Cursor 活用Tips 10選|開発効率を上げるコツ
Cursor 活用Tips 10選|開発効率を上げるコツ
Cursorは VS Code ベースの開発環境に AI 機能を深く組み込みたいエンジニアに向いた選択肢です。Tab補完、Chat・Agent、Rules、MCP の観点で整理すると、単なる補完ツール以上に実務で使える場面が見えやすくなります。
Cursorは VS Code ベースの開発環境に AI 機能を深く組み込みたいエンジニアに向いた選択肢です。
Tab補完、Chat・Agent、Rules、MCP の観点で整理すると、単なる補完ツール以上に実務で使える場面が見えやすくなります。
Cursorで開発効率が上がる理由
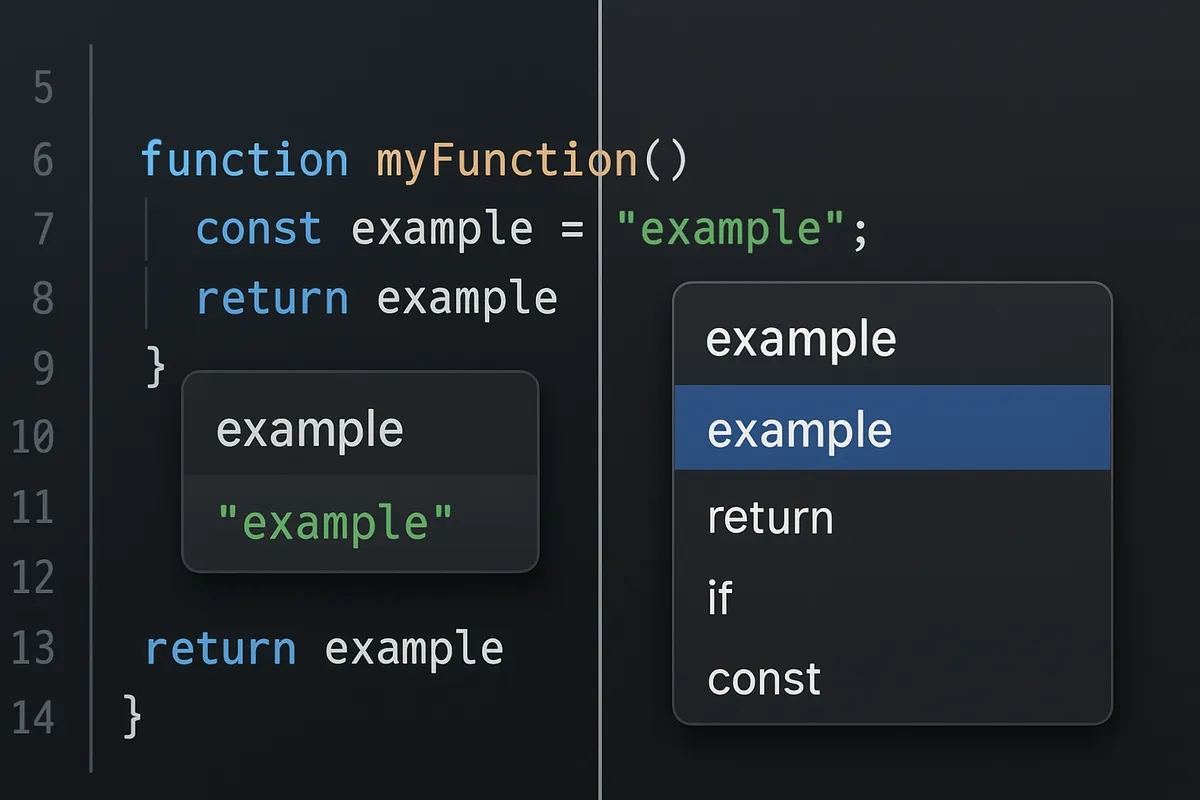
VS Codeベースの利点とAIファースト設計
Cursorが効率に直結しやすい理由のひとつは、単にAI機能を後付けしたエディタではなく、VS Codeベースの資産を引き継ぎながら、IDE全体をAI前提で組み直している点にあります。
普段使っているキーバインドや操作感が近いため、学習コストを払う前に手が止まりにくく、補完や対話機能をその日のうちに作業へ混ぜ込めます。
私も切り替え初日、いつものVS Codeのショートカットが多くそのまま通ったので、環境移行に時間を使うより先に、Tab補完とAgentを既存プロジェクトへ試せました。
この「乗り換えの摩擦が小さいのに、AIの入り方は深い」という設計が、導入直後の体感差を生みます。
コード補完、チャット、編集支援を一続きの体験として案内しています。
つまりCursorは、エディタ本体の外にAIがいるのではなく、書く・読む・直す・調べるの流れにAIが同居している構造です。
従来の「ブラウザでLLMに相談して、答えをIDEへ貼り戻す」往復が減るぶん、思考の分断も減ります。
もうひとつ見逃せないのが、既存の拡張やワークフローの蓄積を活かしやすいことです。
新しい道具を入れても、フォーマッタ、Lint、Git操作、言語拡張まで総入れ替えになると現場では止まりやすいのですが、Cursorはその壁が低い。
結果として、導入の目的が「新しいエディタを覚えること」ではなく、「補完や自律編集でどこまで工数を削れるか」の検証にすぐ移ります。
Quickstart | Cursor Docs
Go from install to your first useful change in Cursor. Sign in, ask Cursor to explain your codebase, make a small edit,
cursor.com4系統(Tab補完/Chat・Agent/Rules/MCP)の全体像
Cursorを単なるAI補完ツールとして捉えると、強みの半分も見えません。
実務では、Tab補完、Chat・Agent、Rules、MCPの4系統を分けて考えると役割が整理されます。
まずTab補完は、1行から数行単位の入力を速く進めるレイヤーです。
変数名の続き、似た条件分岐、定型的なハンドラ実装のように、「次に書く内容が局所的に読めている」場面で効きます。
ここはタイピング削減の効果がそのまま出やすく、短い反復作業を細かく刈り取る担当です。
一方のChatは、コードを見ながら相談し、関数単位やファイル単位で修正方針を詰めるための窓口です。
レビューコメントの意図を砕いたり、エラー原因の仮説を並べたり、既存実装に沿ったリファクタ案を比較したりと、「まず会話で方向を決めたい」場面に向きます。
そこから一段踏み込むのがAgentで、複数ファイルをまたぐ変更、関連箇所の探索、まとまった編集を進める役割を持ちます。
Agent Overviewや。
実務で触ると、この差ははっきりしていて、Chatは「相談相手」、Agentは「作業者」に近い立ち位置です。
Rulesで案内されている Project / Team / User 単位の Rules を設定すると、単発の賢さよりも継続運用での安定感が得られます。
公式ドキュメントを参照しつつ、プロジェクト固有の約束ごとを優先して登録してください。
MCPは、AIをエディタ内に閉じ込めず、外部ツールや社内基盤へつなぐ拡張判断材料になります。
MCPサーバーで説明されている通り、モデルや外部コンテキストとの接続面として機能し、API仕様、ドキュメント、内部ツールの情報を作業フローへ取り込みやすくします。
ここまで揃うと、Cursorは「補完が賢いエディタ」ではなく、入力支援、対話、継続指示、外部連携を同じ場所で扱う作業基盤として見えてきます。
Overview | Cursor Docs
Assistant for autonomous coding tasks, terminal commands, and code editing
cursor.comCursor vs GitHub Copilotの立ち位置
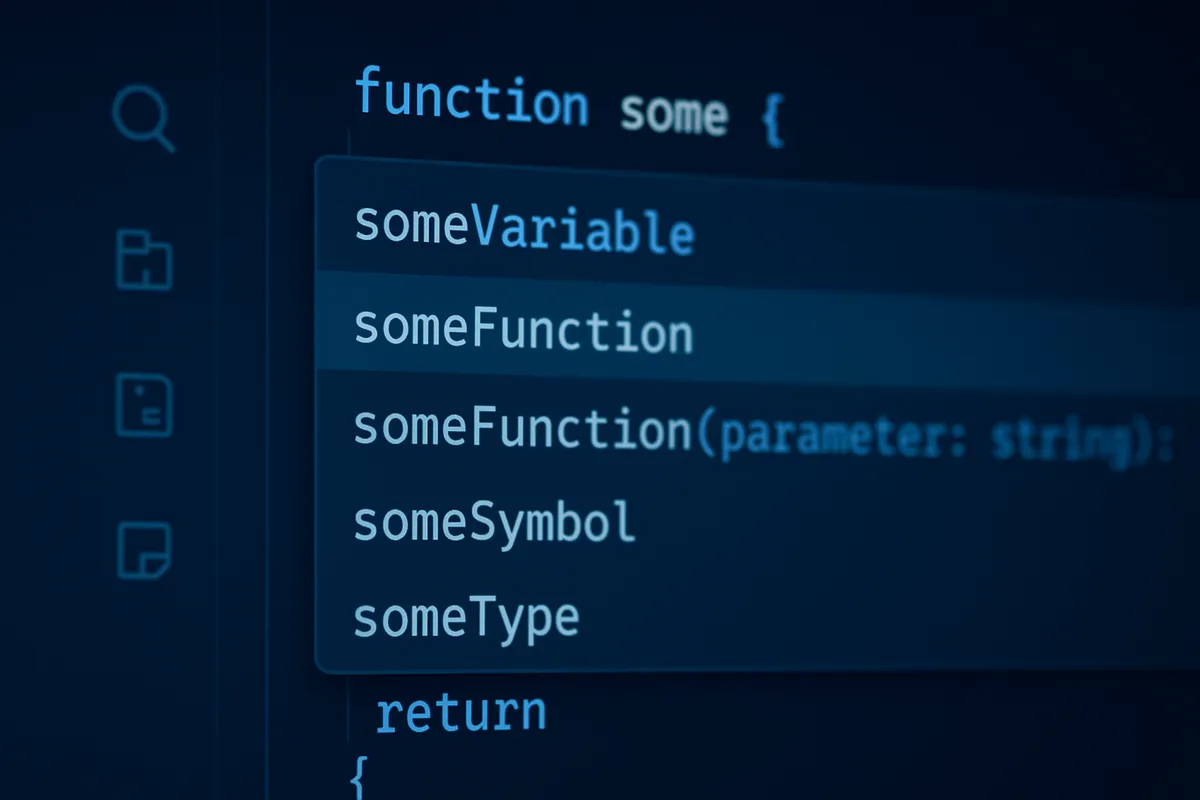
CursorとGitHub Copilotは競合として並べられがちですが、実際には設計思想が少し違います。
CursorはAIファーストIDEとして、エディタ全体の体験をAI中心に組み立てています。
補完だけでなく、Agent、Rules、MCPまで含めて「AIが開発フローの一部として常駐する」ことを前提にしています。
対してGitHub Copilotは、既存IDEへ拡張として入れやすい立ち位置が強みです。
ふだんのVS CodeやJetBrains環境を大きく変えず、補完や提案を足したい場面では入りやすい選択肢です。
この違いは、どちらが上かというより、どこまでAIに作業を持たせたいかで見たほうが腑に落ちます。
既存環境を崩さず導入し、まず補完中心で試すならGitHub Copilotは自然です。
対して、複数ファイル編集やコードベース全体を見た修正、継続ルールの定着、外部ツール連携まで視野に入るなら、Cursorのほうが一枚岩の体験になりやすい。
実際、補完だけなら差が見えにくい場面でも、設計変更や横断修正に入るとIDEとしての思想差が表に出ます。
価格感にも違いがあります。
Cursor 。
GitHub Copilot側は比較記事でより低い月額帯が言及されることがありますが、このセクションで注目したいのは金額差そのものより、何に課金しているのかです。
Cursorは「AIをIDEの主役に据えた運用基盤」へ払う感覚が近く、Copilotは「今のIDEへAI提案を追加する拡張」へ払う感覚が近い、という整理が実務では役立ちます。
実務で見える効果
Salesforce の一部組織で大規模な導入が行われ、同社の報告では2026年2月時点で約2万人規模かつ90%以上の開発者が Cursor を利用し、サイクルタイムやPR速度、コード品質の指標で二桁改善が見られたとされています。
ただし、これは Cursor 側の一次ソースによる報告であり、第三者による独立検証が公表されているわけではありません。
」と明示し、一般化は避けてください。
評価軸の整備という観点では、ここでは、実際のCursor利用由来のタスクをもとに、正しさ、コード品質、効率、対話挙動といった複数の軸でモデルや挙動を見ています。
AIコーディングの評価は「答えが出たか」だけでは足りず、修正の筋がよいか、無駄な往復が少ないか、対話が作業を前に進めるかまで含めて見る必要があります。
Cursorの効率向上は、単純な補完速度より、探索・編集・検証の往復回数をどれだけ減らせるかで捉えるほうが実態に近いです。
ℹ️ Note
Webやモバイル対応は2025年7月前後の情報で表現に揺れがあり、ネイティブアプリなのかWeb経由なのかで説明が分かれています。この点は現行仕様が変わりやすい領域として扱うのが無難です。
実務で触っていると、効率化の本体は「1回の提案がすごい」ことより、「同じ説明を何度も繰り返さずに済む」「関連ファイルを探す時間が減る」「小さな修正をまとめて前へ進められる」ことにあります。
Cursorはその積み重ねを、Tab補完、Agent、Rules、MCPの4層で支えているからこそ、単発のAI機能ではなく開発フロー全体の速度に効いてきます。

How we compare model quality in Cursor · Cursor
We use a hybrid online-offline eval process to keep our understanding of model quality aligned with what developers actu
cursor.com最初に押さえたい基本設定
インストールと初回サインイン

導入直後は、まずCursorそのものの入り方でつまずかないようにしておくと、その後の理解がスムーズです。
入手元はCursor公式サイトで、Macなら.dmg、Windowsなら.exeを使う流れになります。
初回起動では、VS Codeの設定や拡張機能を取り込むかどうかを尋ねられることがあります。
ここで既存のテーマ、ショートカット、設定に慣れているなら、取り込みを選ぶと編集操作の違和感が少なくなります。
逆に、Cursorをできるだけ素の状態で試したいなら、いったん取り込まずに始めるほうが、AI関連の挙動だけを切り分けて見られます。
筆者は最初に取り込みを選んだのですが、キーバインドの戸惑いが減ったぶん、早い段階でTab補完やChatの確認に入れました。
サインインは、起動後に表示されるアカウント導線から進めます。
ここでは「とりあえず使い始める」ことが先で、細かい最適化は後回しで構いません。
最初の目的は、プロジェクトを開いてAI機能が反応する状態まで持っていくことです。
CursorはVS Codeベースなので、フォルダを開く、ワークスペースを読み込む、拡張の雰囲気に慣れるといった基本動作は大きく変わりません。
そのため、エディタ移行そのものより、最初にどのプロジェクトを開くかのほうが体験差につながります。
新規サンプルよりも、見慣れた既存リポジトリを開くほうが、Cursorの強みが見えやすい場面が多いです。
Quickstartでコードベースを理解する
導入直後にいちばん効果を感じやすいのは、Cursor Quickstartの流れに沿って、既存リポジトリを開いたうえでコードベースの説明を求める使い方です。
最初から生成を頼むより、いまあるコードをどう理解しているかを見たほうが、Cursorの実務での使いどころがつかみやすくなります。
やることは難しくありません。
手元のプロジェクトを開いたら、ChatかAgentで「このコードベースの目的と主要モジュールを説明して」と聞くだけです。
ここでREADME、ディレクトリ構成、主要ファイルの役割を横断して要約してくれると、エディタ内での読解補助として頼れます。
筆者も最初の確認でこの聞き方を試したところ、どこがAPI層で、どこがUI層で、設定がどこに集まっているかを短時間で把握できました。
初見のリポジトリに入ったときの「まず何から読むか」という迷いが減るんですよね。
この段階では、長い指示を詰め込む必要はありません。
たとえば「このアプリの目的を3行で」「主要ディレクトリごとの責務を整理して」「変更時に影響が出そうな場所も挙げて」のように、観点を小さく分けると反応が安定します。
前のセクションでも触れた通り、CursorのAgentは小さな目標に分けたほうが扱いやすく、初回のQuickstartでもこの考え方がそのまま効きます。
コードベース理解の入り口としてQuickstartを使うと、その後の修正依頼も通しやすくなります。
いきなり「バグを直して」ではなく、「認証まわりの主要ファイルを挙げて」「この関数が呼ばれる経路を追って」と段階を踏めるからです。
導入直後の数分でこの流れを経験しておくと、Cursorを単なる補完ツールとして終わらせずに済みます。
Privacy Modeの有効化と確認
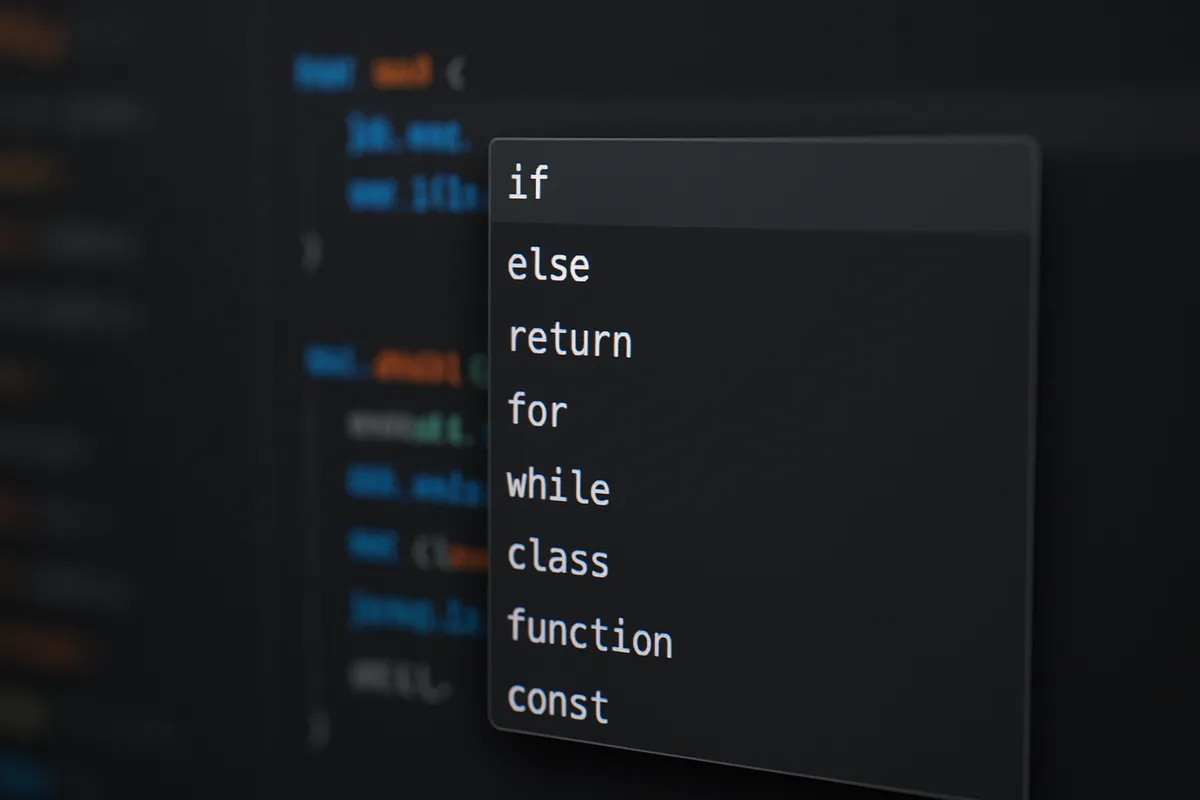
Privacy Modeは、Cursor 側の一部の保存や学習利用を抑える設定として案内されています(詳細は公式ドキュメントを参照してください)。
ただし通信そのものが消えるわけではなく、AI 応答を得るためのリクエスト処理は発生します。
したがって、どの情報を送るかは .cursorignore 等で明示的に制御する運用が欠かせません。
有効化は設定画面から進める流れで、アカウントやプライバシー関連の項目に入ると確認できます。
オンにした後は、単に切り替えて終わりにせず、次の.cursorignoreまで続けて触ると運用が安定します。
筆者もPrivacy Modeを有効にしたうえで、.envと機密ディレクトリを除外対象に足したところ、うっかり読ませたくない内容までAIに渡るのではという不安がだいぶ薄れました。
設定単体より、除外ルールと組み合わせたときに効いてくる感覚です。
.cursorignoreの基本と除外例
Privacy Modeを有効にしていても、プロジェクト内のどのファイルをAIの文脈に含めるかは別で考える必要があります。
その役目を持つのが.cursorignoreです。
考え方としては.gitignoreに近く、AIに参照させたくないファイルやディレクトリを明示的に外すための設定です。
最初に入れておきたい代表例は、環境変数や秘密情報を含むファイルです。
たとえば.env、鍵ファイル、認証情報を置いたディレクトリ、社内専用の設定フォルダ、顧客データのダンプなどは、早い段階で除外しておくほうが自然です。
加えて、巨大な生成物や依存ディレクトリまでAIの文脈に入ると、必要なファイルよりノイズが増えることがあります。
機密性だけでなく、文脈を絞って応答を安定させる意味でも除外は効きます。
例としては、次のような内容から始めると整理が進みます。
.env
.env.*
secrets/
credentials/
private/
internal/
*.pem
*.key
dist/
build/
node_modules/このファイルは、プロジェクトルートに置いて管理します。
実際に使ってみると、最初はセキュリティ目的で入れた除外設定が、そのままAIの回答精度にも効いてきます。
無関係な生成物や社内向け資料が混ざらないぶん、コードの要点を拾いやすくなるからです。
逆に、何も除外せずに広く読ませると、説明が散ったり、参照先が増えたりして、初回の理解フェーズでは扱いづらくなります。
💡 Tip
.cursorignoreは「隠したいもの」だけでなく、「読ませても意味が薄いもの」を外す設定として見ると運用しやすくなります。
日本語化の現状と補助的な設定
UIの日本語化については、導入時に気になる人が多い判断材料になります。
CursorはVS Codeベースのため、見た目や操作感は近いのですが、日本語UI対応の範囲は時期によって確認方法を分けて見たほうが混乱しません。
メニューや設定画面の名称まで日本語で揃っていることを前提に入るより、基本は英語UI、必要に応じて周辺設定で補うくらいの理解のほうが実態に合います。
実務上は、UIそのものよりも、AIとの対話を日本語で進められるかのほうが影響は大きいです。
ChatやAgentには日本語でそのまま依頼できますし、コード説明や修正方針の相談も日本語で十分通ります。
そのため、メニューの一部が英語でも、実際の作業はそこまで止まりません。
筆者もUI全体の翻訳状態を気にするより、プロンプトやRulesを日本語で整えたほうが、普段の開発には効きました。
補助的な設定としては、OS側の表示言語やVS Code由来の言語設定に寄せる方法があります。
初回にVS Code設定を取り込んでいる場合、テーマやフォントまわりと合わせて、作業時の違和感を減らせることがあります。
とはいえ、ここで無理に表示言語だけを追い込むより、Quickstart、Privacy Mode、.cursorignoreのような作業直結の設定を先に固めたほうが、導入直後は差が出ることが多いです。
料金プランの確認ポイント

料金面は、導入直後ほど先に全体像だけつかんでおくと混乱しません。
Cursorの料金は固定回数型の記事がまだ残っている一方で、現行ではクレジットベースの説明が中心です。
Cursor Pricingで確認できる代表的な起点はCursor Proの$20/月で、ここからモデル利用や使い方によって実感コストが変わってきます。
単純な月額だけでなく、日常運用を Auto 寄りで回すのか、高性能モデルを多用するのかによって消費感が変わります。
どの作業をどのモデルに割り当てるかを先に定めると、料金の見通しが立てやすくなります。
個人開発なら、Cursor Proの$20/月が作業時間に見合うかを考える軸が現実的です。
月に数時間でも調査、定型修正、読解の往復が減るなら、工数換算では十分に回収しやすい金額帯です。
チーム利用では、1人あたりの単価だけでなく、どこまでPrivacy運用やルール共有を揃えられるかも見えてきます。
外部ではBusiness相当として$40/ユーザー/月の事例も見られますが、ここは導入形態とあわせて整理する項目です。
この段階では、無料で触るか有料に進むかを急いで決めるより、Quickstartで既存コードの把握が進むか、Privacy設定と除外設定を違和感なく回せるか、Agentの使い方が自分のタスクに合うかを見たほうが判断材料になります。
料金は数字だけでなく、どの作業をCursorに任せる前提なのかとセットで読むと解像度が上がります。

Cursor · Pricing
Choose the plan that's right for you
www.cursor.com開発効率を上げるCursor活用Tips 10選
このセクションでは、機能を順番に並べるより、実務で手が止まりにくかった使い方に寄せて10個のTipsを整理します。
どれも単体で効きますが、実際には連携させると差が出ます。
私自身、TypeScriptの関数追加では、まずCursorのTab補完でダミー実装を置き、そのあとAgentに周辺呼び出しの更新を任せ、仕上げにテストを生成させる流れにすると、最初から大きな改修を一気に投げるより破綻が少なくなりました。
局所の入力支援、関連箇所の追従、品質確認を役割分担させると、AIの得意分野がきれいに分かれます。
Tip1: Tab補完は“省力化の第一手”として常用する
目的は、思考を止めずに定型入力を前倒しで片づけることです。
CursorのTab補完は、1行から数行の補完で最も効率が出ます。
関数シグネチャ、if文、型定義、ガード節、既存コードに沿った命名の続きなど、人間がゼロから打つと細かく時間を取られる部分を先に埋める役目です。
操作はシンプルで、エディタ上でコードを書き始め、表示された補完候補をその場で受け入れるだけです。
特別な画面へ移動するより、ふだんの編集の流れにそのまま載せるほうが効果が出ます。
UIから見ても、まずは通常のコード入力中に出てくるinline completionを拾う運用が中心になります。
効く場面は、既存の書き方が揃っているプロジェクトです。
たとえばTypeScriptで既存のservice層に1つ関数を足すとき、戻り値の型、例外処理、ログの位置、命名の癖が周囲と似ていれば、Tab補完だけでも骨格がほぼ出ます。
私も最初のダミー実装はTab補完に寄せることが多く、空の関数を置いてから本文を補っていくより、周辺コードに似た形を先に受け入れたほうが、その後の修正量が減りました。
注意点は、Tab補完を「賢い自動実装」と見すぎないことです。
局所文脈には強い一方で、設計変更や複数ファイルにまたがる整合までは面倒を見ません。
1ファイル内の勢いづけとして使い、影響範囲の調整はChatやAgentに渡す、という切り分けが安定します。
Tip2: ChatとAgentを使い分ける

目的は、相談と実行を混ぜないことです。
Chatは方針を詰める場、Agentは実際に編集を進める場として分けると、応答の質と差分確認の両方が整います。
『Agent Overview』でも、まとまった作業を任せる流れが整理されていますが、現場では「いきなり全部やらせない」ほうがむしろ速く進みます。
操作としては、まずChatで「どのファイルが関係しそうか」「変更方針は何通りあるか」を聞き、方向が固まってからAgentに編集を依頼します。
UI上でも、対話ペインで相談した内容を踏まえて、別の実行モードで作業させる流れを意識すると、ログが読みやすくなります。
キー操作を覚えるより、ペインを切り替えて役割を明確にしたほうが迷いません。
効く場面は、影響範囲が見えない修正です。
バグ調査でも、私は先に再現手順をChatへ渡して、関連箇所の探索候補を出させることがあります。
その段階で「入力検証」「キャッシュ」「非同期処理」など疑うポイントを並べさせてから、Agentに修正を任せると、いきなり自動編集を走らせるよりディフ確認が楽でした。
考える仕事と書き換える仕事を分離すると、レビューの負荷が下がります。
注意点は、Agentへの丸投げです。
「バグを直して」のような大きい依頼では、意図していないファイルまで触ることがあります。
Chatで方針を言語化してから渡すだけで、編集対象と期待する着地点がはっきりします。
Tip3: 依頼は小さく分割し、段階的に進める
目的は、AIの作業単位を人間が追える大きさに保つことです。
1回で完成形を求めるより、「型を定義する」「関数を追加する」「呼び出し元を更新する」「不要コードを消す」と分けたほうが失敗の場所が見えます。
依頼文に作業範囲を入れます。
たとえば「まず型定義だけ編集」「次にこの関数の呼び出し箇所だけ更新」「テストはそのあと」と順序を明示します。
Cursor小さく区切る進め方が軸になっています。
大きな依頼ほど、途中の前提がずれたときの修正コストが増えます。
効く場面は、リファクタリングや既存機能の拡張です。
前述のTypeScriptの関数追加も、一気に「新機能を実装して関連箇所とテストも全部更新」と頼むより、ダミー実装、呼び出し更新、テスト生成の3段階に分けたほうが安定しました。
途中の差分を見ながら軌道修正できるので、結果としてやり直しが少なくなります。
注意点は、細かく分けすぎて文脈が切れることです。
依頼を分割しても、「今どこまで終わったか」「次に何を触るか」は明示しておく必要があります。
小さくするのは作業範囲であって、目的まで小分けにして見失わないことが肝になります。

Cursor agent best practices
A comprehensive guide to working with coding agents, from starting with plans to managing context, customizing workflows
cursor.comTip4: テストを書かせて品質を担保する
目的は、AIが書いたコードをAI自身に検証させる土台を先に置くことです。
実装だけ生成させると、見た目は通っていても境界条件が抜けます。
ユニットテストや既存テストの追記をセットにすると、修正の妥当性が読みやすくなります。
操作としては、実装依頼の直後に「正常系・異常系・境界値を含むテストを追加」と続けるのが基本です。
UIからは、対象ファイルを開いた状態でチャットにテスト観点を指定し、必要ならAgentにテストファイル作成まで任せます。
単に「テストも書いて」ではなく、「何を担保したいか」を渡すほうが、期待したケースに寄ります。
効く場面は、型だけでは安心できないロジックです。
日付処理、権限判定、入力変換、エラーハンドリングは、コードを読んだだけでは抜けに気づきにくいので、テスト生成との相性がいい領域です。
私も、関数追加のあとにテストを作らせる順番へ固定してから、周辺呼び出しの更新漏れに早く気づけるようになりました。
実装より先に設計議論が必要な場面もありますが、少なくとも変更内容を固定したあとにテストを足す流れは崩れにくい設計です。
注意点は、生成されたテストを「合格したから正しい」と見なさないことです。
AIは自分の実装に都合のいいテストを書けます。
期待仕様を文章で渡し、ケースの抜けを人間が補う前提で使うと、品質の底が上がります。
Tip5: バグ調査は再現手順+ログを渡して絞り込み

目的は、推測ではなく事実ベースで候補を狭めることです。
AIに「たぶんここが悪い」と当てさせるより、再現条件、入力値、エラーログ、発生箇所のスタックトレースを渡したほうが、探索の精度が上がります。
操作では、まずChatに再現手順をそのまま貼り、関連しそうなファイルや原因候補を列挙させます。
そのうえで、触るべき範囲が見えたらAgentへ修正を依頼します。
ログの一部だけでなく、「どの操作で」「どの画面で」「どう壊れたか」を短く揃えると、調査が前に進みます。
効く場面は、フロントエンドとバックエンドの境目や、状態管理まわりの不具合です。
私が扱ったケースでも、再現手順をChatへ渡して探索候補を先に出させたあと、Agentに修正を任せるほうが、最初からAgentへ全部投げるより差分の意味が追いやすくなりました。
候補を先に言語化しておくと、「なぜその修正になったのか」をディフから逆算しなくて済みます。
注意点は、ログなしで抽象相談に寄せることです。
「たまに落ちる」「動かない」では、AIも広く探すしかありません。
最低限、再現操作と実際のエラーメッセージをセットにすると、会話が具体化します。
Tip6: コミットメッセージ・PR説明を自動生成
目的は、変更内容の要約にかかる時間を減らしつつ、説明漏れを防ぐことです。
実装後は集中力が切れやすく、コミットメッセージやPR本文が雑になりがちです。
ここをCursorに任せると、最後の事務作業が短くなります。
操作は、差分を見せたうえで「コミットメッセージ案を作成」「PR説明として変更概要、背景、テスト内容、影響範囲を整理」と依頼します。
UIから差分を確認しながら対話できるので、要点を整えた文章をそのままベースにできます。
Conventional Commitsを使っているなら、その形式を明示すると揃います。
効く場面は、複数ファイルにまたがる修正です。
自分では把握しているつもりでも、レビュー側には「何をした変更か」が伝わらないことがあります。
AIに一度要約させると、実装者の頭の中にある前提が外に出ます。
特に、テスト追加やリファクタリングを含むPRでは、変更の種類を分けて記述させると見通しが良くなります。
注意点は、差分を読まずに採用することです。
自動生成文は整って見えても、背景と目的が逆転していることがあります。
コミットとPRの文章は、内容を短くする用途ではなく、レビューの入口を整える用途として使うと噛み合います。
Tip7: Rulesで命名規則・設計方針を永続化
操作としては、UIからルール設定を開き、プロジェクトで優先したい約束ごとを短く記述して登録します。
たとえば「APIレスポンスの型はtypes/配下へ置く」「React コンポーネントの副作用はまとめる」「テスト名は英語で書く」など、頻繁に繰り返す指示を優先して設定すると効果的です。
運用設計は公式の Agent ドキュメントや Rules の説明を参照し、Team/Project レイヤーで一貫性を保つことを意識してください。
注意点は、Rulesに何でも詰め込むことです。
長すぎるルールは参照コストが上がり、何を優先してほしいのかがぼやけます。
設計原則、命名、禁止事項のように、再利用頻度が高いものへ絞ると効きます。
Tip8: 複数モデルを比較して難問を突破する

目的は、1つの回答に詰まったときの打開策を持つことです。
難しいバグ、抽象度の高い設計相談、長い文脈を含む修正では、最初のモデルだけで進めると発想が固定されます。
Cursorはモデル選択の幅があるので、詰まった場面で比較すると前に進みます。
操作では、日常運用はAuto寄りで回し、止まったタスクだけ別モデルで同じ問いを投げます。
『Models & Pricing』を見ると、モデル選択とコストの関係も整理されていますが、運用上は「毎回比較する」のではなく「難所だけ比較する」で十分です。
比較するときは、同じプロンプトで出力を並べると差が見えます。
効く場面は、ひとつ目の回答が表面的なときです。
たとえば、あるモデルは修正パッチに強く、別のモデルは原因分析の言語化に強い、といった差が出ます。
私は、再現のあるバグで一方のモデルが修正案を先に出し、もう一方が前提条件の抜けを指摘してくれたことがありました。
比較の価値は「正解を当てる」より、「見落としていた観点を増やす」点にあります。
比較を常態化すると時間とクレジットの消耗が早くなるため、モデル比較は「詰まった局面だけ」に限定する運用を推奨します。
日常業務は一つの運用に寄せ、必要時のみ別モデルで検証してください。
Models & Pricing | Cursor Docs
Explore all frontier coding models, two usage pools, plan pricing, and per-model API rates.
cursor.comTip9: MCP連携で外部ツールに“目と手”を伸ばす
目的は、コードエディタの中だけでは見えない情報まで扱うことです。
MCPに対応しているため、外部ツールや社内システムとつなぎ、AIが参照できる範囲を広げられます。
Cursor接続の考え方がまとまっています。
操作としては、MCPサーバーを設定し、必要なツールへ接続します。
たとえば、ドキュメント検索、課題管理、社内API仕様、データベース関連の補助情報など、実装の前提になる情報源をつなぐ形です。
UIから接続設定を持ち、どのツールを使わせるかを管理する流れになります。
効く場面は、「コードだけ見ても判断できない」仕事です。
仕様書と実装の差分確認、Issueの記述に沿った修正、社内ナレッジを踏まえた変更提案では、MCPがあると会話の前提がそろいます。
単なるコード補完から一歩進んで、作業文脈そのものを読ませられる点が強みです。
注意点は、接続先を増やしすぎることです。
見える情報が広がるほど便利になりますが、同時に文脈も散ります。
実装で本当に使うツールからつなぎ、役割の薄い接続は足さないほうが、応答の焦点がぶれません。
Cursor Docs
Cursor is the best way to build software with AI.
docs.cursor.comTip10: レビュー前の自己点検チェックリスト化
目的は、レビューで指摘される定番ミスを手前で潰すことです。
AIが生成したコードは、人間の見落としとAI特有の抜けが混ざります。
レビュー前の点検項目を固定すると、品質の波が小さくなります。
操作は、チャットに自己点検用の観点をテンプレートとして持たせることです。
たとえば次のような観点をRulesや定型プロンプトに入れておくと、PR前の確認が短時間で回ります。
- 変更した関数に未使用の引数や不要な分岐が残っていないかを確認する。
- 型定義と実装の戻り値が一致しているかを確認する。
- エラー時の挙動が既存方針と揃っているかを確認する。
- テストが追加・更新されているかを確認する。
- ログ、コメント、命名が変更内容と一致しているかを確認する。
- 関連ファイルの呼び出し更新漏れがないか
効く場面は、急ぎの修正や小さなPRが続くときです。
人間は小さな変更ほど油断し、AIも小さな変更ほど「そこまでは見ない」抜けを残します。
自己点検をチャットに流して差分ベースで確認させると、レビュー前の粗さが減ります。
注意点は、チェックリストを長文化することです。読むだけで疲れる一覧は回りません。レビューで繰り返し出る指摘だけを残しておくと、実務の型として定着します。
💡 Tip
Cursorをうまく回せる人は、プロンプトが上手いというより、Tab補完、Chat、Agent、Rules、テスト、自己点検の役割分担が明確です。1つの機能で全部やろうとせず、作業工程ごとに担当を変えると、差分の意味を追いやすくなります。
Tipsをワークフロー別に使い分けるコツ

機能名だけ覚えても、実務では迷います。
迷いを減らすには、「どの作業を、どの順番で、どの機能から始めるか」を固定すると回りが安定します。
Cursorは単体機能の出来より、Chat、Agent、Tab、Rules、MCPを工程ごとに持ち替えたときに真価が出ると感じています。
実装の場面別にミニ手順へ落として整理します。
新規実装: 雛形生成→補完→周辺更新→テスト
新規実装では、起点をChatに置くとブレが減ります。
いきなりAgentへ丸ごと依頼すると、要件の解釈までAI任せになり、必要以上に広い差分が出やすいからです。
まずはChatで「何を作るか」「既存パターンのどれに合わせるか」「入出力と例外系をどう置くか」を短く詰め、雛形だけ出してもらいます。
雛形ができたら、実装の肉付けはTabを中心に進めます。
関数本体、型、条件分岐、既存ユーティリティの呼び出しは、手で骨格を置きながらTabで埋めるほうが、意図しない抽象化を避けられます。
ここでの基準は、1ファイルの中で責務が閉じているかどうかです。
まだ周辺ファイルへ触らなくてよい段階なら、補完を主役にしたほうが差分の意味を追えます。
本体が固まったあとで、Agentで周辺更新へ進む流れが安定します。
たとえば新しいAPIハンドラを作ったなら、ルーティング定義、型の再エクスポート、利用側の呼び出し、必要なテストファイルの追加までを対象にして、「変更対象はこのディレクトリ配下」「命名は既存のX系に合わせる」のように範囲を絞って渡します。
社内API仕様やIssue情報を参照したい場面では、社内ツールであるMCPをつなぎ、仕様書と実装の食い違いがないかを同時に見せると、後段の手戻りが減ります。
完了判定は、雛形どおりに動くことではなく、周辺更新が漏れていないことまで含みます。
差分確認では、追加した責務に対して変更ファイル数が多すぎないか、逆に呼び出し元や公開インターフェースの更新漏れがないかを見ます。
テスト基準は、新規の振る舞いを1本以上で押さえ、既存機能に波及した箇所の失敗がないことです。
既存コード修正: 影響範囲の見積り→局所→広域
既存コードの修正は、Chatで影響範囲の見積りから始めるのが堅実です。
バグ修正でも仕様変更でも、先に「どの関数が起点で、どの呼び出し経路に波及するか」を言語化しておくと、変更の順番を決めやすくなります。
ここで役立つのがコードベース全体を踏まえた質問で、単一ファイルだけを読むより、依存のつながりを踏まえた整理ができます。
実際の修正は、まず局所です。
対象ファイルか、せいぜい関連ファイル数枚までに絞ってAgentへ依頼し、意図した挙動に変わる最小差分を作らせます。
この段階では広域置換をまだ動かしません。
狭い範囲で修正方針が正しいと確認できてから、同じパターンが残っている場所を広げたほうが、誤った方針を横展開せずに済みます。
局所修正が通ったら、広域の整合は再びAgentで進めます。
たとえば引数名の変更や戻り値の型変更なら、関連コンポーネント、テスト、ドキュメントコメントまで候補を洗い出し、差分を分けて出させると読みやすくなります。
ここでRulesに命名規約や例外処理の方針が入っていると、修正のばらつきが出にくくなります。
完了の基準は、「直った」では足りません。
差分確認では、変更起点のファイルだけでなく、呼び出し側の記法、型の整合、不要になった分岐や引数が残っていないかまで追います。
テスト基準は、修正した不具合を再現するケースが落ちなくなり、その周辺の既存ケースも壊れていないことです。
局所修正のあとに関連テストを回し、広域更新のあとにもう一段広いテストへ広げる、という二段構えが現場では扱いやすい流れです。
デバッグ: 再現→原因仮説→ピンポイント修正

デバッグは、Chatで再現条件を固定するところから始めると進みます。
エラーメッセージ、入力条件、直前の変更、期待値と実際の差を渡して、「まず再現条件を整理して、原因候補を3つに絞る」と頼む形です。
いきなり修正案を求めるより、症状の切り分けを先に行ったほうが、AIの提案も浅い当て推量になりません。
原因仮説の段階では、必要に応じてモデル比較も効きます。
前のセクションで触れた通り、同じ症状でも、あるモデルはスタックトレースの読み解きに強く、別のモデルは状態遷移の破綻を先に見つけることがあります。
私は、再現手順が明確な不具合で複数の見立てを並べたとき、片方が修正パッチを出し、もう片方が「そもそも前提の初期化順が変わっている」と指摘して、真因へ近づいたことがありました。
修正そのものはAgentに任せても、範囲は絞ります。
「この関数と関連テストだけ」「ログ追加と条件分岐の修正だけ」と指定し、まずはピンポイントで差分を作らせます。
外部仕様や監視情報と照合したい不具合なら、社内ツールであるMCP経由でIssueや仕様書を参照させると、再現条件の認識違いを減らせます。
完了判定は、エラーが消えたことではなく、再現ケースで再発しないことです。
差分確認では、デバッグの勢いで関係のないリファクタリングが混ざっていないかを見ます。
テスト基準は、まず不具合の再現テストを追加または更新し、そのケースが通ること、その修正で隣接機能が落ちていないことです。
ログを増やした場合も、恒久的に残すのか一時切り分け用なのかを差分で分けておくと、PR前に迷いません。
リファクタリング: 規約固定→置換→リグレッション抑止
リファクタリングは、Rulesを起点にすると安定します。
ここで命名方針、例外処理の書き方、import順、責務分割の粒度を先に固定しておくと、置換後のコードが部位ごとにぶれません。
私が一番再現性を感じたのもこの流れで、Rulesに命名方針を先に明記し、その前提でAgentにスコープを絞った置換をさせ、テストで安全確認を挟む運びだと、差分が読みやすく、手戻りも少なく収まりました。
実作業では、Agentへいきなり「全部きれいにして」とは投げません。
対象を「このディレクトリ内の命名不統一だけ」「deprecatedな呼び出しの置換だけ」「早期return化だけ」のように限定し、1テーマずつ進めます。
ローカルな書き換えや、その場の書式調整はTabで十分です。
小さな置換を自分の手で入れながら、パターンが固まったらAgentへ広げる順番だと、変換ルールの誤認に早く気づけます。
この場面では、差分確認が作業の中心です。
リファクタリングは見た目が整っても、意味が変わっていたら失敗です。
変数名変更なら参照切れ、抽出ならスコープ、非同期化なら順序、副作用をまとめたなら初期化タイミングを重点的に見ます。
Rulesで規約を固定しておくと、レビュー時に「この命名はどこ基準か」という話が減り、差分の本質だけに集中できます。
テスト基準は、既存の振る舞いが保たれていることです。
単体テストがあるなら先に回し、広い置換では関連する統合テストも加えます。
とくに命名変更や共通化では、テストが緑でもログ文言やエラーメッセージの変更が影響することがあるので、差分上で意図した変更かどうかを分けて見ます。
設計相談: Chatで案出し→比較→小実装で検証

設計相談は、Chatが起点です。
ここで必要なのは、正解を当てることより、案を並べて比較軸を作ることです。
要件、制約、既存構成、捨てたい案まで書いて「案を3つ、採用条件と破綻条件つきで出してほしい」と投げると、議論の材料がそろいます。
抽象的な相談ほど、いきなり実装へ進まず、比較軸を文章で先に固めたほうが後の差分が小さくなります。
比較の段階では、必要なら別モデルでも同じ問いを当てます。
前述の通り、難所だけ比較する運用がちょうどよく、毎回の多重比較は整理コストが勝ちます。
あるモデルが実装現実寄りの案を出し、別のモデルが運用や保守の懸念を先に挙げることがあるので、設計の穴を見つける目的で使うと噛み合います。
案を決め切る前に、Agentで小さな実装を作って確かめるのが有効です。
たとえばインターフェース1つ、最小のユースケース1本、テスト1つだけを作り、依存の置き方や記述量を見ます。
社内ルールや外部仕様が関わるならMCPを通じて前提資料も読ませ、議論だけでなく実装の現実性まで揃えます。
設計は文章だけだと整って見えても、コードに落とすと急に苦しくなることがあるためです。
完了判定は、案がきれいに説明できることではありません。
差分確認では、小実装が当初の設計意図とずれていないか、既存レイヤーへ無理な責務移動が起きていないかを見ます。
テスト基準は、代表ユースケースが最小構成で通ることです。
この小さな検証が通ると、以降の本実装で迷う箇所が減ります。
PR前確認: Lint/テスト/説明生成→差分再点検
PR前は、Agentを起点にした自己点検が効きます。
役割は「提出前の機械的な取りこぼしを潰すこと」です。
まずLint、型チェック、テストの実行対象を明示し、その結果を踏まえて必要な修正だけを入れさせます。
ここを曖昧にすると、修正のついでに別件の変更まで混ざるので、実行コマンドと修正範囲をセットで渡すのが前提です。
そのあとに、ChatでPR説明文を作る流れがきれいです。
変更目的、主要差分、レビューしてほしい観点、テスト内容を箇条書きで下書きさせると、説明と差分のズレを見つけやすくなります。
説明文生成はおまけではなく、差分の棚卸しとして役立ちます。
文章にすると説明できない変更は、たいてい差分の粒度が崩れています。
ここでも差分再点検は外せません。
自動修正後のimport整列、フォーマット変更、ログ文言の揺れ、コメント更新漏れなど、コードが通ってもレビューで止まる点が残るからです。
私は、PR説明をAIに先に書かせたあとで差分を見返すと、「この変更、説明文に入らないのに差分にいる」という行を見つけやすくなります。
その行は、削るべきノイズか、説明不足の本筋かのどちらかです。
💡 Tip
PR前確認の完了は、緑のテストだけでは足りません。変更理由を短く説明できて、差分の各ファイルに存在理由がある状態まで揃うと、レビューの往復が減ります。
テスト基準は、対象変更に対する必須のLint、型チェック、関連テストが通っていることです。
差分確認では、説明できない変更が混ざっていないか、AIが触った周辺ファイルに無関係な整形が入っていないかを見ます。
ここまでを一連の型として持っておくと、Chat、Agent、Tabの役割分担が自然に定着します。
料金・モデル選択・コスト最適化
クレジット制の基本
Cursorの料金理解で先に押さえたいのは、2025年6月以降にクレジットプール制へ移ったことです。
確認日は2026年3月です。
従来の「月に何回まで」という見方よりも、「どのモデルで、どれだけ重い依頼を回したか」で消費が変わる前提に切り替わっています。
この仕組みで誤解しやすいのは、同じ1回の依頼でも負荷が同じではない点です。
短い質問への回答、1ファイルだけの軽い修正、数行の補完は消費が小さく収まりやすく、逆に複数ファイルを横断する編集、長いコンテキストを読ませる依頼、高性能モデルでの推論、複数モデルの比較はクレジットが増えやすくなります。
とくにAgentに大きなリライトを一気に任せると、処理量そのものが増えるうえ、やり直しが入ると同じ範囲をもう一度読ませることになり、体感以上に重くなります。
個人向けの起点としては、Cursor PricingでCursor Proが月額20ドルです。
外部解説では、このProに月額費用相当の20ドル分のクレジットプールが含まれる説明も見られます。
一方で、上位のクレジット増量プランは第三者解説に情報があり、たとえばPro+はProの3倍、Ultraは20倍という整理がありますが、この倍率は記事執筆時点で置けていません。
ここは「増量プランがある」という理解までに留め、厳密な比較は公式表の更新を前提に見るのが自然です。
Auto vs プレミアム固定の判断軸

モデル選択は、日常運用をAutoに寄せ、難所だけプレミアムモデル固定に切り替えると安定します。
Autoはコストと応答の釣り合いを取りやすく、設計相談、方針の壁打ち、小さな修正、既存コードの読解では無駄が出にくい運用です。
毎回モデル名を細かく選ばなくて済むので、普段の開発フローを止めにくいのも利点です。
一方で、広範囲のリライト、依存関係が絡む変更、曖昧な仕様からの実装、失敗時の手戻りコストが大きい作業では、高性能モデルを固定したほうが結果として安く収まる場面があります。
私自身、設計相談の段階ではAutoで案を出し、仕様が固まってから複数ファイルにまたがる書き換えだけ高性能モデル固定に切り替える流れへ寄せてから、途中での指示出し直しが減りました。
最初から高性能モデルで全部回すより、どこで精度が必要かを切り分けたほうが、差分も読みやすくなります。
複数モデルの同時比較は便利ですが、常用すると整理コストとクレジット消費の両方が膨らみます。
比較を入れるなら、設計の分岐点、原因切り分けが難しいバグ、アルゴリズム選定のように「見立てが割れそうな局面」に限ったほうが噛み合います。
普段はAuto、難題だけ固定、高難度タスクで比較は限定的に、という3段階で考えると迷いません。
この判断軸の背景として、『CursorBench』が置いている評価観点も参考になります。
モデル比較は単純な正答率だけではなく、コード品質、効率、対話の進み方まで含めて見るべきだという発想です。
実務でも同じで、1回の回答の賢さだけでなく、余計な変更を混ぜないか、修正の往復が減るか、差分確認の負担が増えないかで見ると、モデル選択が現場の感覚に近づきます。
Pro/Businessの考え方と“事例ベース”の価格感
個人利用の基準線としてわかりやすいのは、Cursor PricingでのPro月額20ドルです。
この金額は、毎日長時間触る開発者だけのものというより、実装、レビュー前の整形、定型修正、設計相談を1か月の中で継続的に回す人向けの起点と考えると納得しやすいのが利点です。
月に数時間でも手作業を置き換えられるなら、開発工数の感覚では十分に回収しやすい水準です。
上位プランの増量クレジットも、考え方は同じです。
個人で高性能モデル固定やAgent中心の運用が増え、月途中で不足が見えるなら増量プランが候補になりますし、チームで重いタスクを継続的に流すならBusiness系のほうが制度設計に合います。
反対に、軽い補完と単発の相談が中心なら、上位へ寄せてもクレジットを余らせやすく、費用の説明がつきません。
プラン選びは「何人で使うか」だけでなく、「どの重さのタスクを、どの頻度で回すか」で見ると整理できます。
コストを抑える依頼・文脈設計テクニック
クレジット消費を抑えるいちばん効く方法は、モデルを我慢することより、依頼のスコープを削ることです。
Agentに広い範囲を読ませるほど、処理対象も修正候補も増えます。
そこで有効なのが、タスク分割、差分スコープの明示、不要ファイルの除外です。
前のセクションでも触れた通り、1テーマずつ切るだけで差分の質が上がり、結果として再実行も減ります。
たとえば「認証周りを整理して」ではなく、「auth/配下のdeprecatedな呼び出しだけを新APIへ置換し、公開インターフェース名は維持する」と書くと、読む範囲も編集範囲も絞れます。
さらに「変更対象は3ファイル」「テストは既存の認証系だけ」「命名変更はしない」と条件を足すと、余計な提案が減ります。
クレジット制では、この“余計な提案を出させない設計”そのものが節約になります。
差分ベースで依頼するのも効きます。
前回の提案結果を丸ごと再説明するより、「前回の変更案のうち、この関数だけ残して他は戻したい」「このテスト失敗だけ直したい」と差分で指示したほうが、文脈が短く済みます。
実務では、1回で正解を引くより、狭い範囲で何度か刻んだほうが総消費が軽くなる場面が多いです。
コンテキストの絞り込みも見逃せません。
関係ないログ、生成物、巨大なドキュメント、古い移行ファイルまで読ませると、それだけで重くなります。
.cursorignoreで除外すべきものを先に分けておくと、秘密情報の混入防止だけでなく、読ませる文脈の密度も上がります。
必要ファイルだけを与えたほうが、モデルは「どこを触るべきか」を誤読しにくく、結果として修正の往復が減ります。
短い依頼でも精度を落とさないコツは、ゴール、制約、完了条件の3点を最初に固定することです。
たとえば「目的はN+1解消」「SQLの意味は変えない」「関連テストが通ることを完了条件にする」といった書き方です。
文字数を増やすのではなく、判断材料を先頭に圧縮して置く感覚です。
これができると、Autoで十分な作業と、高性能モデル固定へ上げるべき作業の境目も見えやすくなります。
💡 Tip
コスト最適化は「安いモデルだけを使う」ことではありません。軽い相談はAuto、やり直しコストが高い局面は高性能モデル固定、その前提として依頼範囲を狭く切る。この順番で整えると、消費量と差分品質の両方が落ち着きます。
セキュリティとチーム導入時の注意点

Privacy Modeと.cursorignoreの違い
Cursorを業務導入するときに最初に整理しておきたいのは、Privacy Modeと.cursorignoreが同じ役割ではない、という点です。
ここを混同すると、「設定したつもりなのに守りたいものが守れていない」という状態が起こります。
Privacy Modeは、コードを保存や学習に使わせないための設定です。
たとえば『。
ただし、ここで止めて理解すると不十分です。
Privacy Modeを有効にしても、モデルへ処理を依頼するための通信そのものが消えるわけではありません。
つまり、「学習に使わせない」と「どの情報を送るか」は別の論点です。
その別の論点を担うのが.cursorignoreです。
こちらは、AIに渡すコンテキストから特定ファイルや特定ディレクトリを外すための仕組みです。
たとえば .env、証明書、顧客データのダンプ、社内設計メモ、巨大なログ、生成物のように、送る理由が薄いものは最初から外しておくほうが筋が通ります。
前のセクションで触れた通り、これは秘密情報の保護だけでなく、余計な文脈を減らして差分の質を安定させる意味もあります。
私自身、チームでPrivacy Modeを強制しつつ、.cursorignore のテンプレートをリポジトリに同梱した運用にしてから、AI支援を使うときの心理的な抵抗が目に見えて減りました。
各自が毎回「これは送ってよかったか」を判断する運用だと、使う人ほど不安を抱えます。
最初から node_modules やビルド成果物だけでなく、Secrets系ファイルや顧客向けエクスポートを除外する雛形を置いておくと、導入時の説明も短く済みますし、レビュー側も設定の前提を共有できます。
要するに、Privacy Modeは「送った後の扱い」を制御し、.cursorignoreは「そもそも送る候補に入れるか」を制御します。
両方を入れて初めて、実務で求められるガードレールになります。

Cursor における各プランのPrivacy Modeとデータ保護について - サーバーワークスエンジニアブログ
はじめに 生成 AI 統合 IDE「Cursor」は VS Code をベースに、ChatGPT や Claude など複数モデルを扱える統合開発環境です。一方、利用時にソースコードやプロンプトがクラウドに送信されるため、どのプランでどこま
blog.serverworks.co.jpデータ流通とサブプロセッサの考え方
チーム導入で不安になりやすいのは、「結局どこまでデータが流れるのか」という点です。
Cursorは単体で閉じるというより、外部モデルや関連サービスと連携して価値を出すツールです。
そのため、サブプロセッサ通信という発想を前提に置いたほうが、現実の運用に合います。
ここでの実務的な見方はシンプルで、AIへの依頼文、添付したコード断片、参照されたファイル内容、MCP経由で取得した情報は、処理のために外部へ渡る可能性があるものとして扱う、ということです。
Privacy Modeが有効でも、前述の通り通信自体は発生します。
したがって、社内ポリシーは「学習に使わせない設定を入れているから安心」で終わらせず、「何を送ってよいか」「何は送ってはいけないか」を明文化する必要があります。
現場では、Secrets、個人情報、契約未公開情報、顧客識別子を含むログの扱いを先に決めておくと、議論が空中戦になりません。
たとえばAPIキーは貼り付け禁止、個人情報を含む実データは要マスキング、本番障害ログは識別子を伏せてから共有、外部モデルに送るのは再現に必要な最小断片だけ、といったルールです。
抽象論として「機密に注意」と書くだけでは現場は動かず、送信単位で線を引くと運用に落ちます。
CursorのMCPサーバー機能を使う場合は、このデータ流通がさらに広がります。
モデルだけでなく接続先のサーバーやその先の内部システムも関係してきます。
つまり、AIの利用可否だけではなく、「どのMCPサーバーが何に接続できるか」「取得した情報をどこまでログに残すか」まで含めて設計しないと、チーム運用としては片手落ちです。
MCP設定を“コード化された運用”としてレビューする

MCPを導入すると、AIは単なる補完ツールではなく、外部の知識源や社内システムに触れる入口になります。
だからこそ、MCP設定ファイルは便利設定ではなく、TerraformやCI設定と同じく“コード化された運用”として扱ったほうが安全です。
実務で見るべきポイントは、接続先、認証情報の扱い、許可された操作範囲、ログ出力先の4つです。
たとえば、社内ドキュメント検索だけのつもりで入れたMCPサーバーが、実は更新系APIにも届く状態だと、レビューの前提が崩れます。
ローカル実行の補助ツールなのか、社内SaaSに読み取り接続するのか、書き込み権限まで持つのかで、リスクの種類は変わります。
このとき有効なのが、MCP設定ファイルをアプリコードと同じリポジトリ管理に乗せ、Pull Requestでレビューする運用です。
誰がどのサーバーを追加したのか、どのエンドポイントに向けたのか、認証は環境変数参照なのか、ログにリクエスト本文を残すのか、といった論点が差分として見えるようになります。
設定がローカル各自の手元だけに散ると、便利な裏で権限の実態が見えなくなります。
インフラ設定と同じ目線で扱うなら、レビュー観点も書き下せます。
接続先ドメインは承認済みか、読み取り専用か、Secretsを設定ファイルへ直書きしていないか、監査ログに機密が混ざらないか、障害時に切り離せるか、といった項目です。
MCPは拡張性が高い反面、設定がそのまま運用ポリシーになります。
コードレビューの対象に入れる、というより、最初から運用コードそのものとして見たほうがズレません。
ℹ️ Note
MCP設定は「便利だから各自で足す」運用にすると、接続先と権限の棚卸しができなくなります。チームで使うなら、追加時のレビュー項目まで含めて共有しておくと、後から統制を戻す手間を減らせます。
Team/Project Rulesでガバナンスを回す
セキュリティ運用を個人の注意力だけに寄せると、導入人数が増えた瞬間に崩れます。
そこで効くのが、CursorのRulesを使って、ガバナンスをTeam層とProject層に分けて持たせる考え方です。
『。
Team Rulesには、組織横断で変えたくない原則を置くのが自然です。
たとえば、Secretsを貼り付けない、個人情報を含む実データは使わない、外部送信前にマスキングする、MCP追加時はレビュー必須、といった項目です。
これはセキュリティポリシーの簡略版をAI利用文脈に翻訳したもの、と考えると運用しやすくなります。
Project Rulesには、そのリポジトリ固有の命名規則、禁止ライブラリ、レビュー観点、テスト前提、変更禁止領域を置きます。
たとえば「db/migrations はAgentに自動編集させない」「公開API名は互換性維持」「Reactコンポーネントは既存の命名規則を踏襲」「生成コードは必ず人間が差分確認する」といった内容です。
ここまで具体化すると、単なるお願いではなく、AIに対する一貫した制約として機能します。
チーム導入で効いたのは、このRulesを教育資料ではなく共有資産として置くことでした。
口頭説明だけだと、入社時期や経験差で認識がずれます。
Team Rulesで会社としての線引きを揃え、Project Rulesでリポジトリごとの事情を足す形にすると、レビューの観点も自然に揃います。
結果として、「この差分は何が問題か」を人ごとの感覚ではなく、ルールに沿って話せるようになります。
命名規則やレビュー観点までRulesへ載せると、セキュリティだけでなく品質面のばらつきも抑えられます。
AI導入のガバナンスは、禁止事項を増やすことより、許可された振る舞いを共有可能な形で固定することに価値があります。
Privacy Modeや.cursorignoreで土台を作り、MCP設定をレビュー対象にし、その上にTeam/Project Rulesを重ねると、チーム全体で安心して使える運用に近づきます。
Rules | Cursor Docs
Configure persistent instructions with Project, Team, and User Rules, plus AGENTS.md. Learn best practices for effective
cursor.comよくあるつまずきと対処法
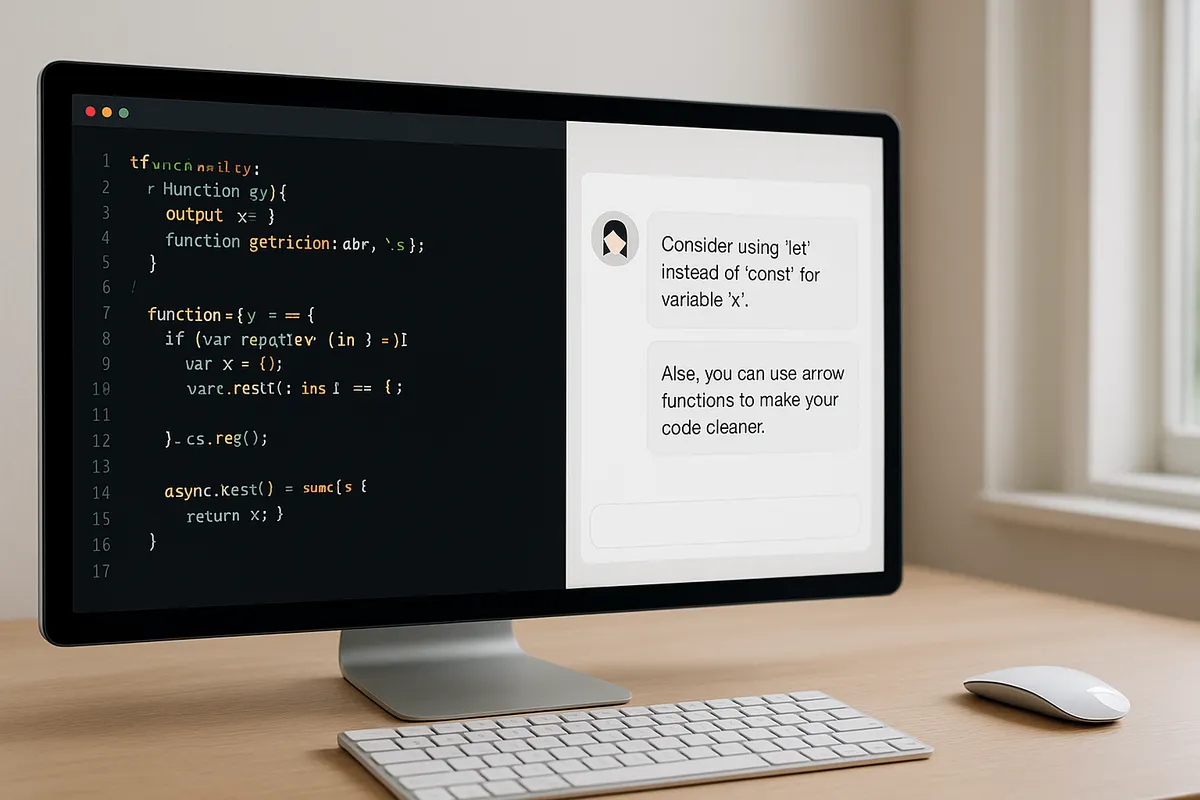
依頼の分割と差分確認をデフォルトにする
初心者が最初につまずきやすいのは、Agentに作業をまとめて渡しすぎることです。
CursorのAgentは複数ファイル編集やコマンド実行まで進められますが、その強みは「大きな曖昧依頼」と相性がいいという意味ではありません。
実際、私も使い始めのころは「この不具合まわりをまとめて直して」と投げがちでした。
すると関係ない補助関数まで触り、テストの前提もずれ、差分レビューの負担だけが増える流れになりやすかったです。
ここで効いたのが、依頼をファイル単位か責務単位まで小さく切ることでした。
たとえば「まずapi/client.tsだけで型エラーを解消する」「次にUserForm.tsxのバリデーションだけ直す」「最後に既存テストを通し、新規ケースが必要なら1件だけ追加する」といった形です。
先にテスト基準も置いておくと、AIの出力を“雰囲気で採用する”流れが止まり、再作業が目に見えて減ります。
Cursor目標を明確にし、小さく区切って進める考え方が示されています。
実務では、まず修正プランだけ出させて、その差分案を人間が見てから実行に進める二段階運用が安定します。
いきなり編集させるより、「どのファイルを触るか」「変更しない場所はどこか」「成功条件は何か」を言語化させたほうが、意図外の変更が混ざったときも止めどころがはっきりします。
AIに丸投げして破綻するケースの多くは、モデルの賢さ不足というより、作業単位と評価基準が粗いことが原因です。
Chatで方針を詰め、Agentには限定された実装を任せる、という役割分担にするだけでも、差分の読みやすさが変わります。
文脈のダイエット
AIは文脈をたくさん渡すほど賢くなる、と思われがちですが、実務では逆にノイズが増える場面が少なくありません。
関係の薄いログ、生成物、古い仕様メモ、巨大なdistやcoverageまで読ませると、必要な制約より周辺情報を拾ってしまい、回答が鈍ったり、論点がぼやけたりします。
この詰まり方は、Cursorを導入した直後に起きやすいのが利点です。
リポジトリ全体を見られるのが便利なので、何も整理せずに全部読ませたくなりますが、そこで効くのが.cursorignoreです。
ビルド生成物、ベンダー配下、検証用の一時ファイル、機密設定ファイルのように今回の依頼へ不要なものを除外すると、AIが拾う前提が引き締まります。
プロンプト側も長文で事情を全部説明するより、「対象ファイル」「直したい症状」「守るべき制約」の3点に絞ったほうが、返ってくる提案の精度が上がります。
文脈のダイエットは、単なる軽量化ではありません。
AIに何を読ませないかを決める作業でもあります。
たとえば、Reactのフォーム不具合を直したいのに、過去の設計議事録や別機能の実験コードまで含めると、現在の正解より過去の迷走を参照し始めることがあります。
必要な情報を減らすというより、不要な連想経路を切る感覚に近いです。
Rules未設定のまま運用すると、この問題はさらに出やすくなります。
毎回プロンプトで命名規則やテスト方針を書き足す運用だと、ある回では伝わり、別の回では抜け落ちます。
だからこそ、横断的に守りたい前提は『Rules』へ固定し、都度プロンプトでは今回の差分に必要な事情だけを書く構成が安定します。
モデル/コストの見立てを先に置く

もうひとつ見落とされがちなのが、タスクの難しさとモデル選択を切り分けずに進めてしまうことです。
高性能モデルを常時固定すれば安心に見えますが、2025年以降のCursorはクレジット制へ移っており、使いどころを分けないとコストの見通しが崩れます。
Cursor公式の『Models & Pricing』や『Cursor Pricing』で示されている通り、Cursor Proは公式サイトで月額$20が起点です。
個人利用ならこの価格でも、日常の軽作業まで高性能固定にすると、節約できる時間に対して支払いが先に膨らむ傾向があります。
日々の補完、軽い質問、単一ファイルの修正ならAutoに寄せ、設計変更、複数ファイルの横断修正、詰まったデバッグだけ高性能モデルに固定する運用のほうが筋が通ります。
比較したい場面でも、複数モデルを毎回並走させるのではなく、「このバグ原因の切り分けだけ」「このリファクタ方針だけ」と限定回数で検証したほうが、コストと精度の両方を把握しやすくなります。
モデル選択ミスで起きるのは、単にお金の問題だけではありません。
軽い依頼に重いモデルを当て続けると、待ち時間に対して得られる差分が小さく感じられ、逆に難所でAutoのまま粘ると「AIが役に立たない」という誤解につながります。
実際には、タスクの粒度とモデルの得意領域が噛み合っていないだけ、ということが多いです。
感覚としては、月額$20のCursor Proでも、定型修正や調査の往復を月に数時間でも削れれば元は取りやすい部類です。
だからこそ、節約の対象になる作業を見極めず、常時フル装備で使うより、普段はAuto、難所だけプレミアムという配分のほうが、費用対効果を読み違えにくくなります。
Rules・MCPの“増やしすぎ”に注意
運用が進むと、今度は設定を盛り込みすぎる方向で詰まることがあります。
典型例は、Rulesを細かく書きすぎて矛盾を抱えるケースと、MCPサーバーを便利そうという理由で増やしすぎるケースです。
どちらも最初は安心材料に見えますが、実際には判断経路を増やし、レビュー対象も広げます。
Rules未設定のままでは一貫性が崩れますが、逆に何十項目も詰め込むと、AIにとっても人間にとっても「どれが優先なのか」が見えにくくなります。
まず固定したいのは、命名規則、テスト方針、変更禁止領域、レビュー時の最低条件くらいです。
たとえば「公開APIの命名は既存規約に合わせる」「修正時は既存テストを壊さない」「マイグレーションは自動編集対象から外す」といった、差分の判断に直結するものを先に置くと、プロジェクト横断でもぶれにくくなります。
MCPも同じで、接続先が増えるほどAIの行動半径が広がります。
社内ドキュメント検索、Issue参照、DB操作補助、外部SaaS連携を一気に足したくなりますが、それぞれ権限と必要性のレビューが要ります。
読み取り専用で足りるのか、書き込みが本当に必要か、日常的に使うのか、限定された保守作業でしか使わないのか。
この整理を飛ばして増設すると、便利さより統制コストが先に立ちます。
💡 Tip
RulesもMCPも、「足りないから足す」より「毎週使うか」で選別したほうが運用が安定します。常用しない設定は、存在するだけで判断材料とレビュー項目を増やします。
MCPを増やしすぎるケースでは、AIが賢くなるというより、外部への入口が増えるだけになりがちです。
最小主義で始め、使う理由が説明できるものだけ残す構成のほうが、チーム導入でも個人利用でも長く持ちます。
Rulesは少数精鋭、MCPは必要最小限。
この形にしておくと、AIの振る舞いも差分レビューの観点も揃いやすく、初心者が最初にぶつかる混乱を避けやすくなります。
まとめ

Cursorは、Chat・Tab補完・Agent・Rules/MCPという4系統を役割で切り分けると、急に手になじみます。
効くのは機能の多さではなく、タスクを小さくして順番に当てる運用です。
コストとセキュリティの前提を先に決めておくと、便利さだけが先走る状態も避けられます。
今日から始める3アクション
まずはQuickstartの流れで、開いているコードの説明をChatにさせてください。
次にPrivacy Modeを有効にし、.cursorignoreで触らせない範囲を決めます。
そのうえで小タスクをTab補完で片づけ、まとまった変更だけAgentに渡し、PR前にテスト生成と自己点検まで回す形が入口として安定します。
私も朝イチに「今日触る範囲」をChatで要約し、小さく切った作業をAgentに任せ、PR前に自分で差分を見直す流れにしてから、無駄な往復が減りました。
このTipsが向いている人/次の一手
相性がいいのは、個人開発者やWebエンジニアとして実装速度を上げたい人、そしてチーム導入前に論点を絞りたい担当者です。
次に触る設定は、命名規則とテスト方針だけを入れた最小のRulesと、読み取り中心の最小構成MCPです。
設定を盛るより、毎週使うものだけ残したほうが運用は整います。
このサイトには現時点で関連記事がないため、内部リンクは用意していません。導入前の最新情報や料金の公式表記は、以下の公式ページで必ず確認してください。
- Cursor Pricing
- Cursor Docs
AIビルダーの編集チームです。AI開発ツールの最新情報と使い方を発信しています。
関連記事
バイブコーディングとは?始め方とおすすめツール3選
バイブコーディングとは?始め方とおすすめツール3選
バイブコーディングは、2025年2月にAndrej Karpathyが提唱した、自然言語でAIに意図を伝えながらコードを書かせる開発スタイルです。人が「こう動いてほしい」と言葉にし、AIがコードを生成し、人はそれを確かめて直していく。この流れなら、プログラミング未経験でも小さなアプリから形にできるでしょう。
Cursor Agent Modeの使い方|Ask/Plan/Agentの違いと使い分け
Cursor Agent Modeの使い方|Ask/Plan/Agentの違いと使い分け
Cursorのチャットは、Ask・Plan・Agentの3モードを使い分ける設計で、デフォルトはAgentです。Askはコードを変更せずに読み取りだけを行い、Planは調査結果をもとに計画書を作るだけ、Agentは複数ファイルの編集やコマンド実行まで進めます。
MCP自動化パターン10選|導入順と最小手順
MCP自動化パターン10選|導入順と最小手順
筆者の試用では、Jira と Notion を横断して要約する流れを組むと、毎朝の状況把握にかかる時間が短く感じられ、概ね2〜3分程度で済むことがありました。これはあくまで筆者の環境での体験値であり、環境や設定によって大きく変わります。一般化して示す場合は、社内PoCや計測ログなどの出典を併記してください。
Cursor ComposerとAutomationsの違い
Cursor ComposerとAutomationsの違い
Composerは人がCursorのIDE内で対話しながら実装を前に進める高速ループで、Automationsはイベントやスケジュールを起点にクラウドで回り続ける運用ループです。この前提を押さえるだけで、両者を「似たAI機能」とひとまとめにして迷う状態から抜け出せます。