをまとめてもらう運用でした。
朝いちで通知の海を掘るのではなく、前夜の変化が論点単位で圧縮されて並ぶので、人間は判断から入れます。
定型の確認作業を寝ている間に終わらせる、という意味でAutomationsは夜間との相性が良いです。
イベント駆動が合うのは、待ち時間そのものがムダになる場面です。
GitHubでPRが開かれた瞬間にレビュー観点を整理する、Linearにissueが立った瞬間に関連コードや過去の類似対応を引く、PagerDutyのインシデント発生時に初動調査を始める、といった使い方では、トリガーから処理開始までの距離が短いほど価値が出ます。
人間が手で拾いに行く運用だと、通知の見落としや担当の空き時間待ちが入り込みますが、イベント駆動ならその隙間が減ります。
この違いをComposerと対比すると、役割の境界がさらに見えます。
曖昧な仕様を詰めながら複数ファイルを修正し、コードベース理解を更新し続ける作業はComposerが担うほうが速いです。
対話の1往復が30秒未満という低レイテンシは、探索しながら実装を動かす局面で効きます。
反対に、仕様が固まった後のレビュー・監視・調査・保守は、人がその場にいなくても回る形にしたほうが運用全体が整います。
Automationsはそこで力を発揮します。
クラウドサンドボックスと MCP 連携の前提

AutomationsがIDEの補助機能ではなく運用エージェントとして成立しているのは、クラウドサンドボックス上で実行されるからです。
『Cursor Automations 公式ブログ』で説明されている通り、設定済みのMCPとモデルを使ってタスクを走らせる前提になっています。
つまり、開発者の手元で開いているエディタの状態に依存せず、クラウド側で必要な道具立てを持ったまま仕事を進める設計です。
ここでいうMCPは、エージェントが外部の道具やデータ源に触れるための接続面だと捉えるとわかりやすいのが利点です。
SlackやGitHub、Linearのような外部サービスをまたいで情報を取りに行き、結果を返すには、モデル単体では足りません。
クラウドサンドボックスで動くことと、MCP経由で必要な情報源につながることがセットになることで、PRレビュー、障害調査、監視の集約といった実務的な処理が成立します。
この前提があるからこそ、Composerとの分業も明確です。
Composerは人間と並走しながら、セマンティック検索で関連箇所を拾い、マルチステップのコーディングを進める役です。
大規模コードベースで反復実装するときには、この対話ループの速さがものを言います。
対してAutomationsは、すでに存在するコードベースや周辺ツールを相手に、起きたことを拾って処理し続ける役です。
実装そのものより、実装後に発生する運用タスクへ軸足があります。
💡 Tip
Composerを「対話しながら作るエージェント」、Automationsを「待機しながら回すエージェント」と置くと、どちらに任せるべきか迷いにくくなります。
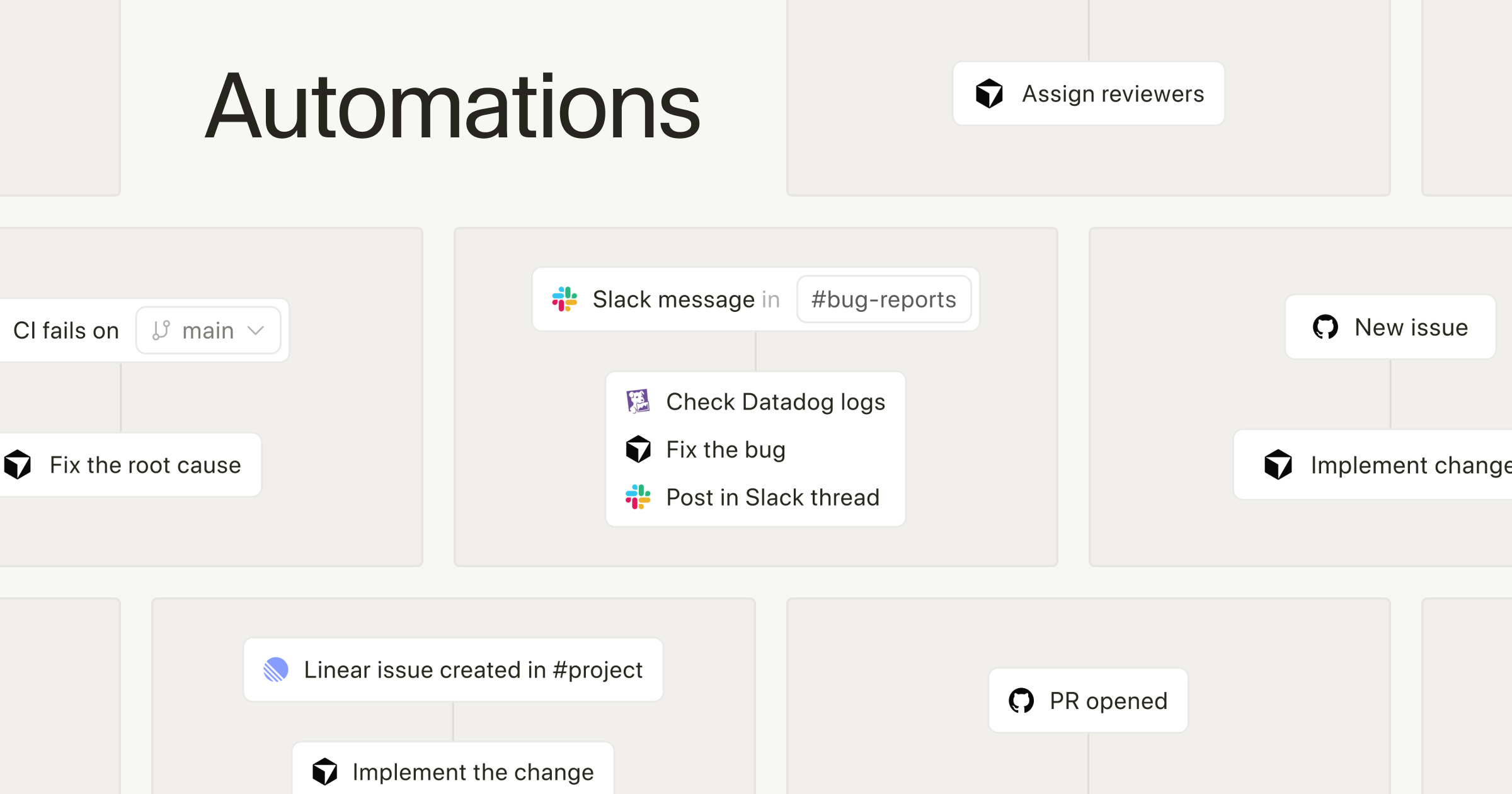
自動実行エージェントを構築する · Cursor
Cursor で、あなたが定義したトリガーと指示に基づいて自動実行される Automations を利用できるようになりました。
cursor.comメモリ活用で“回すほど賢くなる”運用ループ
Automationsの面白い点は、単発ジョブの自動化で終わらず、メモリツールにアクセスできることです。
過去の実行から学び、繰り返すほど精度を上げていく性質があるため、これは単なる省力化というより継続運用の学習効果として捉えたほうがしっくりきます。
たとえばPRの一次レビューでも、最初は「差分要約を返す」だけでも、何度も回すうちに、チームが見落としやすい観点や、毎回確認している論点を拾う形に寄っていきます。
障害調査でも同じで、過去のインシデントでどのログ、どのダッシュボード、どの変更履歴が手がかりになったかを踏まえて、初動の切り口が洗練されていきます。
人間の運用知を、毎回ゼロから思い出すのではなく、反復の中に織り込めるわけです。
この「回すほど賢くなる」感覚は、Composerの速さとは別種の価値です。
Composerは低レイテンシで応答し、30秒未満の短い対話を積み重ねながらコードベース理解を更新していけるので、探索的な実装と相性が良いです。
そこでは一回ごとの往復速度が効きます。
Automationsでは、一回の会話速度よりも、何度も同じ種類の仕事を回したときに精度が上がることが効きます。
レビュー・監視・調査・保守のような後工程はまさに反復の塊なので、学習効果が積み上がりやすい領域です。
用語ミニ解説: MCP とイベント駆動
MCP は、モデルが外部ツールや外部データに触るための接続の仕組みです。
Automationsの文脈では、クラウドサンドボックス上で動くエージェントが、SlackGitHubLinearなどにアクセスして情報を読んだり、結果を書き戻したりするための土台と考えると実務上は十分です。
モデルが賢いだけでは運用は回らず、外部の状態を見に行けることではじめて「仕事」になります。
イベント駆動は、決まった時刻ではなく、出来事をきっかけに処理を始める方式です。
GitHubでPRが開いた、PagerDutyでインシデントが発生した、Slackにメッセージが来た、といった出来事がそのまま起動条件になります。
定時実行よりも反応が早く、変化が起きた瞬間から処理を始められるのが特徴です。
この2つを合わせると、Automationsの像が見えてきます。
外部システムの変化をイベントとして受け取り、MCP経由で必要な情報に触れ、クラウドサンドボックスで処理し、その結果をまた外部ツールに返す。
Composerが人との対話を通じて実装を前へ進めるエージェントなら、Automationsはチームの周辺で常時待機し、条件を満たしたら運用タスクを引き受けるエージェントです。
レビュー、監視、調査、保守に重心があるのは、その仕事が「起きたことへの反応」と「繰り返しの蓄積」で成り立っているからです。
使い分けの判断基準 5パターン

実務で迷うのは、「実装なのか運用なのか」よりも、「今やっている作業が対話で詰めるべきものか、トリガーで回すべきものか」が曖昧な場面です。
そこで私は、作業の起点、途中で判断が増えるか、成果物がコードそのものか運用上の整理か、という3点で切り分けています。
ここを分けておくと、Composerに投げるべき仕事と、Automationsへ預けるべき仕事がぶれません。
ケース1: 単発実装
新しいAPIクライアントを足す、画面の状態管理を組み替える、バリデーション仕様を実装しながら詰める、といった単発実装はComposer向きです。
理由は、最初から仕様が文章で閉じていることよりも、実装の途中で「この抽象化で持つか」「責務の切り方を変えるか」を行き来する場面が多いからです。
IDEの中でコードベースを見ながら対話し、その場で関連ファイルまで広げて修正できる流れが噛み合います。
Cursor 2.0 と Composer のご紹介で案内されている通り、Composerは短い往復を積み重ねる前提で設計されています。
実務でも、一度で完成形を出させるより、まず設計の骨組みを作り、次に例外系を足し、最後に命名や責務分割を詰めるほうが精度が上がります。
抽象から入り、具体の実装で破綻点を見つけ、また抽象に戻る。
この反復が必要な仕事は、Automationsの定型起動よりComposerの対話ループに乗せたほうが前に進みます。
私自身、日中の実装はこの型に寄せています。
仕様書の行数を増やしてから着手するより、短い設計メモを持ってComposerと一緒に形にし、破綻したところだけ掘り下げるほうが、結果としてコードレビューでの往復も減りました。
ケース2: 探索的リファクタリング
探索的リファクタリングは、最初から正解の変更範囲が見えていない作業です。
重複しているユーティリティをまとめたい、責務が混ざったサービス層を分離したい、テストが読みにくいので構造を揃えたい、といった仕事では、小さく切って仮説検証を回す必要があります。
この種類の作業も、基本線はComposerです。
ここで効くのは、安全に小刻みで進められることです。
たとえば、まず呼び出し箇所の棚卸しをさせ、その結果を見て置換方針を決め、次に1モジュールだけ差し替え、テスト結果を見て横展開する、という順番です。
Composerはこうした段階的な往復と相性がいいので、探索しながら形を整える仕事に向きます。
一方で、変更範囲が広く、複数の仮説を同時に試したい場面では、1本の対話に全部を詰め込まないほうが安定します。
並列エージェントを前提にした運用が視野に入るので、責務ごとに分けて進める発想が活きます。
たとえば、データ層の整理、UI側の呼び出し修正、テスト更新を別々に切り、必要ならworktreeで分離して比較する流れです。
大きなリファクタリングほど「一つの賢い対話」より「汚さない文脈を複数持つ」ほうが事故が減ります。
ケース3: 定期レビュー
依存パッケージの更新確認、脆弱性の洗い出し、テストフレークの監視のように、毎回ほぼ同じ観点で点検する仕事はAutomationsに寄せると収まりがよくなります。
ここでは、実装の途中で設計判断を増やすより、決まったタイミングで拾い漏れなく回すことに価値があります。
夜間や朝方に走らせて、結果だけを人間レビューに集約する形です。
Cursor Docs: Automationsで説明されている通り、Automationsはスケジュール起動の前提を持っています。
だから、依存関係の更新候補、脆弱性アラート、失敗しがちなテストの傾向を定時で集めて、朝には「見るべきものが整理された状態」にしておけます。
私は朝会前に夜間のPRを自動でふるいにかける運用を入れてから、起きて最初に通知を全部なめる時間が減りました。
人が朝からやるのは全件確認ではなく、機械が集めた論点の採否判断だけで済みます。
このケースでComposerを使う場面があるとすれば、点検結果から実際の修正に入る瞬間です。
定期レビューの本体はAutomations、そこから出てきた要修正項目の実装はComposerという受け渡しにすると、役割が混線しません。
ケース4: PR後の後処理

PRがマージされたあとに発生するラベル付与、CHANGELOGの草案作成、レビューチェックリストの記録といった後処理は、Automationsの典型例です。
これらは価値のある仕事ですが、毎回同じ条件分岐を人手でなぞる時間は積み上がりやすく、しかも抜け漏れが起きると後から地味に効いてきます。
Cursor Automations 公式ブログで紹介されているように、AutomationsはGitHubのPRイベントを起点に動かせます。
マージ後に差分を読み、変更種別からラベル候補を付け、コミット内容からCHANGELOGの叩き台を作り、定型チェックの結果を残す、という流れは自動化に向いています。
ここで人がやるべきなのは文面の最終判断や公開粒度の調整であって、素材集めではありません。
実務では、この後処理を手作業で残しておくと、レビューが終わった瞬間に気が抜けて後回しになりがちです。
イベントにフックして自動で回しておくと、レビューの熱量が残っているうちに必要な情報が揃います。
ComposerでPR本文や変更の背景を整えたあと、その後ろ側の事務処理をAutomationsに渡すイメージです。
ケース5: 障害一次調査
PagerDutyが発火した直後の一次調査は、最初の数分で「何を見て、どこまで切り分けるか」が決まる仕事です。
この初動は人間だけで抱えると負担が偏りますが、だからといって最初から自律修正まで任せるより、調査テンプレートをAutomationsに回させて人間の判断材料を先に作るほうが運用に乗ります。
たとえば、発火したサービス名に応じてログ、直近デプロイ、関連PR、監視ダッシュボード、既知インシデントの類似事例を集め、現時点の要約を返すところまでをAutomationsに持たせます。
その要約を見て、人間が影響範囲と優先度を判断し、修正タスクとしてIDE側に持ち込む段階でComposerへ渡す流れです。
一次調査はAutomations、修正の具体化はComposerという分業です。
この運用は夜間帯で効きました。
障害一次調査の初動テンプレを先に作っておくと、通知が鳴った瞬間に「まず何を開くか」を思い出す負荷が消えます。
人間は空の画面から調べ始めるのではなく、集められた材料を見て判断から入れます。
夜中に欲しいのは万能な自動復旧ではなく、判断に必要な最初の地図だと感じています。
💡 Tip
迷ったときは、「途中で設計判断が増えるならComposer、起動条件と手順が先に決まるならAutomations」で切ると、日々の作業を分類しやすくなります。
Composer と Automations の連携パターン
パターンA: Composerで設計/実装→Automationsで監視・再実行
この連携で中核になるのは、Composerを対話しながら実装を前に進めるエージェントとして置くことです。
日中はIDEの中で仕様の曖昧さを詰め、必要なテスト、検査スクリプト、Lintルール、運用用コマンドまで一緒に作る。
そこまでをComposerで終えたら、その成果物を夜間やイベント起点のAutomationsに載せ替えて、監視と再実行のレールに移します。
実装フェーズでは人間が近くにいたほうが判断が速く、運用フェーズではクラウド側で黙って回り続けるほうが漏れません。
この役割分担がきれいにはまります。
理想条件(1ラウンドを30秒と仮定した場合)の単純計算では、理論上は1時間に最大約120ラウンドとなります。
ただしこれはあくまで仮定に基づく理論値です。
実運用ではビルド・テスト・レビューの待ち時間や確認作業が入るため回転数は低くなり得ます。
この記事では「30秒/ラウンドを仮定した計算例」であることを明示しています。
私がよくやるのは、Composerでまず検知ロジックそのものを作り、テストで意図を固定してから、Automationsにそのスクリプトを定期実行させる流れです。
たとえば命名規約の逸脱や古いAPIの残存を見つけるチェックを日中に組み立てておくと、夜間ジョブでは同じ観点を再利用できます。
朝には「どのファイルで、何が、どの規約から外れたか」がまとまって返るので、人間はゼロから探す必要がありません。
Automationsの実行ログとメモリにその日の検知結果を残しておけば、次回Composerに修正方針を渡すときも、前回どこで詰まったかを前提に会話を始められます。
ここでログが単なる記録ではなく、次の実装のための橋になります。
パターンB: Automationsで検知→修正タスクを生成して人に渡す

💡 Tip
検知の出口は通知よりタスク化のほうが回ります。人間が受け取る単位を、警告一覧ではなく「判断できる材料が揃った修正候補」に寄せると、滞留が減ります。
パターンC: Plan/Build分担と並列エージェントの編成
大きめの機能追加や横断リファクタリングでは、PlanとBuildを分けると精度が安定します。
ひとつのエージェントに仕様整理から実装まで抱え込ませるより、最初の1エージェントで仕様、制約、タスク分割、完了条件を作り、その後にComposerへBuildを渡す形です。
設計ドキュメントは長くしすぎず、実装単位に切った短い計画にしたほうが回ります。
60〜150行くらいの粒度、あるいはもっと短い断片で持たせると、各タスクの意図がぼやけません。
ここでComposerの強みが出るのは、Build側での反復実装です。
大規模コードベースでの反復実装では、ひとつの変更が別の層に波及するので、仕様確認、関連箇所の探索、実装、テスト更新を何度も往復します。
Composerはセマンティック検索とコードベース理解を前提に、複数ファイルへまたがる変更を会話の中で進められます。
実務でもコーディングの6〜7割ほどをComposerに委ねるという感覚は珍しくなく、私もBuildフェーズではその比率に近い運用になることがあります。
人間は設計の境界線と受け入れ条件を握り、Composerは変更を前へ押し出す役に徹する。
そうすると、対話の密度が上がります。
並列編成もこの分担と相性がいいです。執筆時点での公式Docsを確認してから運用目安にすることをおすすめします。現場では「数」以上に編成の質が欠かせません。
パターンD: コンテキスト分離(worktree/リモート)とガード
並列で回すときに避けたいのは、エージェント同士が同じ文脈を汚し合うことです。
そこで効くのがworktreeやリモート実行によるコンテキスト分離です。
Composerは対話的に速く回る一方、ひとつの会話に複数の論点を積みすぎると、意図しない修正が混ざりやすくなります。
機能ごと、責務ごと、検証ごとに作業面を分けると、「何を変えてよくて、何を触らないか」が保たれます。
前のセクションで触れた通り、大きな変更ほど単独の万能対話より、汚れていない文脈を複数持つ運用のほうが事故が減ります。
私は、レビュー、修正、検証をそれぞれ別セルに分けることがあります。
ひとつのworktreeではComposerが実装を進め、別のworktreeでは検証用エージェントがテスト失敗の切り分けだけを見る。
さらにクラウド側のAutomationsが夜間に同じチェックを再実行して、差分の逸脱を拾う。
この配置だと、昼に触ったローカルの文脈と、夜に回る自動化の文脈がぶつかりません。
リモート側では定型の確認だけを走らせ、ローカル側では曖昧な仕様を会話で詰める。
役割の境界がそのままガードになります。
ガードレールは、権限や対象範囲を狭めるだけでは足りず、次回へ引き継ぐ情報の形も整えておく必要があります。
Automationsのメモリや実行ログに、どの検知がノイズだったか、どの修正案が採用されたかを残しておくと、次にComposerへ渡すプロンプトの質が上がります。
たとえば「前回はログ整形の差分が多すぎたので、今回はビジネスロジック変更を優先する」といった条件を、会話の最初から埋め込めます。
単発の自動化で終わらず、ログが次の設計材料に変わると、連携は一段深くなります。
Composerを実装の前線、Automationsを観測と継続実行の背面に置き、その間をメモリとログでつなぐ構図が、いちばん崩れにくい運用でした。
実践シナリオ 3例

シナリオ1: PRレビュー自動化
Automationsが最もはまりやすい場面のひとつが、GitHub PRを起点にした一次レビューです。
流れとしては、PR作成や更新をトリガーにクラウド側のCloud Agentを走らせ、変更範囲の要約、関連ファイルの把握、Lintやテスト結果の集約、リスク観点の整理までを先に済ませます。
GitHub PRやSlack、Webhookを起点にCloud Agentを自動実行できる構成が示されていて、まさにこの種の後工程を外に出す設計と噛み合います。
実務では、単に「差分を要約する」だけでは足りません。
レビュー担当が知りたいのは、どこを変えたかより、何が壊れうるかです。
そこで自動レビューの出力は、変更ファイル一覧の圧縮だけでなく、API契約の変更有無、権限制御への影響、例外処理の抜け、ロールバック時の注意点といった観点ごとのチェックリストに寄せると効きます。
通知先をSlackにしておけば、PRリンク、要約、失敗テスト、懸念点がひとまとまりで届くので、レビュアーはコードを読む前に論点を持てます。
私がこの運用を入れてよかったと感じたのは、朝会前に自動レビュー要約が並ぶ状態を作れたことです。
出社して最初にPR一覧を開いた時点で、差分の骨格とテストの顔つきが見えているので、優先順位づけが先に終わります。
人間はその場でマージ可否を判断するのではなく、まず「見る価値があるPR」を選び、そのあと承認に進む。
承認だけは人間に残す形にすると、速度と責任分界の両方が保てます。
ここでComposerの役割も消えません。
自動レビューで「この分岐のnull処理が怪しい」「テスト観点が足りない」と拾えたら、その修正自体はComposerに戻して対話的に詰めるほうが早い場面が多いからです。
Cursor 2.0 と Composer のご紹介で触れられている通り、Composerは低レイテンシの反復に向いているので、レビュー前の下ごしらえをAutomations、差し戻し後の修正をComposerという分担が自然に成立します。
シナリオ2: Linear issue 起点の定型実装
Linearの特定ラベル付きissueを起点にして、定型実装の初手を自動化する運用も効果が出やすいのが利点です。
たとえば「CRUD追加」「管理画面項目追加」「設定値の配線」のように、毎回やることが似ているタスクなら、issue発行と同時に雛形ブランチを切り、必要ファイルをスキャフォールドし、初期テストとドキュメントの叩き台を生成し、そのままドラフトPRまで作る流れにできます。
Cursor Docs: Automationsで示されているイベント起点のCloud Agent実行と、Linearトリガー対応の組み合わせをそのまま実務に落とした形です。
このパターンの肝は、実装そのものを全部任せることではなく、人間が毎回ゼロから始めなくて済む状態を作ることにあります。
issue本文から対象ドメイン、必要な層、命名規則、最低限の受け入れ条件を拾い、リポジトリの慣習に沿ったファイル群を先に置く。
そこまで整っていれば、担当者は空のエディタを前に悩まずに済みます。
特に社内向け機能やバックオフィス周辺の実装では、独創性より整合性が価値になるので、この下敷きが効きます。
現場感でいうと、Linearの定型実装はドラフトPRまで自動化したことで、レビュー観点の抜けが減りました。
人手で着手すると、実装は終わっていてもテスト名が曖昧だったり、変更理由がPR本文に残っていなかったりします。
自動で叩き台が出る形にしておくと、少なくともレビューの入口に必要な材料は揃います。
そのうえで担当者が仕様の細部や例外処理を追記して完成させるほうが、品質のばらつきが小さくなります。
ここでも、後半の詰めはComposerが向いています。
ZennのCursor Composer 実務実践編でも、一発で完成形を狙うより、抽象度を調整しながら反復する使い方が実務では回ると述べられています。
雛形生成、初期テスト、ドラフトPR作成まではAutomationsに受け持たせ、その先の業務ルールの埋め込みや命名の調整、境界条件の詰めはComposerで対話しながら進める。
この接続だと、定型と非定型の境目がきれいに分かれます。
シナリオ3: PagerDuty 一次調査

障害対応では、PagerDutyのインシデント発火をトリガーにして一次調査を自動化しておくと、最初の数分で集めるべき材料を取りこぼしません。
AutomationsはPagerDutyを含むイベント起点に対応しているので、発報直後にログ、Metrics、最近のデプロイノート、関連issue、直前の変更PRといった情報をMCP経由でまとめ、暫定的な原因仮説と復旧手順の候補まで生成し、Slackへ投げる構成が組めます。
この手の自動化で価値が出るのは、原因を断定することではなく、SREが判断する前提情報をそろえることです。
たとえばAPIエラー率の跳ね方、特定リージョンへの偏り、直近デプロイとの時系列、依存サービスの異常有無を1枚にまとめておけば、担当者は監視画面を何枚も往復せずに済みます。
復旧候補も、「直前デプロイのロールバック」「フラグの無効化」「ワーカー再起動」のように順序付きで出しておくと、Slack上の初動会話が短くなります。
私はこの種の運用を入れてから、夜間の初動でまず誰かが監視ツールを開いて状況把握から始める時間が減りました。
通知が来た瞬間に、障害の症状、怪しい変更、当面の打ち手候補が一度に見えるので、担当者は「何を見ればいいか」を決めるところから始めなくて済みます。
判断はSREが持ち、実行するかどうかも人間が決める。
その前段の情報集約だけをAutomationsに背負わせる形がいちばん安定しました。
この場面でもComposerは補助線になります。
一次調査で「このデプロイに含まれる設定変更が怪しい」と当たりがついたら、関連コードの探索や暫定修正パッチの作成はComposerに渡したほうが速いことが多いからです。
調査の入口をAutomations、修正案の叩き台をComposer、実行判断をSREという並びにすると、障害対応の流れが役割ごとに切り分けられます。
⚠️ Warning
具体的なUI手順名はDocs確認の範囲に留め、捏造しない
ここで挙げた3つのシナリオは、GitHub PR、Linear、PagerDuty、S今回の範囲で確実に言えるのは、Automationsがスケジュールまたはイベントに応じてCloud Agentを自動実行し、GitHub PRやSlack、Linear、PagerDuty、Webhookを起点に使えることまでです。
UI上の細かな手順名を記事側で補ってしまうと、読者が実画面と照合したときにずれます。
運用設計の粒度として押さえるべきなのは、どのイベントで起動し、何を集め、どこまで自動で進め、どこで人間承認に戻すかです。
具体的なボタン操作より、この境界設計のほうが実務では効きます。
今回の3例もその前提で見れば、実装の前線はComposer、定型の起動と集約はAutomations、承認と実行責任は人間、という役割分担として読むのがいちばん腹落ちします。
設計時の注意点
人間レビューと承認ゲートの設計
ComposerとAutomationsを併用すると、実装の着手から下処理までの速度は一気に上がります。
ただ、その速さをそのまま本番反映の速さに変えると、事故の入口にもなります。
設計段階で先に決めておきたいのは、どこで人が見るのかではなく、どの状態になったら必ず人が止めるのかです。
レビューは親切な確認作業ではなく、機械が前に進みすぎないための制動装置として置くほうが運用が安定します。
承認ゲートを入れる位置は、少なくともドラフトPRの作成後、リリース可否の判断前、重大変更を含むときの3か所に分けて考えると整理しやすくなります。
たとえばAutomationsがPRの要約、差分ラベリング、テスト観点の抽出まで進めるのは有効ですが、マージ判断だけは人に残す。
リリース前は、影響範囲の説明とロールバック可能性を人が確認する。
さらに認証、課金、権限、データ削除のような変更では、通常フローから外して自動処理を止める停止条件を先に書いておくと、例外時に迷いません。
私は一度、PR本文もテスト要約も整っていた変更が、見た目には問題なく流れそうになった場面で、自動マージを禁止して人のApproveを必須にしていた運用に助けられました。
差分自体は小さかったのですが、レビュー担当が「この設定値変更は社内向け環境だけでなく本番設定にも波及する」と気づき、その場で止まりました。
自動化の観点では通せる変更でも、運用文脈まで踏まえた判断はまだ人の役目です。
速度を出すほど、このゲートの意味はむしろ増します。
トリガー/例外/再実行ポリシー

Automationsの設計で先に詰めるべきなのは、何を自動化するかより、何で起動して、失敗したらどう扱うかです。
スケジュールやイベントでCloud Agentを自動実行できるので、起点は柔軟に作れます。
そのぶん、雑に置いたトリガーは誤爆、重複実行、通知スパムを生みます。
PR更新のたびに同じレビュー要約を連投する、同じ障害で調査ジョブが何本も走る、といった状態は典型です。
この手の事故を避けるには、イベント条件を業務単位で絞るのが基本です。
たとえば「PRが作られたら実行」だけではなく、「ドラフト化された直後は走らせない」「特定ラベルが付いたら走る」「同一PRでは前回実行が終わるまで次を受け付けない」といった条件まで含めて設計します。
通知先も同様で、毎回Slackへ全文を投げるのではなく、更新差分だけを出す、要約だけを出す、重大な失敗時だけメンションを付けるといった抑制線が必要です。
例外時の扱いも、正常系と同じくらい明文化しておくべきです。
外部API失敗、タイムアウト、権限不足、依存サービス不達は、実務ではむしろ頻出です。
ここで無限再試行にすると、失敗が増幅して別の障害になります。
再実行ポリシーは、どの失敗なら自動で再試行し、どの失敗なら即座に人へ戻すかを分けておくと崩れません。
ネットワーク断や一時的なAPI不調は再試行対象、認証エラーや想定外の大差分は停止して通知、という線引きです。
再実行時に同じ副作用を二重に起こさないよう、コメント投稿やラベル付けには冪等性の発想も入れておく必要があります。
💡 Tip
トリガーは「起動条件」、例外設計は「止まり方」、再実行ポリシーは「やり直し方」と分けて書くと、ワークフローの責任境界が崩れません。
権限とガードレール
自動化の事故は、モデルの推論ミスだけでなく、触れてよい範囲が広すぎることから起きます。
だからガードレールは抽象論ではなく、書き込み先を狭める設定として置くのが筋です。
まず基本になるのは、書き込み系の操作を最小限に絞ることです。
コメント投稿、ラベル更新、ドラフトPR作成までは許可しても、保護ブランチへの直接反映や本番環境への変更適用までは渡さない。
これだけでも、失敗したときの被害半径は大きく変わります。
実装系の自動化では、成果物の着地先をドラフトPRに固定しておくと扱いやすくなります。
Automationsがコードを触るとしても、いきなり完成扱いで出すのではなく、差分の説明、前提、未解決点を添えた叩き台として出す。
そのうえで保護ブランチを必須にし、人のレビューなしでは進まない構造にしておけば、機械の速度を活かしつつ統制も保てます。
ブランチ保護とApprove必須は、運用ルールというよりシステム側の柵として置くほうが効果的です。
本番投入前のサンドボックス検証も、地味ですが効きます。
レビュー用コメント生成やPR要約のような読み取り中心の処理でも、実運用の連携先と同じ権限をいきなり与える必要はありません。
まずは限定データ、検証用リポジトリ、隔離ブランチで動かし、どの入力でどの出力になるかを観察する。
Composer側でも同じで、修正案の作成は速くても、反映先を分けたworktreeや別ブランチで受けるだけで事故率は下がります。
速い道具ほど、走らせるレーンを狭く作ったほうが扱いやすくなります。
コンテキスト汚染を避けるタスク分割と設計文書の短文化

エージェント運用で見落とされがちなのが、1つのフローに役割を詰め込みすぎることです。
調査、実装、レビュー、要約、通知までを1体のエージェントに背負わせると、途中で参照すべき文脈が混ざり、出力の焦点がぼやけます。
私はComposerでもAutomationsでも、役割を固定したほうが結果が安定しました。
実装担当はコード変更に集中させ、レビュー担当は差分要約と懸念点抽出だけに寄せる。
障害時の一次調査はログ収集と仮説整理までに留め、修正案の生成は別系統に渡す。
その切り分けが、コンテキスト汚染を防ぐいちばん現実的な方法です。
技術的な分離も有効です。
worktreeの考え方は、並列作業時の衝突回避と相性がいいです。
タスクごとに別ブランチ、必要なら別worktreeに分けておけば、Aの調査中にBの修正意図が混ざるといった混線を防げます。
並列数そのものより、各エージェントに何を持たせないかの設計が効きます。
役割が曖昧なまま数だけ増やすと、速くなる前に散らかります。
設計文書も長ければ親切とは限りません。
実務では、目的、入出力、許可操作、停止条件、承認ポイントだけが明瞭に書かれた短い文書のほうが回ります。
目安としては60〜150行程度に収めると、読む側も修正する側も文脈を保ちやすいのが利点です。
これを超えて運用背景や補足ルールを盛り込み始めると、肝心の制約が埋もれます。
詳細仕様は別文書に逃がし、エージェントに渡す設計書は短く保つ。
この発想は、モデルのためというより、人間が保守できる状態を作るために効きます。
“自動化しない”の判断基準
自動化の成熟度は、任せられる範囲の広さだけでは測れません。
どこから先は人が持つと決めているかが明確なチームのほうが、実際には安定します。
向いていないのは、仕様が曖昧で、正解の評価関数も定まっていない業務です。
たとえば「この設計レビューは筋がよいか」「この仕様変更は顧客体験として受け入れられるか」といった問いは、差分の正誤だけでは裁けません。
こういうレビューはComposerで論点整理の補助を受けることはあっても、最終判断は人が握るべきです。
顧客影響が極端に大きい本番データ操作も、人主導を維持したほうが安全です。
アカウント削除、課金訂正、権限剥奪、大量のデータ更新のような処理は、たとえ手順自体が定型でも、1回の誤りで回収不能になりやすい領域です。
ここは自動化するなら準備までに留めるのが現実的です。
対象候補の抽出、影響範囲の算出、実行計画のドラフト生成までは自動でよくても、実行ボタンを押す責任は人に残す。
その線引きがあるだけで、速度と統制の両方を取りにいけます。
Composerは短い反復を高速で回せるので、探索や叩き台作りでは強い道具ですし、Automationsは定型の後工程を外出しするのに向いています。
ただ、速く回せることと、放っておいてよいことは同義ではありません。
評価軸が曖昧な仕事、失敗コストが跳ね上がる仕事、説明責任を人が負うべき仕事は、自動化の外側に残したほうが全体の運用が静かになります。
そこを無理に機械へ寄せない設計が、結果として長く続く仕組みになります。
最初の1本をどう作るか
最初の一歩では、広い連携図を描くより、1つの業務を小さく切り出して回すほうが定着します。
私がチームで進めたときも、最初はPRのタイトル規約チェックだけを自動化し、その運用が受け入れられてからCHANGELOGの下書きへ広げたことで、合意形成が止まりませんでした。
実装を進める役はComposer、監視や後処理の自動実行はAutomationsと分けて考えると、最初の1本がぶれにくくなります。
Step1: タスク棚卸しテンプレ

最初にやることは、今の自分の仕事を「何となく忙しい」のまま眺めることではありません。
単発、定期、イベント起点の3種類に分けて書き出し、どれが自動化候補として素直かを見極めます。
Composerは曖昧な要求を詰めながら手を動かす場面に向き、Automationsは決まった条件で繰り返す処理に向くので、この分類を先にしておくと役割分担が自然に決まります。
棚卸しは、以下の観点だけで十分です。ここで長い設計書は要りません。1ページに収まる粒度で、実際に今週やった仕事を並べるほうが判断できます。
- 単発タスク: あるIssueの実装、局所的なリファクタリング、調査メモの作成
- 定期タスク: 毎週の依存更新確認、定例レポート下書き、夜間のチェック処理
- イベント起点タスク: PR作成時のラベル付け、障害通知時の一次整理、特定コメントを受けたときの反応
候補を見つけるチェックリストも、まずはこれだけで足ります。
- 入力条件が決まっている
- 出力先が1つに定まる
- 人が毎回ほぼ同じ手順でやっている
- 失敗しても被害が限定的で戻せる
- 成功か失敗かを言葉で判定できる
この5つに多く当てはまるものほど、Automationsに載せやすい題材です。
逆に、仕様調整を含む実装や、途中で人の判断が頻繁に入る作業は、まずComposerで叩き台を作るほうが筋がいいです。
Step2: 最小構成
棚卸しの次は、候補を1つだけ選ぶ段階です。
ここでPRレビュー全体やSlack通知の網羅運用から始めると、設計も合意も一気に重くなります。
最初の1本として向いているのは、PRタイトル規約のチェック、依存更新の確認、CHANGELOG候補の下書きのように、影響範囲が狭く、出力を見れば良し悪しを判断しやすいものです。
構成も最小に絞ります。
トリガーは1つ、出力先も1つで十分です。
たとえば「PRが作成されたら、Slackに規約違反の有無を通知する」だけでも、立派な導入になります。
WebhookやSlack連携を広げる前に対象業務を絞ると、失敗したときにどこを直せばいいかが見えます。
この段階で先に決めるべきなのが、成功判定です。たとえば次のように、曖昧さの少ない形で置きます。
- PRタイトル規約チェックなら、違反時だけ所定の文面で通知される
- 依存更新チェックなら、更新候補があるときだけ一覧が出る
- CHANGELOG下書きなら、差分の要点が所定の見出しに沿って並ぶ
成功判定を定義せずに動かすと、出力が少しでも動けば成功なのか、運用に乗った状態を成功と呼ぶのかが曖昧になります。
最初の1本では、精度の議論より「何をもって通ったとみなすか」を先に固定したほうが、改善の会話が短く済みます。
💡 Tip
最初の自動化は、コードを書かせる処理より、通知・要約・チェックのような後処理から入ると、運用の癖を観察しやすくなります。
Step3: 検証→改善
動かし始めたら、いきなり対象を増やさず、少数の実行結果を見て調整する流れに入ります。
Composerの対話は多くが30秒未満で完了すると案内されており、短い試行を細かく回せるのが強みです。
だから最初の修正も、大きな再設計より「通知文を短くする」「判定条件を1つ減らす」「除外ケースを足す」といった小さな改善の連続で進めたほうが、現場の感覚に合います。
ここで見るべきなのは、賢そうに見えるかではなく、定義した成功判定に何回通るかです。
たとえばPRタイトル規約チェックなら、規約どおりのPRで余計な通知が出ないか、違反時に見落としなく拾えるかを確認します。
CHANGELOG下書きなら、見出しの形が揃っているか、差分の要点が抜けていないかを見る。
この観点があると、改善も「何となくもっと良くする」ではなく、外れた点を1つずつ詰める作業に変わります。
実装側の見直しが必要ならComposerに戻して、プロンプトや処理内容を詰める。
定期実行やイベント起点の動かし方を直すならAutomationsで調整する。
この往復を分けておくと、どこで品質が落ちたのかを追えます。
実務でも、コーディングの多くをComposerに任せつつ、人が抽象度を調整しながら反復する運用がはまるのは、この切り分けが効くからです。
Step4: 連携拡張

最小構成が安定してから、連携先を増やします。
順番としては、Slack通知が回るようになったあとでWebhook、さらに必要に応じてLinearやGitHub PR起点の流れへ広げるのが扱いやすいのが利点です。
先に配線を増やすと、どの連携で出力が崩れたのか切り分けに時間を取られます。
対象業務が1つのままなら、拡張しても判断軸はぶれません。
精度面では、Automationsがメモリにアクセスできる特性を活かし、過去の実行結果を踏まえて改善を回す発想が効きます。
通知文の粒度、除外条件、よくある例外を蓄積していくと、毎回同じ調整を人が繰り返さずに済みます。
ここでも役割は崩さず、実装や複数ファイルの修正はComposer、監視や後処理の継続実行はAutomationsに寄せると、責務が混ざりません。
UI上の細かな名称や設定項目は更新されることがあるので、その場の記憶で決め打ちせず、CursorのDocsで都度確認しながら進めるのが確実です。
最初の1本で目指すのは、全部つながった壮大な仕組みではありません。
ひとつのイベントに対して、ひとつの期待どおりの出力が返る状態を作ることです。
そこまで持っていければ、次の1本は前よりずっと軽く始められます。
AIビルダーの編集チームです。AI開発ツールの最新情報と使い方を発信しています。
関連記事
バイブコーディングとは?始め方とおすすめツール3選
バイブコーディングとは?始め方とおすすめツール3選
バイブコーディングは、2025年2月にAndrej Karpathyが提唱した、自然言語でAIに意図を伝えながらコードを書かせる開発スタイルです。人が「こう動いてほしい」と言葉にし、AIがコードを生成し、人はそれを確かめて直していく。この流れなら、プログラミング未経験でも小さなアプリから形にできるでしょう。
Cursor Agent Modeの使い方|Ask/Plan/Agentの違いと使い分け
Cursor Agent Modeの使い方|Ask/Plan/Agentの違いと使い分け
Cursorのチャットは、Ask・Plan・Agentの3モードを使い分ける設計で、デフォルトはAgentです。Askはコードを変更せずに読み取りだけを行い、Planは調査結果をもとに計画書を作るだけ、Agentは複数ファイルの編集やコマンド実行まで進めます。
MCP自動化パターン10選|導入順と最小手順
MCP自動化パターン10選|導入順と最小手順
筆者の試用では、Jira と Notion を横断して要約する流れを組むと、毎朝の状況把握にかかる時間が短く感じられ、概ね2〜3分程度で済むことがありました。これはあくまで筆者の環境での体験値であり、環境や設定によって大きく変わります。一般化して示す場合は、社内PoCや計測ログなどの出典を併記してください。
Cursor Automationsの始め方と運用設計
Cursor Automationsの始め方と運用設計
Cursor Automationsは、SlackやGitHubなどのイベント、あるいはスケジュールを起点にCloud Agentsを自動実行する機能です。